基础知识
想要学习并发,必须首先对线程有一定的知识基础,因此强烈建议先复习一下这部分知识:
在 Java 基础笔记中,对于 Java 线程有一定的说明:
https://uesugier11.gitee.io/uesugi-er11/2020/11/14/Java%E5%9F%BA%E7%A1%80/#%E7%BA%BF%E7%A8%8B
如果想在 OS 层面学习进程线程,在 OS 笔记中,对这部分有一定的说明:
对于进程的调度,死锁的相关知识:
Java 并发 - 核心理论
- Java 异步核心原理分为五个基本性质:共享性、互斥性、原子性、可见性、有序性
共享性
如果所有数据都是线程私有的,那编程的时候就无须考虑并发的情况了 —— 因为无论怎么操作,数据都可以保证正确,不会被其他线程访问。因此,数据具有共享性,是线程安全得不到保证的主要原因之一。那如何保证线程安全(数据一致性)呢,就得引入进程同步。
互斥性
资源互斥是指同时只允许一个访问者对其进行访问,具有唯一性和排它性。
对于数据,我们可以进行读(查看)和写(修改)的操作,则我们应该对执行读写操作的线程分别有不同的限制,因此衍生了两种锁
共享锁(读锁/S 锁):共享 (S) 用于不更改或不更新数据的操作(只读操作),如 SELECT 语句。
如果事务 T 对数据 A 加上共享锁后,则其他事务只能对 A 再加共享锁,不能加排他锁。获准共享锁的事务只能读数据,不能修改数据。
排它锁(写锁/X 锁):用于数据修改操作,例如 INSERT、UPDATE 或 DELETE。确保不会同时同一资源进行多重更新。
如果事务 T 对数据 A 加上排他锁后,则其他事务不能再对 A 加任任何类型的封锁。获准排他锁的事务既能读数据,又能修改数据。
Java 中的保证数据安全性,实现互斥的方法有许多(比如 synchronized,类似于操作系统中的管程机制)
原子性
操作系统中与原子性关系最贴切的应该是原语:
原子性就是指对数据的操作是一个独立的、不可分割的整体。换句话说,就是一次操作,是一个连续不可中断的过程,数据不会执行的一半的时候被其他线程所修改;
列举个例子来体现原子性:i++ 这个操作,1)读取整数 i 的值;(2)对 i 进行加一操作;(3)将结果写回内存。
但却可能在多线程场景发生以下情况:
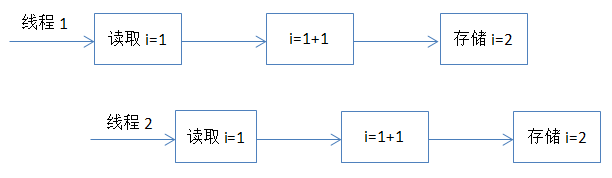
保证原子性(即不会被其他操作打断)的方法可以通过上锁去实现:Synchronized或Lock,或者是使用CAS:修改数据之前先比较与之前读取到的值是否一致,如果一致,则进行修改,如果不一致则重新执行(乐观锁)。但 CAS 在某些场景下不一定有效,比如另一线程先修改了某个值,然后再改回原来值,这种情况下,CAS 是无法判断的。
可见性
关于可见性问题的解释:
- 可见性:一个线程对共享变量的修改,更够及时的被其他线程看到
可见性概念建立在 JVM 的内存模型上:
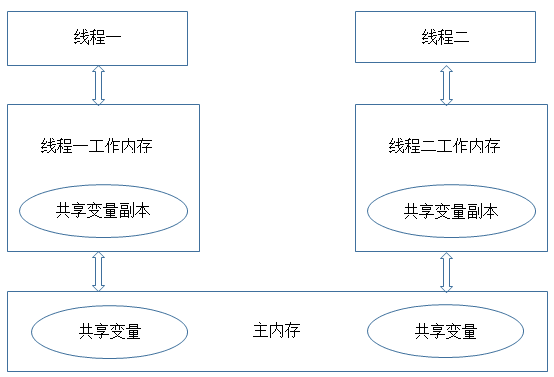
在 JVM 内部,为了提高效率,同时运行的每个线程都会有它正在处理的数据的缓存副本,当我们使用 synchronzied 进行同步的时候,真正被同步的是在不同线程中表示被锁定对象的内存块(副本数据会保持和主内存的同步)
简单的说就是在同步块或同步方法执行完后,对被锁定的对象做的任何修改要在释放锁之前写回到主内存中;在进入同步块得到锁之后,被锁定对象的数据是从主内存中读出来的,持有锁的线程的数据副本一定和主内存中的数据视图是同步的
但有可能会出现这么一个问题:假如主内存的更新(通知)不及时,会导致一个线程 A 明明更新了数据,但线程 B 得到的还是原来的数据的问题。
解决这个问题可以使用:volatile和synchronized关键字进行解决。
有序性
有序性部分与进程的前驱问题有点类似:
为了提高性能,编译器和处理器可能会对指令做重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。重排序相关内容
Java 中也可通过Synchronized或·Volatile来保证顺序性。
Java 内存模型
前言
内存模型通过限制处理器优化和使用内存屏障,来保证共享内存的正确性(可见性、有序性、原子性)
Java 内存模型(Java Memory Model ,JMM)就是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了 Java 程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
JMM 还通过volatile、synchronized、final、concurren包等实现原子性、有序性、可见性。
而由于进程之间进行通信,数据进行同步,都依靠这个 JMM。因此学习它就显得尤为重要了。
关于进程通信:
关于进程同步:
并发编程模型基础
在并发编程中,需要了解并会处理这两个关键问题:
线程之间如何通信
通信是指线程之间以何种机制来交换信息。在命令式编程中,线程之间的通信机制有两种:共享内存和消息传递。
a) 在共享内存的并发模型里,线程之间共享程序的公共状态,通过写-读内存中的公共状态进行隐式通信。(重点)
b) 在消息传递的并发模型里,线程之间没有公共状态,线程之间必须通过发送消息来显式进行通信。
线程之间如何同步
同步是指程序中用于控制不同线程间操作发生相对顺序的机制。
在共享内存的并发模型里,同步是显示进行的。因为程序员必须显式指定某个方法或某段代码需要在线程之间互斥执行。
在消息传递的并发模型里,由于消息的发送必须在消息的接收之前,因此同步是隐式进行的。
知道并了解上面两个问题后,对 java 内存模型的了解,就打下了基础。因为 Java 的并发模型采用的是共享内存模型,java 线程之间的通信总是隐式进行,整个通信过程对程序员完全透明。
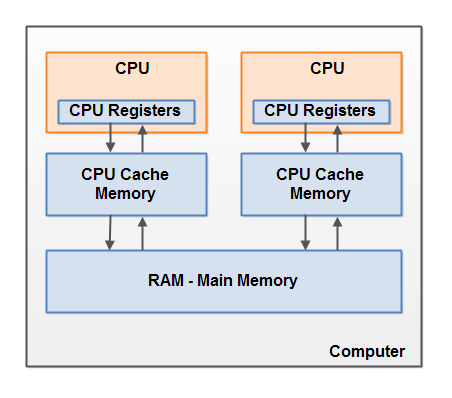
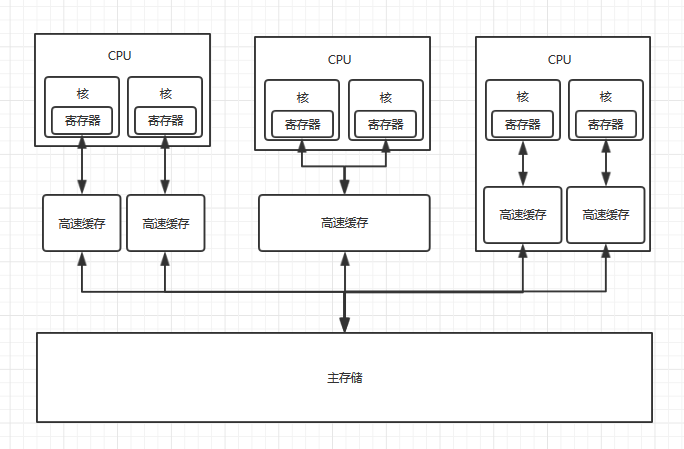
硬件内存模型
- 概述
如图:硬件内存模型由CPU - 缓存 - 主存储三层结构组成
现代计算机通常有 2 个或以上的 CPU,单个 CPU 可能有多个内核。每个 CPU 内核中都包含一组寄存器,CPU 在寄存器中执行操作比在计算机主存储器中快的多
每个 CPU 之上还存在高速缓存,但高速缓存的层级和位置是不固定的,缓存的位置也各有不同,有的集成了部分缓存到 CPU 中。 同样,缓存的读写速度也大大快于计算机主存储器。
- 什么时候需要用到缓存呢?
CPU 在程序的执行过程中,经常会频繁的调用相同的数据,比如在一个循环内调用了位于另外一个物理地址的函数,这个函数可能与当前指令的物理位置相距甚远,因为程序使用的物理内存并不是连续的,这就导致了需要花费很多不必要的时间在物理寻址上。但如果在 CPU 计算之前会将所需要用到的数据先读到缓存中,计算完成之后再一次性写入计算机主存储器,就可以避免频繁访问计算机主存储器造成的资源浪费。
JMM(Java Memory Model)
在 Java 中,所有实例域、静态域和数组元素都存储在堆内存中, 而堆内存在线程之间是共享的
而虚拟机栈(其中包括局部变量、方法参数定义等..)是线程私有的,不会在线程之间共享,所以它们不会有内存可见性的问题,也不受内存模型的影响。
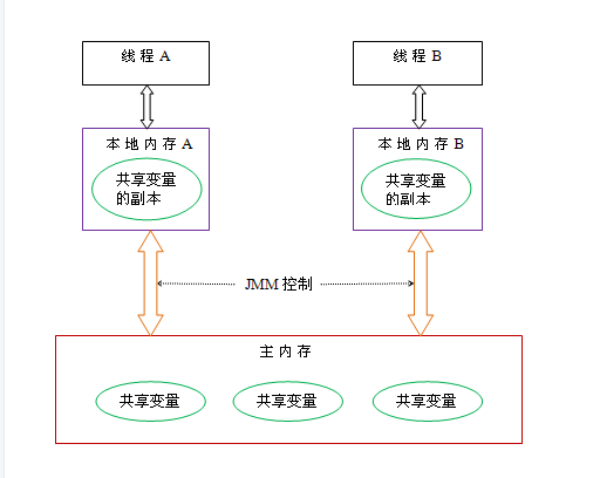
线程与主内存间的抽象关系
线程之间的共享变量存储在主内存(Main memory)中
每个线程都有一个私有的本地内存(local memory)或者说是工作内存(Working Memory),本地内存中存储了该线程用以读/写共享变量的副本。
线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的变量(volatile 变量仍然有工作内存的拷贝,但是由于它特殊的操作顺序性规定,所以看起来如同直接在主内存中读写访问一般)。不同的线程之间也无法直接访问对方工作内存中的变量,线程之间值的传递都需要通过主内存来完成。
本地内存是 JMM 的一个抽象概念,并不真实存在。它涵盖了缓存,写缓冲区,寄存器以及其他的硬件和编译器优化。线程对共享变量的操作并不会直接访问主内存,而是访问一个中间层,这个中间层包含了主内存中变量的拷贝,同时中间层的访问速度大大快于访问主内存的速度,在一定的操作之后将结果统一写回主内存,这样就大大提高了程序的性能
(同时也会产生另外一个问题,同一个共享变量在每一个线程之中都会有一份拷贝(对引用类型,并不是拷贝全部数据),产生的线程越多,缓存开销也就越大。)
线程通信问题
上图中,线程 A 与 B 想要进行通信(数据交互)的话,要经历:
- 线程 A 把本地内存 A中更新过的共享变量刷新到主内存中去。
- 线程 B 到主内存中去读取线程 A 之前已更新过的共享变量,接着复制一份到本地内存 B中
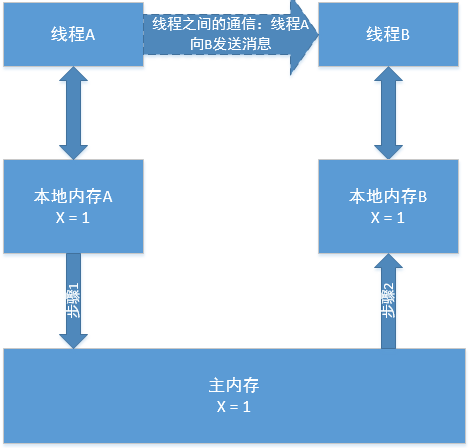
假设初始时,这三个内存中 x 的值都为 0,线程 A 在执行时,把更新后的 x 值临时放在本地内存。当线程 A 与线程 B 需要通信时,
步骤 1:线程 A 首先会把自己本地内存中修改后的 x 值刷新到主内存中,此时主内存中的 x 值变为了 1。
步骤 2:线程 B 到主内存中读取线程 A 更新后的 X 值,此时线程 B 的本地内存 x 的值也变为了 1。
从整体(不考虑重排序,按顺序执行)来看,这两个步骤实质上是线程 A在向线程 B发送消息,而从整体(不考虑重排序,按顺序执行)来看,这两个步骤实质上是线程 A 在向线程 B 发送消息,而且这个通信过程必须要经过主内存。JMM 通过控制主内存与每个线程的本地内存之间的交互,提供内存可见性的保证。
重排序
- 重排序分为三种
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism, ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。

- 为什么会发生重排序
为什么会重排序,上面这几个阶段里大概提到了,提高并行效率,编译器认为重排序后执行更优,指令级重排序并行效率更好等等。在单个线程的视角看来,重排序不存在任何问题,重排序不改变执行结果
对于语句:int a = 1;int b = 2;int c = a + b;
首先需要明白:重排序的发生前提是具有数据依赖,什么意思呢?int a = 1;int b = a; b 的数据依赖于 a,那么这两个语句就不会被重排序,a 一定会在 b 语句前执行;
c 因为对 a 和 b 有数据依赖,因此 c 不会被重排序,但是 a 、b 的执行可能被重排序。但在单个线程下,这种重排序不存在任何问题,不论先初始化 a、还是先初始化 b,c 的值都是 3
- 重排序带来的问题
然而重排序可能会导致多线程出现内存可见性的问题,比如:处理器在对内存进行读写操作未必与实际发生的内存读写顺序一致,导致重排序 → 引发了可见性问题(数据更新不及时)
在这我们不举例处理器的例子,我们还是以代码为例:
现在有两个线程
线程 T1:
1
2a = 1; //共享变量
int b = true; //共享变量 boolean b线程 T2:
1
2
3
4if (b){
int c = a;
System.out.println(c);
}
我们默认 b 的值是线程 T2 可读取的,假如 b 为true,c 一定为 1 吗?(在并发环境中)
按照我们上面的学习,a 与 b 是没有数据依赖关系的,因此运行的顺序的可以被重排序的。假如此时 b 先与 a 执行,虽然对 T1 没什么影响,但是对 T2 就不一样了。T2 可能一直在进行这个 if 的测试,突然间发现 b 为 true 了,而 a 还没来得及被赋值呢,就进入了 T2 的 if 语句中,则此时的 c 就读不到 a 的值(1)了。
当代码中存在控制依赖的时候,会影响指令序列执行的并行度。为此,编译器和处理器会采用
猜测执行来克服控制相关性对并行度的影响。比如可以提前读取变量,计算,将计算结果临时保存起来,当条件为真的时候,把临时变量写入真的变量中。这个猜测执行其实就是对指令进行了重排序,此处的重排序是破坏了多线程程序的语义的。
happens-before - 重点
概述

- JMM 把 happens- before 要求禁止的重排序分为了下面两类:
会改变程序执行结果的重排序,JMM 要求编译器和处理器必须禁止这种重排序。
不会改变程序执行结果的重排序,JMM 对编译器和处理器不作要求(JMM允许这种重排序)。
只要不改变程序的执行结果(指的是单线程程序和正确同步的多线程程序),编译器和处理器怎么优化都行。
比如,如果编译器经过细致的分析后,认定一个锁只会被单个线程访问,那么这个锁可以被消除。
再比如,如果编译器经过细致的分析后,认定一个 volatile 变量仅仅只会被单个线程访问,那么编译器可以把这个 volatile 变量当作一个普通变量来对待。
这些优化既不会改变程序的执行结果,又能提高程序的执行效率。
原则
- happens-before 原则定义
- 如果一个操作 happens-before 另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。 关于可见性
- 两个操作之间存在 happens-before 关系,并不意味着一定要按照 happens-before 原则制定的顺序来执行。如果重排序之后的执行结果与按照 happens-before 关系来执行的结果一致,那么这种重排序并不非法。
规则
- happens-before 规则
程序次序规则:一个线程内,按照代码顺序,书写在前面的操作先行发生于书写在后面的操作;
一段代码在单线程中执行的结果是有序的。注意是执行结果,因为虚拟机、处理器会对指令进行重排序(重排序后面会详细介绍)。虽然重排序了,但是并不会影响程序的执行结果,所以程序最终执行的结果与顺序执行的结果是一致的。故而这个规则只对【单线程】有效,在【多线程】环境下无法保证正确性。
锁定规则:一个 unLock 操作先行发生于后面对同一个锁的 Lock 操作
这个规则比较好理解,无论是在单线程环境还是多线程环境,一个锁处于被锁定状态,那么必须先执行 unlock 操作后面才能进行 lock 操作。
volatile 变量规则:对一个 volatile 变量的写操作先行发生于后面(时间上)对这个变量的读操作
这是一条比较重要的规则,它标志着 volatile 保证了线程可见性。通俗点讲就是如果一个线程先去写一个 volatile 变量,然后一个线程去读这个变量,那么这个写操作一定是 happens-before(先行)于读操作的。
传递规则:如果操作 A 先行发生于操作 B,而操作 B 又先行发生于操作 C,则可以得出操作 A 先行发生于操作 C;
提现了 happens-before 原则具有传递性,即 A happens-before B , B happens-before C,那么 A happens-before C
线程
启动规则:Thread 对象的
start()方法先行发生于此线程的每个一个动作;假定线程 A 在执行过程中,通过执行 ThreadB.start()来启动线程 B,那么线程 A 对共享变量的修改在接下来线程 B 开始执行后确保对线程 B 可见。
中断规则:对线程
interrupt()方法的调用先行发生于被中断线程的代码检测到中断事件的发生;终结规则:线程中所有的操作都先行发生于线程的终止检测,我们可以通过
Thread.join()方法结束、Thread.isAlive()的返回值手段检测到线程已经终止执行;假定线程 A 在执行的过程中,通过制定 ThreadB.join()等待线程 B 终止,那么线程 B 在终止之前对共享变量的修改在线程 A 等待返回后可见。
对象终结规则:一个对象的初始化完成先行发生于他的 finalize()方法的开始;
简单来说
程序顺序规则: 对于单个线程中的每个操作,前继操作 happens-before 于该线程中的任意后续操作。
监视器锁规则: 对一个锁的解锁,happens-before 于随后对这个锁的加锁。
volatile 变量规则: 对一个 volatile 域的写,happens-before 于任意后续对这个 volatile 域的读。
传递性: 如果 A happens-before B,且 B happens-before C,那么 A happens-before C。
- 以上为原生 Java 满足 Happens-before 关系的规则,可引申推导出其他六条:
- 将一个元素放入一个线程安全的队列的操作 Happens-Before 从队列中取出这个元素的操作
- 将一个元素放入一个线程安全容器的操作 Happens-Before 从容器中取出这个元素的操作
- 在 CountDownLatch 上的倒数操作Happens-Before 于 CountDownLatch#await()操作
- 释放Semaphore 许可的操作 Happens-Before获得许可操作
- Future表示的任务的所有操作Happens-Before Future#get()操作
- 向 Execut提交一个 Runnable 或 Callable 的操作 Happens-Before 任务开始执行操作
as-if-serial 语义
as-if-serial 语义的意思是:不管怎么重排序,单线程程序的执行结果不能被改变。编译器、runtime 和处理器都必须遵守 as-if-serial 语义。所以编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。
下面还是以书中的实例(计算圆的面积)进行说明:
1 | double pi = 3.14; // A |
上面 3 个操作的数据依赖关系如图所示:
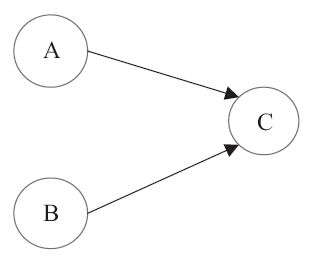
A 和 C 之间存在数据依赖关系,同时 B 和 C 之间也存在数据依赖关系。因此在最终执行的指令序列中,C 不能被重排序到 A 和 B 的前面(因为 C 排到 A 和 B 的前面,程序的结果将会被改变)。但 A 和 B 之间没有数据依赖关系,编译器和处理器可以重排序 A 和 B 之间的执行顺序。
该程序的两种可能执行顺序:

as-if-serial 语义把单线程程序保护了起来,遵守 as-if-serial 语义的编译器、runtime 和处理器共同为编写单线程程序的程序员创建了一个幻觉:单线程程序是按程序的顺序来执行的。
as-if-serial 语义使单线程程序员无需担心重排序会 干扰他们,也无需担心内存可见性问题。
volatile
- jvm 运行时刻内存的分配
前言:一定要注意!Java 内存区域(运行时数据区 )不等于Java 内存模型(JMM)
Java 内存区域是指 JVM 运行时数据分区域存储,而 Java 内存模型是定义了线程和主内存之间的抽象关系!
根据[JMM](#JMM(Java Memory Model)我们可以知道线程与主内存之间还存在着一个本地内存(工作内存),在这个内存中保存着变量的副本。
同样的,以类比的思想,jvm 运行时刻内存的分配中,有一个内存区域是 jvm 虚拟机栈,每一个线程运行时都有一个线程栈。
线程的工作内存与 java 的堆、栈并不是一个层次上的内存划分,如果非要类比的话工作内存对应虚拟机栈的部分区域 —— 《深入理解 java 虚拟机》
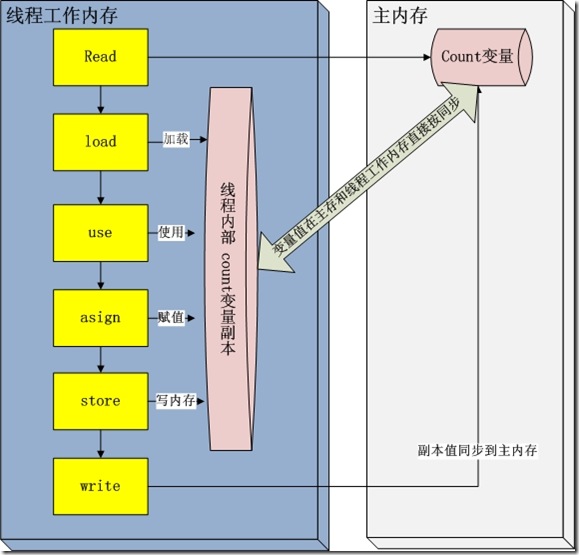
线程栈保存了线程运行时候变量值信息。当线程访问某一个对象时候值的时候,首先通过对象的引用找到对应在堆内存的变量的值,然后把堆内存中的变量的具体值load到线程本地内存中,建立一个变量副本,之后线程就不再和对象在堆内存变量值有任何关系,而是直接修改副本变量的值,在修改完之后的某一个时刻(线程退出之前),自动把线程变量副本的值回写到对象在堆中变量。这样在堆中的对象的值就产生变化了
- 问题引入
1 | public class VolatileTest extends Thread { |
上述代码运行流程:
- 首先创建 VolatileTest vt = new VolatileTest();
- 然后启动线程 vt.start();
- 暂停主线程 2 秒(Main) Thread.sleep(2000);
- 这时的 vt 线程已经开始执行,进行 i++;
- 主线程暂停 2 秒结束以后将 vt.flag = true;
- 打印语句 System.out.println(“stope” + vt.i); 在此同时由于 vt.flag 被设置为 true,所以 vt 线程在进行下一次 while 判断 while (!flag) 返回假 结束循环 vt 线程方法结束退出!
- 主线程结束
然而输出结果是:stope1620137804,并且程序不会退出。也就是说我们在主线程设置的 vt.flag = true;没有起作用
- 问题解决 理解
问题:主线程中设置flag = true,然而子线程并未获取到修改后的值,进行判断时的 flag 仍然为 false。
需要结合jvm 运行时刻内存的分配去理解
子线程执行过程
首先子线程(vt 线程)运行时,将*变量 flag 与 i *从 主内存 拷贝到 线程栈内存(即线程工作内存)
接着执行 while 循环
1
2
3while (!flag) {
i++;
}需要注意的是:while (!flag) 进行判断的 flag 是在线程工作内存当中获取,而不是从 主内存 中获取。
i++; 将线程工作内存中的 i++; 加完以后将结果写回至 主内存,如此重复。
主线程执行过程
创建子线程
启动子线程
主线程 sleep
vt.flag = true;(重点)- 主线程将 vt.flag 的值从主内存中拷贝到自己的线程工作内存
- 然后修改 flag=true.
- 然后再将新值回到主内存。
这就解释了为什么在主线程(main)中设置了 vt.flag = true; 而 vt 线程在进行判断 flag 的时候拿到的仍然是 false。那就是因为 vt 线程每次判断 flag 标记的时候是从它自己的“工作内存中”取值,而并非从主内存中取值!
问题解决
我们在上面主线程的第四步发现了问题了,是由于子线程的取值并不是在主内存中进行,而是在自己的工作内存中获取的,因此,要想解决这个问题也很简单:让 vt 线程每次判断 flag 的时候都强制它去主内存中取值
这就是volatile 关键字的作用:被加了这个关键字的数据,在被线程修改后,会从本地工作内存被强制的刷新回主内存,也就是让主内存中的变量值变成最新的值。
1 | public class VolatileTest extends Thread { |
运行结果:
1 | stope1662380642 |
程序能够正常退出了。
- bonus
例子:现在让线程 1 去修改 data 为 1,然而线程 2 由于可见性问题,并不能读取到变更后的 data(也就是线程 2 读取到的 data 一直是工作内存中的 data(即为 0)。因此就需要使用volatile去解决了。
而 volatile 关键字除了能够让本地工作内存中的数据被强制的刷新回主内存外,还有着别的作用
如果此时别的线程的工作内存中有这个 data 变量的本地缓存,也就是一个变量副本的话,那么会强制让其他线程的工作内存中的 data 变量缓存直接失效过期,不允许再次读取和使用了
如果线程 2 在代码运行过程中再次需要读取 data 变量的值,此时尝试从本地工作内存中读取,就会发现这个 data = 0 已经过期了!
此时,他就必须重新从主内存中加载 data 变量最新的值!那么不就可以读取到 data = 1 这个最新的值了!
- 总结
volatile 主要作用是保证可见性以及有序性。
但是内存模型三大要素缺漏了一个:原子性,也就是说,volatile 关键字并不能保证原子性
结合线程理解就是:
- volatile 主要解决的是一个线程修改变量值之后,其他线程立马可以读到最新的值,是解决这个问题的,也就是可见性!
- 多个线程同时修改一个变量的值,那还是可能出现多线程并发的安全问题,导致数据值修改错乱,volatile 是不负责解决这个问题的,也就是不负责解决原子性问题
原子性的问题需要去结合锁机制去解决。
Java 并发机制底层实现
- 前言
在 OS 学习中,我们学习了线程同步的相关知识。
其中有一个临界区的概念
临界区是一个用以访问共享资源的代码块,这个代码块在同一时间内只允许一个线程执行。
在 OS 中,我们使用了信号量、管程等方法去实现同步。现在学习了 Java,就需要用 Java 中类似的机制去实现。
Java 提供了同步机制。当一个线程试图访问一个临界区时,它将使用一种同步机制来查看是不是已有其他线程进入临界区。如果没有其他线程进入临界区,它就可以进入临界区;如果已有线程进入了临界区,它就被同步机制挂起,直到进入的线程离开这个临界区。如果在等待进入临界区的线程不止一个,JVM 会随机选择其中的一个,其余的将继续等待。
volatile 的实现原理
在前面volatile 部分中,学习了 volatile 的基本概念,但是没有去学习其底层实现,下面就来看看 volatile 是如何保证可见性与有序性的
MESI 缓存一致性协议
cache line
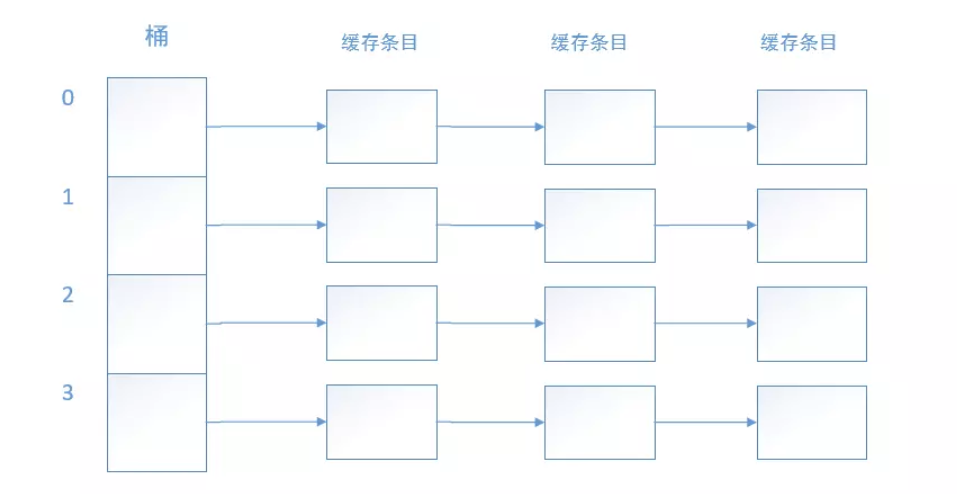
如图所示,CPU 中高速缓存内部结构是一个拉链散列表(与 HashMap 的底层结构以及原理十分相似)。它分为若干桶,每个桶是一个链表,包含若干缓存条目,每个缓存条目就是一个 cache line(64 bytes)。
作用是什么呢?假设程序中读取某一个 int 变量,CPU 并不是只从主存中读取 4 个字节,而是会一次性读取 64 个字节,然后放到 cpu cache 中。因为往往紧挨着的数据,更有可能在接下来会被使用到。
这里类似于 IO 的磁盘读取,应用到了时间和空间局部性原理
在 CPU 访问存储设备时,无论是存取数据抑或存取指令,都趋于聚集在一片连续的区域中,这就被称为局部性原理。
时间局部性(Temporal Locality):如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。比如循环、递归、方法的反复调用等。
空间局部性(Spatial Locality):如果一个存储器的位置被引用,那么将来他附近的位置也会被引用。比如顺序执行的代码、连续创建的两个对象、数组等。
- 进一步可分为三部分

CPU 访问内存时,会通过内存地址解码的三个数据:index(桶编号)、tag(缓存条目的相对编号)、offset(变量在缓存条目中的位置偏移)来获取高速缓存中对应的数据。
这时候可以看到 Flag 这个标识了,然后就可以引出了状态值的概念,然后就可以引出我们所说的 MSEI 协议了。
MESI
| 状态 | 描述 |
|---|---|
| M 修改 (Modified) | 该 Cache line 有效,数据被修改了,和内存中的数据不一致,数据只存在于本 Cache 中。 |
| E 独享、互斥 (Exclusive) | 该 Cache line 有效,数据和内存中的数据一致,数据只存在于本 Cache 中。 |
| S 共享 (Shared) | 该 Cache line 有效,数据和内存中的数据一致,数据存在于很多 Cache 中。 |
| I 无效 (Invalid) | 该 Cache line 无效。 |
- E(独占)状态
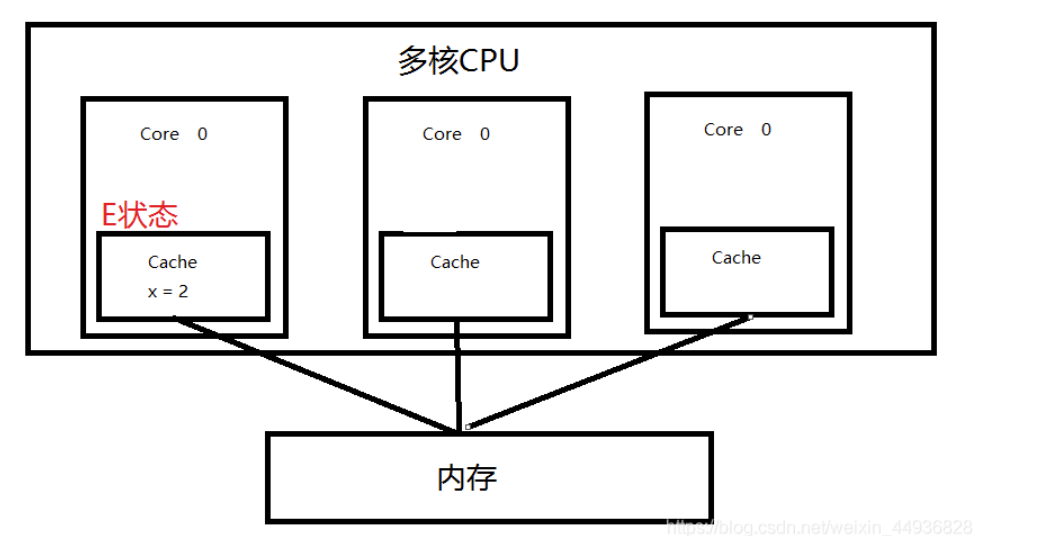
只有 Core 0 访问变量 x,它的 Cache line 状态为 E(Exclusive)。
- S(共享)状态
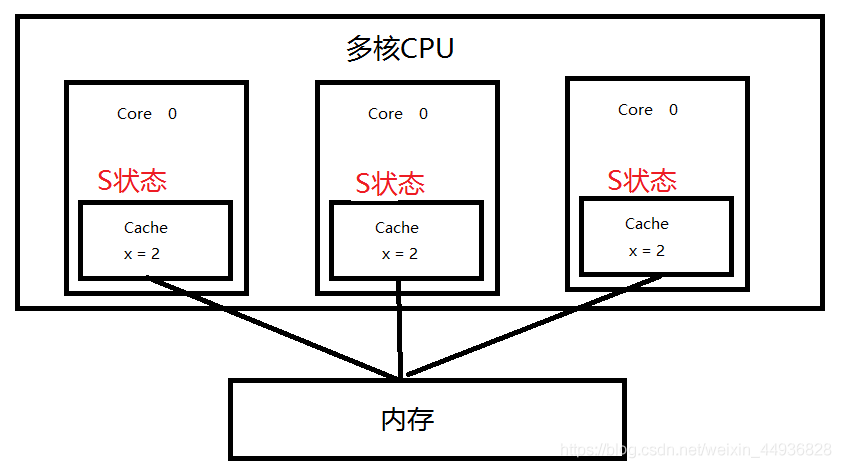
3 个 Core 都访问变量 x,它们对应的 Cache line 为 S(Shared)状态。
- M(修改)状态

Core 0 修改了 x 的值之后,这个 Cache line 变成了 M(Modified)状态
- I 状态
在一个 Core 修改 x 后,相应的,其他 Core 对应的 Cache line 变成了 I(Invalid)状态。
- 状态的改变
cache line 存在四种状态,状态是动态的,肯定是有一定的操作使得状态发生了改变,那么操作是什么呢?

- Local Read 表示本内核读本 Cache 中的值
- Local Write 表示本内核写本 Cache 中的值
- Remote Read 表示其它内核读其它内核 Cache 中的值
- Remote Write 表示其它内核写其它内核 Cache 中的值
- 总结
MESI 协议为了保证多个 CPU cache 中共享数据的一致性,定义了 cache line 的四种状态,而 CPU 对 cache 的 4 种操作可能会产生不一致状态,因此 cache 控制器监听到本地操作和远程操作的时候,需要对地址一致的 cache line 状态做出一定的修改,从而保证数据在多个 cache 之间流转的一致性。
写缓存 - Store Buffer
- 场景引入
有一个变量在多个核中的缓存存在,那么这个缓存的状态是S(shared)共享的,现在核 A 想要修改这个变量,首先核 A 会向所有拥有相同缓存的其他核发送一个请求,告诉其他核中的缓存是I(Invalid)无效的,其他核收到这个信息将自己核中的缓存状态设置为无效之后,返回一个设置完成的消息,这个核 A 收到这个无效状态修改的消息后,再把自己的状态改为E(Exclusive)独享的,然后修改为M(Modified)进行缓存修改。
思考下:在核 A 等待其他核返回无效状态修改的消息返回的时候它做了什么?它什么都没做,一直处于阻塞状态。
因此,设计者引入了写缓存(Store Buffer)的无效化队列(Invalidate Queue)来解决这个问题。
- 概述
写缓存是一个容量极小的高速存储部件,每个核都有自己的写缓存,而且一个核不能够读取到其他核的写缓存(Store Buffer)的内容,相当于一个自己的本地缓存。
如上面的场景,核 A 修改共享的缓存,先将这个修改操作放入到写缓存(Store Buffer)中,再告诉其他核中的缓存失效了,然后核 A 继续执行其他指令操作,当接受到了其他核返回无效状态修改的消息之后,才将写缓存(Store Buffer)中的操作写入到核 A 中的缓存中,这时写操作才算完成。
这样就解决了等待阻塞所带来的性能问题,减少了延时,提高了执行效率。
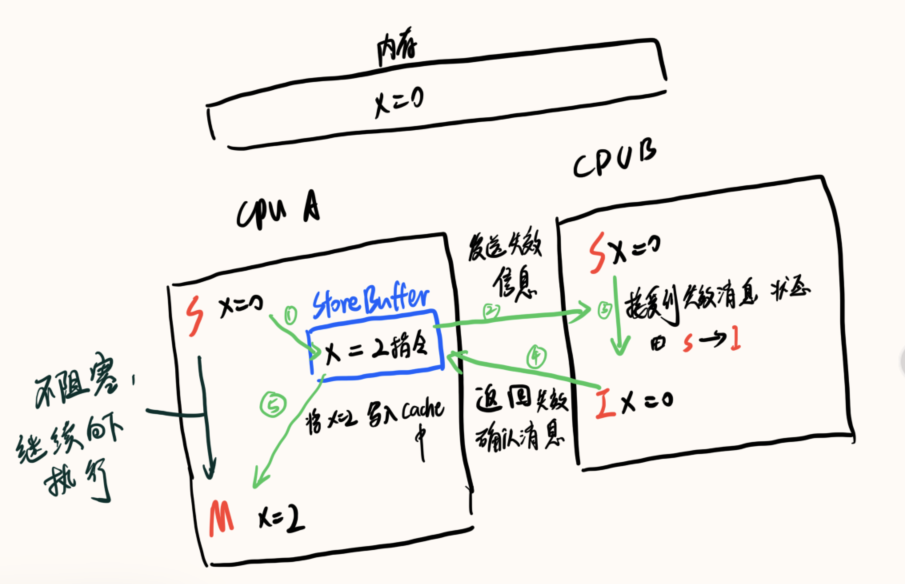
无效化队列 - Invalidate Queue
修改方为了能够快速进行回应所以,先将无效的操作放到队列里面去,并立刻返回无效状态修改的消息,等当前的操作执行完再回来真正的把缓存里面的值标识为 I 状态,这个存放无效操作的队列就叫做无效化队列。同时可能也是考虑到了写缓存(Store Buffer)是比较小的高速缓存,如果不能够及时返回会造成写缓存满了,还是需要等待无效状态修改的消息的返回才能继续进行后续的指令,所以就出现了无效化队列和写缓存配合使用。
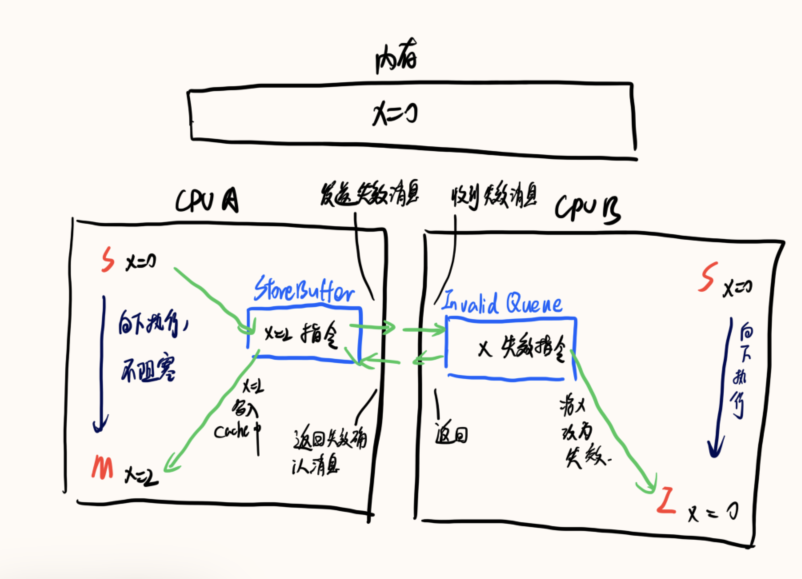
写缓存与无效化队列的不足性
- 单核情况
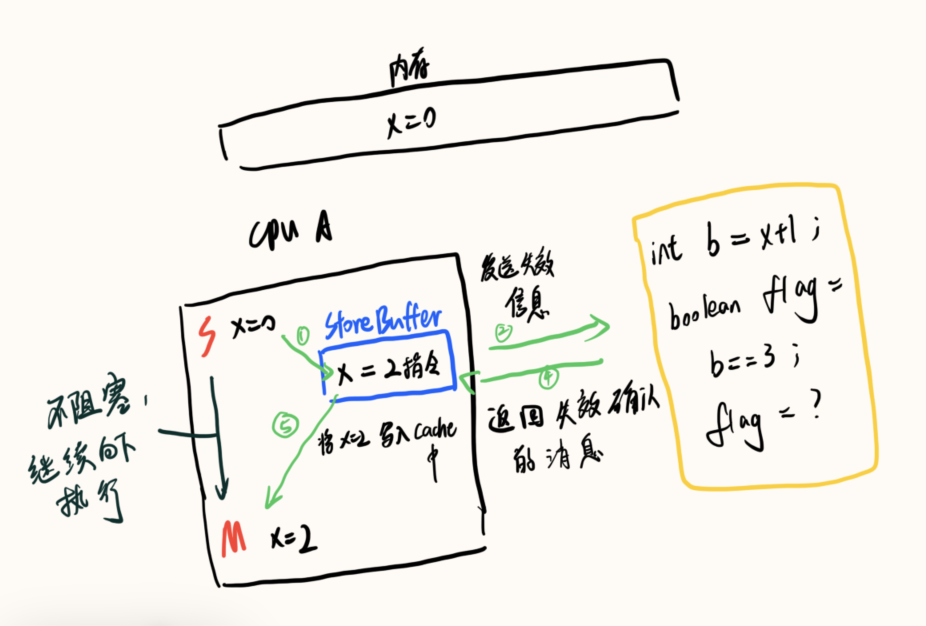
令 b=x+1,因为 x 已经在缓存中读到的为 0,b 为 1,所以判断是 false,虽然后来 Store Buffer 后来将 x 的值刷新到了缓存中,但是已经晚了
所以为了避免这个问题,Store Buffer 设计了一种策略叫做 Store Forwarding。就是说核 A 在读取数据的时候会先看 Store Buffer 中的数据,如果 Store Buffer 中有数据,直接使用 Store Buffer 中的,从而避免使用错误数据。
- 多核情况
情况一
核 B 在进行判断的时候发现在自己的缓存存在 x=0,就直接+1 进行了赋值判断,但此时核 A 刚刚将 x=2 的操作放到 Store Buffer 中,所以由于 Store Buffer 的存在导致多核下不能获取到最新值,所以产生了错误的结果。
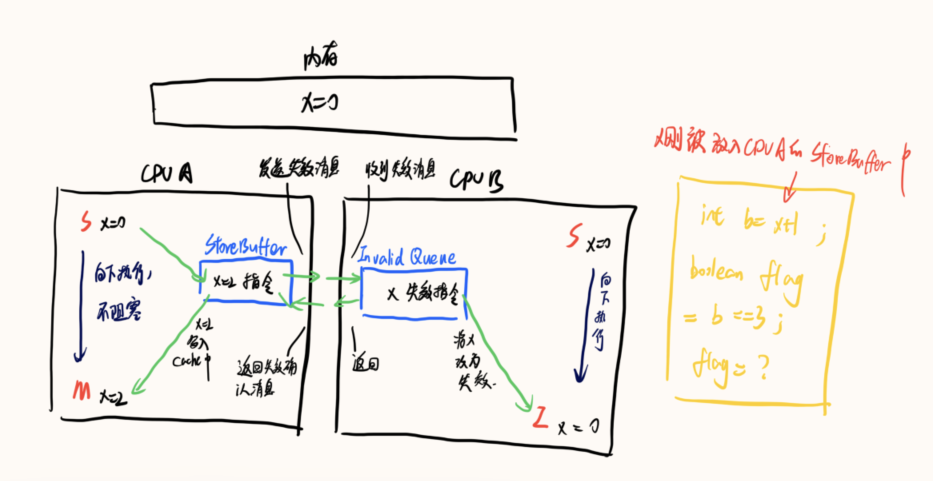
所以为了解决上面的问题出现了写屏障,写屏障的出现保证屏障两边写的执行是分开的,也就是说需要先将之前 Store Buffer 中的所有写指令都刷新到缓存之后,才执行后面的写指令。
具体实现方法是,【先将屏障之前的Store Buffer 中所有操作都刷新到缓存中】,将屏障后的所有指令操作也同样放到 Store Buffer 中,不管后续的操作是什么都往里面放,这样可以提高 CPU 的执行效率,都通过 Store Buffer 刷新到了缓存中,达到了数据来源的统一性。情况二
核 B 在进行判断的时候发现在自己的缓存存在 x=0,就直接+1 进行了赋值判断,但此时核 B 刚刚将 x 的无效操作放到 Invalidate Queue 中,所以由于 Invalidate Queue 的存在导致多核下不能获取到最新值,所以产生了错误的结果。
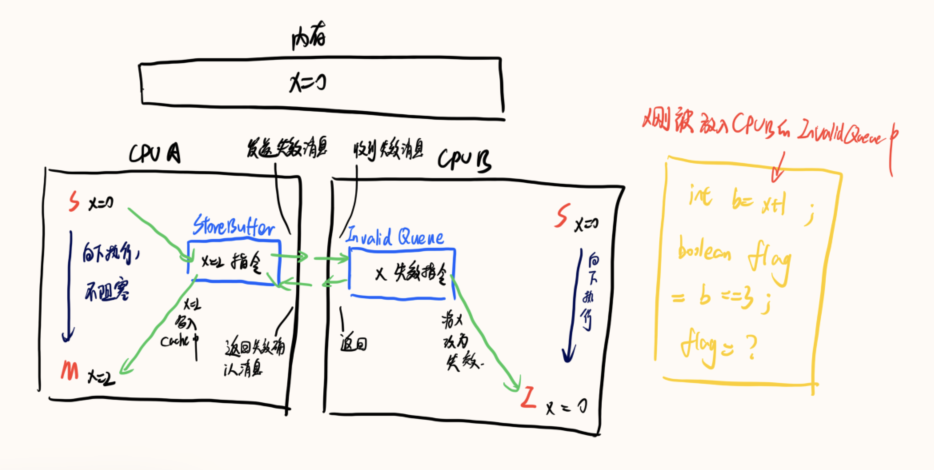
所以为了解决上面的问题出现了读屏障,读屏障的出现保证屏障两边读的执行是分开的,也就是说需要先将之前 Invalidate Queue 中的所有指令处理完之后,才执行后面的指令,保证下一次读取共享变量的时候读到的是最新的变量。
内存屏障
通过上面对错误情况的分析可以知道,内存屏障的出现就是为了解决因为 Store Buffer 和 Invalidate Queue 所带来的数据可见性问题,也就是读和写不能实时更新到其他核的问题。内存屏障同时还具备强制将 Store Buffer 的内容刷到缓存中,强制将 Invalidate Queue 中的内容设置完毕的作用。
- 硬件层的内存屏障分为两种:
Load (Memory) Barrier读屏障和Store (Memory) Barrier写屏障 - 内存屏障有两个作用:
- 阻止屏障两侧的指令重排序;
- 强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
对于 Load Barrier 来说,在指令前插入 Load Barrier,可以让高速缓存中的数据失效,强制从新从主内存加载数据
或者说: 强制将 Invalidate Queue 中的内容处理完毕,也被称之为 smp_rmb
对于 Store Barrier 来说,在指令后插入 Store Barrier,能让写入缓存中的最新数据更新写入主内存,让其他线程可见。
或者说:强制将 Store Buffer 中的内容写入到缓存中或者将该指令之后的写操作写入 store buffer 直到之前的内容被刷入到缓存中,也被称之为 smp_wmb
内存屏障分类
按照可见性保障来划分
内存屏障可分为:加载屏障(Load Barrier)和存储屏障(Store Barrier)。加载屏障:StoreLoad 屏障可充当加载屏障,作用是刷新处理器缓存,即清空无效化队列,使处理器在读取共享变量时,先从主内存或其他处理器的高速缓存中读取相应变量,更新到自己的缓存中
存储屏障:StoreLoad 屏障可充当存储屏障,作用是冲刷处理器缓存,即将写缓冲器内容写入高速缓存中,使处理器对共享变量的更新写入高速缓存或者主内存中
这两个屏障一起保证了数据在多处理器之间是可见的。按照有序性保障来划分
内存屏障分为:获取屏障(Acquire Barrier)和释放屏障(Release Barrier)。获取屏障:相当于LoadLoad 屏障与 LoadStore 屏障的组合。在读操作后插入,禁止该读操作与其后的任何读写操作发生重排序;
释放屏障:相当于LoadStore 屏障与 StoreStore 屏障的组合。在一个写操作之前插入,禁止该写操作与其前面的任何读写操作发生重排序。
这两个屏障一起保证了临界区中的任何读写操作不可能被重排序到临界区之外。
Java 内存屏障
Java 四种屏障其实是Load Barrier与Store Barrier的两两组合(2 × 2 = 4)
此处提及的【load → 加载】和【store → 写入】
LoadLoad:对于语句
Load1; 【LoadLoad】; Load2,这个屏障的作用是确保在 Load2 加载代码在要读取的数据之前,保证 Load1 加载代码要从主内存里面读取的数据读取完毕。即:该屏障保证了在屏障前的读取操作效果先于屏障后的读取操作效果发生。在各个不同平台上会插入的编译指令不相同,可能的一种做法是插入也被称之为 smp_rmb 指令,强制处理完成当前的 invalidate queue 中的内容
StoreStore:对于语句
Store1; 【StoreStore】; Store2,这个屏障的作用是保证在 Store2 存储代码进行写入操作执行前,保证 Store1 的写入操作已经把数据写入到主内存里面,确认 Store1 的写入操作对其它处理器可见。即:该屏障保证了在屏障前的写操作效果先于屏障后的写操作效果发生。可能的做法是使用 smp_wmb 指令,而且是使用该指令中,将后续写入数据先写入到 store buffer 的那种处理方式。因为这种方式消耗比较小
LoadStore:对于语句
Load1; 【LoadStore】; Store2,这个屏障的作用是保证在 Store2 存储代码进行写入操作执行前,保证 Load1 加载代码要从主内存里面读取的数据读取完毕。即:该屏障保证了屏障前的读操作效果先于屏障后的写操作效果发生。
StoreLoad:对于语句
Store1; StoreLoad; Load2,这个屏障的作用是保证 load2 从主内存里加载数据之前,store1 的写入操作已经把数据写入到内存中,确认 store1 的写入操作对其他处理器可见即:该屏障保证了屏障前的写操作效果先于屏障后的读操作效果发生。可能的做法就是插入一个 smp_mb 指令来完成。StoreLoad 屏障是开销最昂贵的一种屏障,其中一部分原因是因为他需要把写缓冲区的所有数据全部刷新到内存
如何保证可见性
可见性的实现依靠了:lock 前缀指令 + MESI 缓存一致性协议
实现原理 - Lock 前缀
被 volatile 修饰的字段会在其对应的汇编操作指令上加个lock 前缀指令,这个指令就可以解决可见性问题。
1 | public class Visable { |
其执行结果:
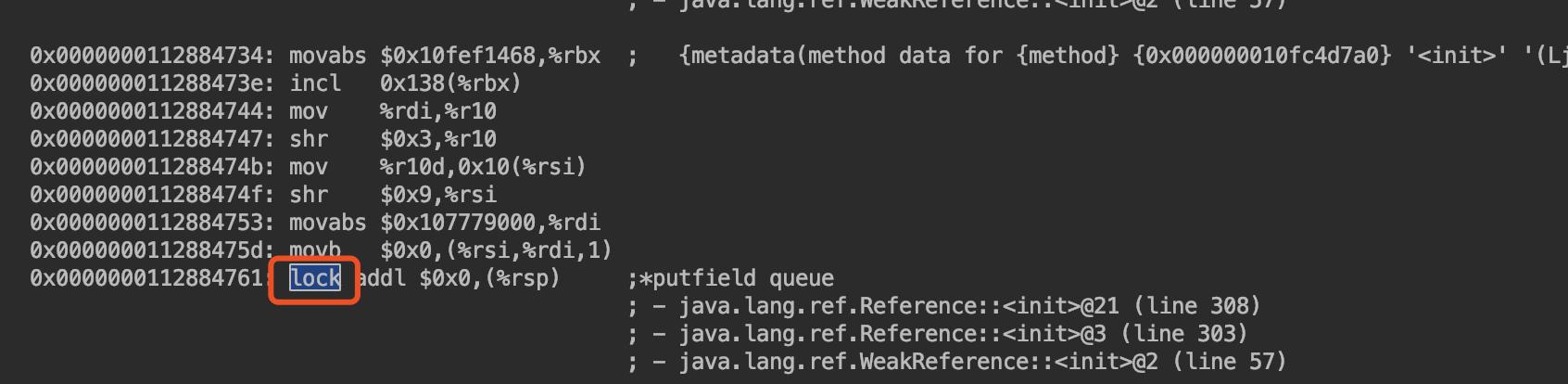
lock 前缀的指令在多核处理器下会引发两件事情
- 将当前处理器缓存行的数据写回到系统内存。
- 这个写回内存的操作会使在其他 CPU 里缓存了该内存地址的数据无效。
为了提高处理速度,处理器不直接和内存进行通信,而是先将系统内存的数据读到内部缓存后再进行操作,但是操作完了不知道什么时候写回内存。
而对声明了 volatile 关键字的变量进行写操作,JVM 会向处理器发送一条 lock 前缀的指令,将这个变量所在的缓存行立即写回系统内存。并且为了保证各个处理器的缓存是一致的,实现了缓存一致性协议,各个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,那么下次对这个数据进行操作,就会重新从系统内存中获取最新的值。对应 JMM 来说就是:
- Lock 前缀的指令让线程工作内存中的值写回主内存中;
- 通过缓存一致性协议,其他线程如果工作内存中存了该共享变量的值,就会失效;
- 其他线程会重新从主内存中获取最新的值;
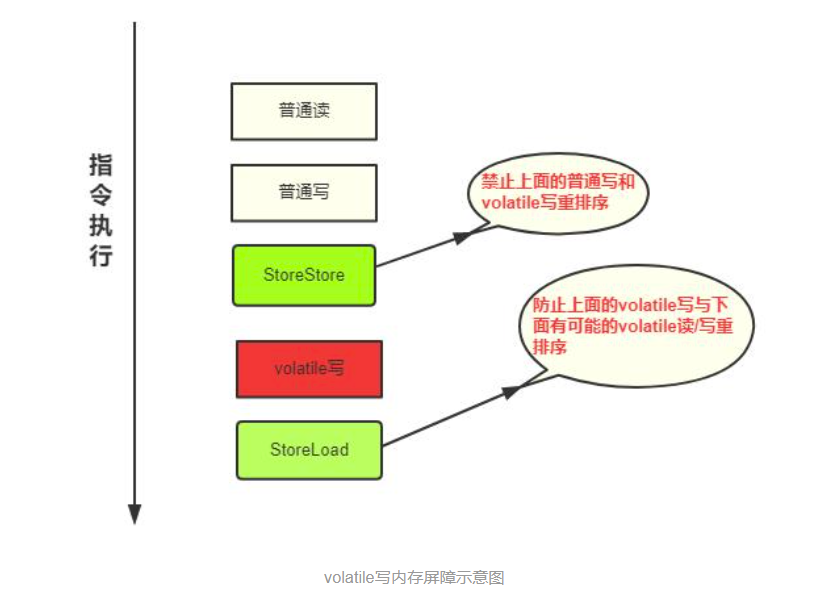
如何保证有序性
可靠性的实现依靠了:内存屏障,禁止了重排序
- 在每个 volatile 写操作的前面插入一个 StoreStore 屏障。
- 在每个 volatile 写操作的后面插入一个 StoreLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadLoad 屏障。
- 在每个 volatile 读操作的后面插入一个 LoadStore 屏障。
CAS
CAS 概述
使用锁时,线程获取锁是一种悲观锁策略,即假设每一次执行临界区代码都会产生冲突,所以当前线程获取到锁的时候同时也会阻塞其他线程获取该锁。而 CAS 操作(又称为无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源的时候不会出现冲突,既然不会出现冲突自然而然就不会阻塞其他线程的操作。
因此,线程就不会出现阻塞停顿的状态。那么,如果出现冲突了怎么办?无锁操作是使用CAS(compare and swap / 比较与替换)又叫做比较交换来鉴别线程是否出现冲突,出现冲突就重试当前操作直到没有冲突为止。
- 悲观锁:会阻塞其他线程
- 乐观锁:不会阻塞其他线程,如果发生冲突,采用死循环的方式一直重试,直到更新成功。
是一种无锁算法
CAS 操作过程
CAS 比较交换的过程可以通俗的理解为 CAS(V,O,N),包含三个值分别为:V 内存地址存放的实际值;O 预期的值(旧值);N 更新的新值。
- 当 V 和 O 相同时,也就是说旧值和内存中实际的值相同表明该值没有被其他线程更改过,即该旧值 O 就是目前来说最新的值了,自然而然可以将新值 N 赋值给 V。
- 反之,V 和 O 不相同,表明该值已经被其他线程改过了则该旧值 O 不是最新版本的值了,所以不能将新值 N 赋给 V,返回 V 即可。当多个线程使用 CAS 操作一个变量是,只有一个线程会成功,并成功更新,其余会失败。失败的线程会重新尝试,当然也可以选择挂起线程
CAS 的实现需要硬件指令集的支撑,在 JDK1.5 后虚拟机才可以使用处理器提供的CMPXCHG指令实现。
Synchronized VS CAS
元老级的 Synchronized(未优化前)最主要的问题是:在存在线程竞争的情况下会出现线程阻塞和唤醒锁带来的性能问题,因为这是一种互斥同步(阻塞同步)。而 CAS 并不是武断的间线程挂起,当 CAS 操作失败后会进行一定的尝试,而非进行耗时的挂起唤醒的操作,因此也叫做非阻塞同步。这是两者主要的区别。
CAS 应用场景
在 J.U.C 包中利用 CAS 实现类有很多,可以说是支撑起整个 concurrency 包的实现,在 Lock 实现中会有 CAS 改变 state 变量,在 atomic 包中的实现类也几乎都是用 CAS 实现。具体实现后续详细聊;
CAS 存在的问题
1. ABA 问题
因为 CAS 会检查旧值有没有变化,这里存在这样一个有意思的问题。比如一个旧值 A 变为了成 B,然后再变成 A,刚好在做 CAS 时检查发现旧值并没有变化依然为 A,但是实际上的确发生了变化。解决方案可以沿袭数据库中常用的乐观锁方式,添加一个版本号可以解决。原来的变化路径 A->B->A 就变成了 1A->2B->3C。java 这么优秀的语言,当然在 java 1.5 后的 atomic 包中提供了 AtomicStampedReference 来解决 ABA 问题,解决思路就是这样的。
2. 自旋时间过长
使用 CAS 时非阻塞同步,也就是说不会将线程挂起,会自旋(无非就是一个死循环)进行下一次尝试,如果这里自旋时间过长对性能是很大的消耗。如果 JVM 能支持处理器提供的 pause 指令,那么在效率上会有一定的提升。
3. 只能保证一个共享变量的原子操作
原子性:原子性问题指的是多线程并发的情况下,当我们要进行数据的读取与修改时,可能会因为线程同时读取数据,导致进行了重复修改的情况,但是我们希望每个线程进行读取修改操作是连贯的、原子性的,在 A 线程进行读取修改的时候,不允许其他线程进行读取修改,而一定要等到 A 线程完成修改后,其他线程再去进行读取修改。比如我们要将数字 0 累加到 10,在多线程的情况下,可能会因为线程 A 在读完数字但是还没有进行修改的时候,线程 B 也来读了数字,导致线程 A 的原子性被打破,使得它们累加后得到的数据是一样的,这就破坏了原子性。
当对一个共享变量执行操作时 CAS 能保证其原子性,如果对多个共享变量进行操作,CAS 就不能保证其原子性。有一个解决方案是利用对象整合多个共享变量,即一个类中的成员变量就是这几个共享变量。然后将这个对象做 CAS 操作就可以保证其原子性。atomic 中提供了 AtomicReference 来保证引用对象之间的原子性。
Java 对象头 monitor
Java 对象头和 monitor 是实现 synchronized 的基础
Java 对象头
概述
JVM 中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充

实例数据:存放类的属性数据信息,包括父类的属性信息,如果是数组的实例部分还包括数组的长度,这部分内存按 4 字节对齐。
对齐填充:由于虚拟机要求对象起始地址必须是 8 字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐
对象头
普通对象

数组对象

对象头的组成
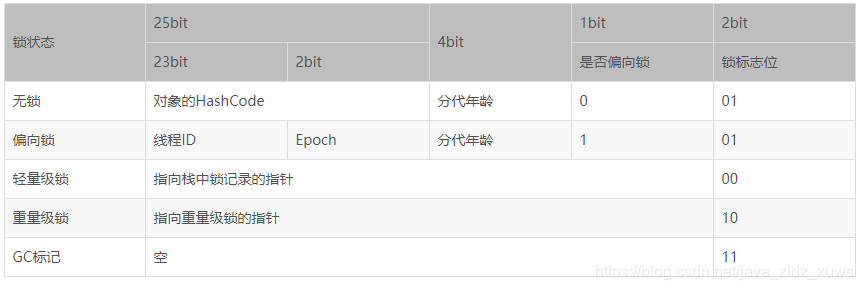
Mark Word
Mark Word 用于存储对象自身的运行时数据,如哈希码(HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID、偏向时间戳等等
- 32 位 JVM 的 Mark Word 的默认存储结构
对象头信息是与对象自身定义的数据无关的额外存储成本,但是考虑到虚拟机的空间效率,Mark Word 被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据,它会根据对象的状态复用自己的存储空间,也就是说,Mark Word 会随着程序的运行发生变化。
具体结构

锁标记位(lock):该标记的值不同,则 Mark word 表示的含义不同
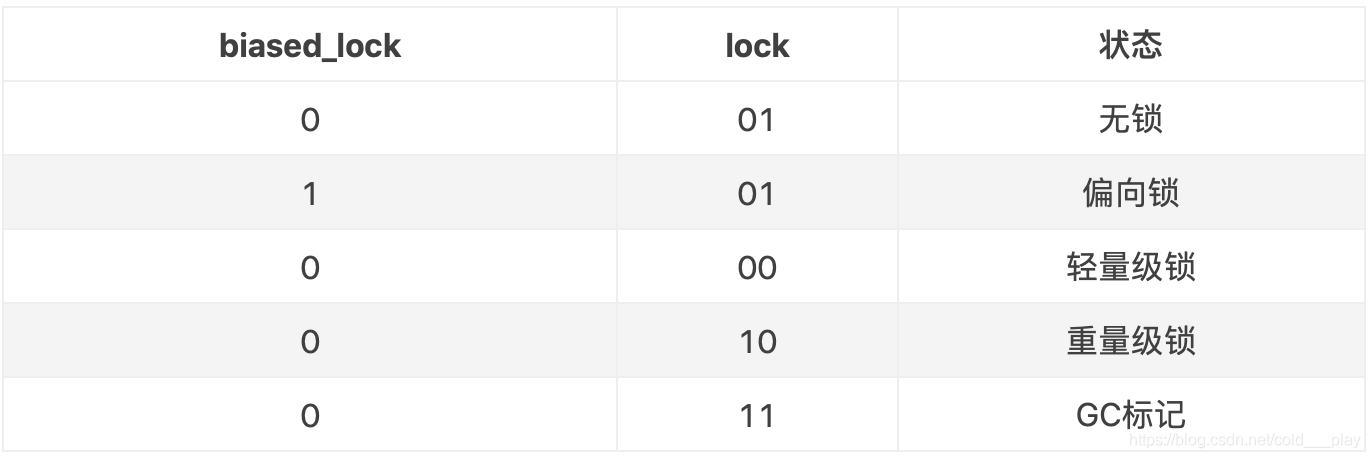
- 无锁:无锁状态时,存储的是对象的 hashcode 值
- 偏向锁:偏向锁时,前 23 位存储偏向的线程 ID,并将倒数第三位置为 1,表示偏向锁。
- 轻量级锁:轻量级锁时,存储的是 指向 JVM 栈中的锁记录 Lock Record 的指针
- 重量级锁:当自旋次数超过 10 次时,将转换成重量级锁,重量级锁存储的是 指向重量级锁 Monitor 的指针
是否为偏向锁(biased_lock):对象是否启用偏向锁标记,只占 1 个二进制位。为 1 时表示对象启用偏向锁,为 0 时表示对象没有偏向锁。
对象分代年龄(age):4 位的 Java 对象年龄。在 GC 中,如果对象在 Survivor 区复制一次,年龄增加 1。当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行 GC 的年龄阈值为 15,并发 GC 的年龄阈值为 6。由于 age 只有 4 位,所以最大值为 15,这就是
-XX:MaxTenuringThreshold选项最大值为 15 的原因。identity_hashcode: 25 位的对象标识Hash 码,采用延迟加载技术。调用方法
System.identityHashCode()计算,并会将结果写到该对象头中。当对象被锁定时,该值会移动到管程 Monitor 中。thread: 持有偏向锁的线程 ID。
epoch:偏向时间戳。
ptr_to_lock_record:指向栈中锁记录的指针。
ptr_to_heavyweight_monitor:指向管程 Monitor 的指针。
class pointer
这一部分用于存储对象的类型指针,该指针指向它的类元数据,JVM 通过这个指针确定对象是哪个类的实例。该指针的位长度为 JVM 的一个字大小,即 32 位的 JVM 为 32 位,64 位的 JVM 为 64 位。
为了节约内存可以使用选项+UseCompressedOops 开启指针压缩,其中,oop 即 ordinary object pointer 普通对象指针。开启该选项后,下列指针将压缩至 32 位:
- 每个 Class 的属性指针(即静态变量)
- 每个对象的属性指针(即对象变量)
- 普通对象数组的每个元素指针
当然,也不是所有的指针都会压缩,一些特殊类型的指针 JVM 不会优化,比如指向 PermGen 的 Class 对象指针(JDK8 中指向元空间的 Class 对象指针)、本地变量、堆栈元素、入参、返回值和 NULL 指针等。
array length
如果对象是一个数组,那么对象头还需要有额外的空间用于存储数组的长度,这部分数据的长度也随着 JVM 架构的不同而不同:32 位的 JVM 上,长度为 32 位;64 位 JVM 则为 64 位。64 位 JVM 如果开启+UseCompressedOops 选项,该区域长度也将由 64 位压缩至 32 位。
monitor
monitor 是什么?它是一个同步工具,是一种同步机制,通常被描述为一个【对象】;
monitor 概念其实我们早就接触过了,它就是 OS 中的【管程】;
Monitor 是一个对象,这代表着什么?在 Java 世界中,一切皆对象,那么所有的 Java 对象其实都是 monitor,或者说所有的对象都可以去关联一个Monitor对象。(这也是为什么上面需要学习 Java 对象头,因为结合 monitor 我们就可以通过设置标识位做到线程同步了)
- Monitor 概念
Monitor 是线程私有的数据结构,每一个线程都有一个可用 monitor record 列表,同时还有一个全局的可用列表。
每一个被锁住的对象都会和一个 monitor 关联(对象头的 MarkWord中的LockWord指向monitor 的起始地址)
同时 monitor 中有一个Owner 字段存放拥有该锁的线程的唯一标识,表示该锁被这个线程占用
- Monitor 结构图
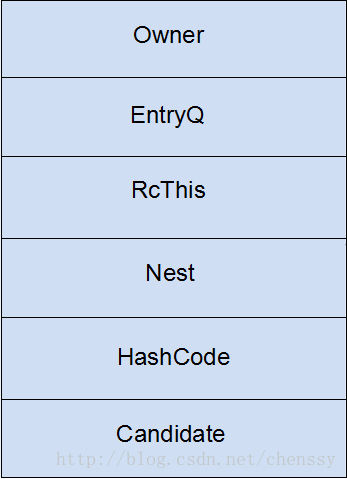
- Owner:初始时为 NULL 表示当前没有任何线程拥有该 monitor record,当线程成功拥有该锁后保存线程唯一标识,当锁被释放时又设置为 NULL;
- EntryQ:关联一个系统互斥锁(semaphore),阻塞所有试图锁住 monitor record 失败的线程。
- RcThis:表示 blocked 或 waiting 在该 monitor record 上的所有线程的个数。
- Nest:用来实现重入锁的计数。
- HashCode:保存从对象头拷贝过来的 HashCode 值(可能还包含 GC age)。
- Candidate:用来避免不必要的阻塞或等待线程唤醒,因为每一次只有一个线程能够成功拥有锁,如果每次前一个释放锁的线程唤醒所有正在阻塞或等待的线程,会引起不必要的上下文切换(从阻塞到就绪然后因为竞争锁失败又被阻塞)从而导致性能严重下降。Candidate 只有两种可能的值 0 表示没有需要唤醒的线程 1 表示要唤醒一个继任线程来竞争锁。
synchronized(内置锁)
概述
Java 中最常用的同步机制就是synchronized 关键字,它是一种基于语言的粗略锁(也就是说本质其实也是一把锁),能够作用于对象、函数、Class上。
synchronized 是一种互斥锁:意味着一次只能允许一个线程进入被锁住的代码块
synchronized 是一种内置锁/监视器锁:Java 中每个对象都有一个内置锁(监听器 monitor,可理解为锁标记),synchronized 就是通过使用对象的内置锁(监听器)来将代码块(方法)锁定的。(这部分内容结合 monitor 的相关知识好理解一点)
用处
- synchronized 保证了线程的原子性。(被保护的代码块是一次被执行的,没有任何线程会同时访问)
- synchronized 还保证了可见性。(当执行完 synchronized 之后,修改后的变量对其他的线程是可见的)
Java 中的 synchronized,通过使用内置锁,来实现对变量的同步操作,进而实现了对变量操作的原子性和其他线程对变量的可见性,从而确保了并发情况下的线程安全。
一句话来说:
synchronized 修饰的区域看作是一个临界区,临界区内只能有一个线程在访问,当访问线程退出临界区,另一个线程才能访问临界区资源。
原理
- synchronized 原理 - 指令层面
1 | public class SynchronizedDemo { |
反编译结果:
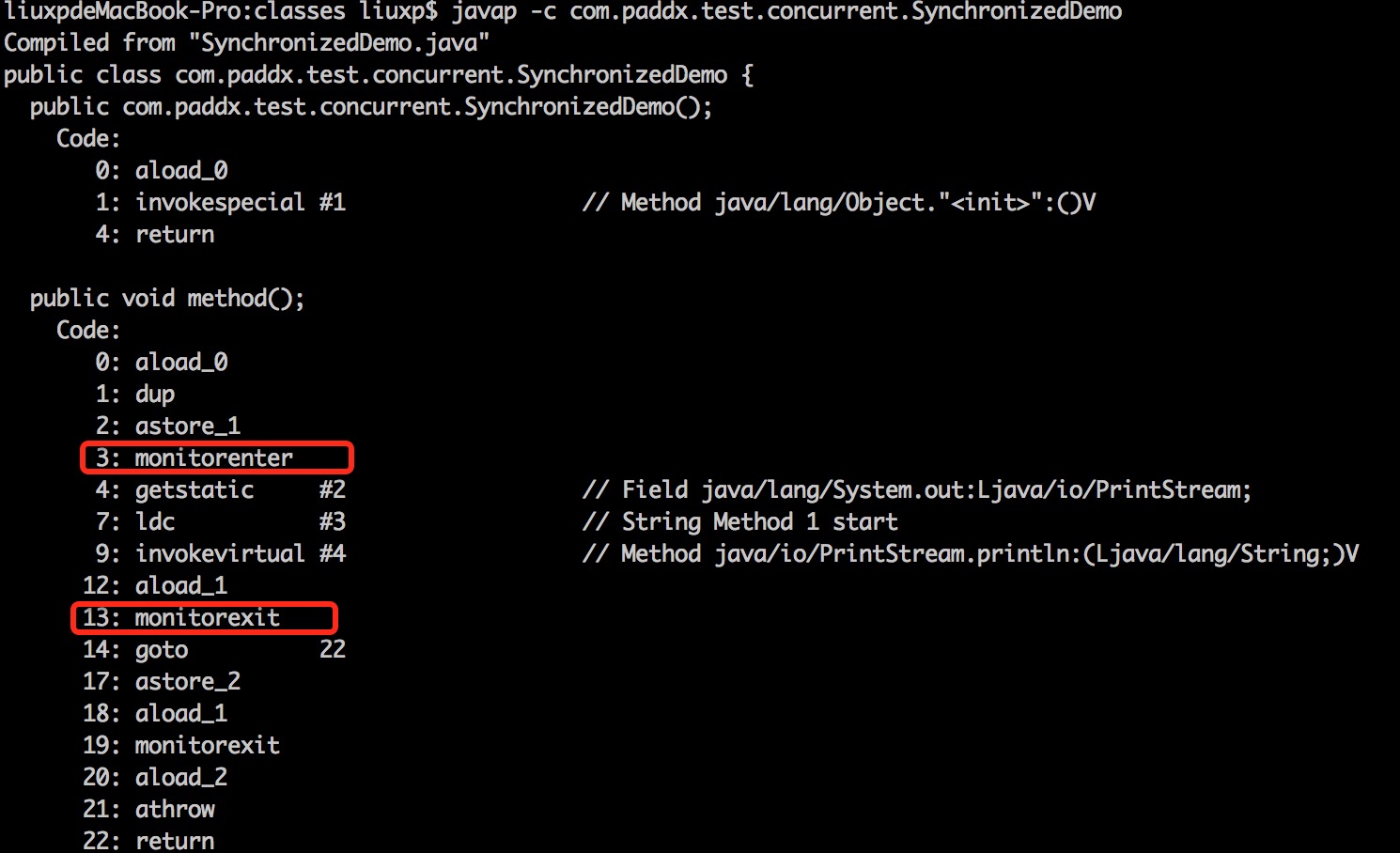
这里出现了两个关键指令【monitorenter】和【monitorexit】
【monitorenter】
每个对象有一个监视器锁(monitor)。当 monitor 被占用时就会处于锁定状态,线程执行 monitorenter 指令时尝试获取 monitor 的所有权(类似于操作系统中的P 操作),过程如下:
- 如果 monitor 的进入数为 0,则该线程进入 monitor,然后将进入数设置为 1,该线程即为 monitor 的所有者。
- 如果线程已经占有该 monitor,只是重新进入,则进入 monitor 的进入数加 1.
- 如果其他线程已经占用了 monitor,则该线程进入阻塞状态,直到 monitor 的进入数为 0,再重新尝试,获取 monitor 的所有权。
【monitorexit】
注意:执行 monitorexit 的线程必须是 objectref 所对应的 monitor 的所有者。
该指令执行时,monitor 的进入数减 1,如果减 1 后进入数为 0,那线程退出 monitor,不再是这个 monitor 的所有者。(类似于 OS 中的V 操作)其他被这个 monitor 阻塞的线程可以尝试去获取这个 monitor 的所有权。
结合这两个指令的含义,我们能够推断出 Synchronized 的实现原理:Synchronized 的语义底层是通过一个 monitor 的对象来完成类似于 OS 中的 PV 操作,达到线程同步。
- synchronized 实现原理 - 底层/字节码层面
1 | public class SynchronizedMethod { |
反编译结果:
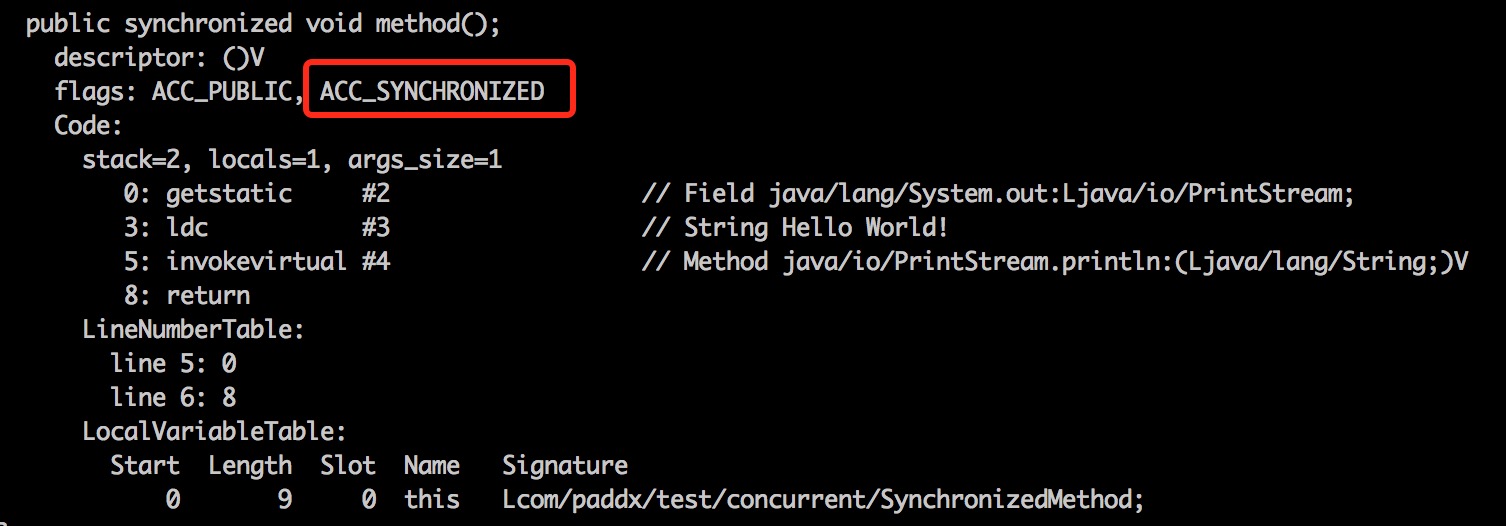
从字节码中可以看出,synchronized 修饰的方法并没有monitorenter 指令和 monitorexit 指令,取得代之的确实是ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该ACC_SYNCHRONIZED 标识访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用
具体实现:
当方法调用时,调用指令将会检查方法的 ACC_SYNCHRONIZED 访问标志是否被设置,如果设置了,执行线程将先获取 monitor,获取成功之后才能执行方法体,方法执行完后再释放 monitor。
使用
- 使用 synchronized 实现同步
使用 synchronized 关键字声明的方法 成为了 临界区。这样做,就使得临界区被创建出来了,由之前所学可以知道,同一个对象的临界区,在同一时间只有一个允许被访问。
用 synchronized 关键字声明的静态方法,同时只能被一个执行线程访问,但是其他线程可以访问这个对象的非静态方法。即:两个线程可以同时访问一个对象的两个不同的 synchronized 方法,其中一个是静态方法,一个是非静态方法
synchronized 作用于实例方法
修饰实例方法,作用于当前【实例对象】加锁,进入同步代码前要获得当前【实例对象】的锁
1 | public class AccountingSync implements Runnable{ |
代码解释:
我们使用static 关键字构造了一个临界资源:static int i=0;
同时,构建了一个实例方法
1 | public synchronized void increase(){ |
i++的操作并不具备原子性(先读 i 的值,对 i 进行++操作,后写回新值),如果第二个线程在第一个线程读取旧值和写回新值期间读取 i 的域值,那么第二个线程就会与第一个线程一起看到同一个值,并执行相同值的加 1 操作,这也就造成了线程安全失败,因此对于 increase 方法必须使用 synchronized 修饰,以便保证线程安全。
synchronized修饰的是实例方法increase(),即:当前线程上的锁作用于实例对象 instance
当一个线程正在访问一个对象的 synchronized 实例方法,那么其他线程不能访问该对象的其他 synchronized 方法,毕竟一个对象只有一把锁,当一个线程获取了该对象的锁之后,其他线程无法获取该对象的锁,所以无法访问该对象的其他 synchronized 实例方法,但是其他线程还是可以访问该实例对象的其他非 synchronized 方法。
如果是一个线程 A 需要访问实例对象 obj1 的 synchronized 方法 f1(当前对象锁是 obj1),另一个线程 B 需要访问实例对象 obj2 的 synchronized 方法 f2(当前对象锁是 obj2),这样是允许的,因为两个实例对象锁并不同相同,此时如果两个线程操作数据并非共享的,线程安全是有保障的。
1 | public class AccountingSyncBad implements Runnable{ |
代码解释:
这段代码中创建了两个新实例:AccountingSyncBad
1 | //new新实例 |
然后启动两个不同的线程对共享变量 i 进行操作
1 | public synchronized void increase(){ |
但结果却不会是2000000,因为虽然我们使用 synchronized 修饰了 increase 方法,但却 new 了两个不同的实例对象,这也就意味着存在着两个不同的实例对象锁,因此 t1 和 t2 都会进入各自的对象锁,也就是说 t1 和 t2 线程使用的是不同的锁,因此线程安全是无法保证的
解决方案:
将 synchronized 作用于静态的 increase 方法,这样的话,对象锁就当前类对象,由于无论创建多少个实例对象,但对于的类对象拥有只有一个,所有在这样的情况下对象锁就是唯一的。
synchronized 作用于静态方法
修饰静态方法,作用于当前【类对象/class 对象】加锁,进入同步代码前要获得当前【类对象/class 对象】的锁
果一个线程 A 调用一个实例对象的非 static synchronized 方法,而线程 B 需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,是因为:
访问静态 synchronized 方法占用的锁是当前类的 class 对象
而访问非静态 synchronized 方法占用的锁是当前实例对象(this)
1 | public class AccountingSyncClass implements Runnable{ |
代码解释:
由于synchronized 关键字修饰的是静态increase方法,与修饰实例方法不同的是,其锁对象是当前类的 class 对象。注意代码中的increase4Obj方法是实例方法,其对象锁是当前实例对象,如果别的线程调用该方法,将不会产生互斥现象,毕竟锁对象不同,但我们应该意识到这种情况下可能会发现线程安全问题(操作了共享静态变量 i)。
synchronized 同步代码块
修饰代码块,指定加锁对象,对【给定对象(括号中的对象)】加锁,进入同步代码库前要获得【给定对象(括号中的对象)】的锁
- 使用场景
在某些情况下,我们编写的方法体可能比较大,同时存在一些比较耗时的操作,而需要同步的代码又只有一小部分,如果直接对整个方法进行同步操作,可能会得不偿失,此时我们可以使用同步代码块的方式对需要同步的代码进行包裹,这样就无需对整个方法进行同步操作了
1 | public class AccountingSync implements Runnable{ |
代码解释:
将 synchronized 作用于一个给定的实例对象 instance,即当前实例对象就是锁对象,每次当线程进入synchronized包裹的代码块时就会要求当前线程持有instance 实例对象锁,如果当前有其他线程正持有该对象锁,那么新到的线程就必须等待,这样也就保证了每次只有一个线程执行i++;操作。
另外一种写法,用this对象(代表当前实例)或者直接用当前类的 class 对象作为锁
1 | //this,当前实例对象锁 |
锁/锁优化
前言
在 Java 早期版本中,synchronized 属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,而操作系统实现线程之间的切换时需要从用户态转换到核心态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了,Java 6 之后,为了减少获得锁和释放锁所带来的性能消耗,引入了轻量级锁和偏向锁,接下来我们将简单了解一下 Java 官方在 JVM 层面对 synchronized 锁的优化。
概述
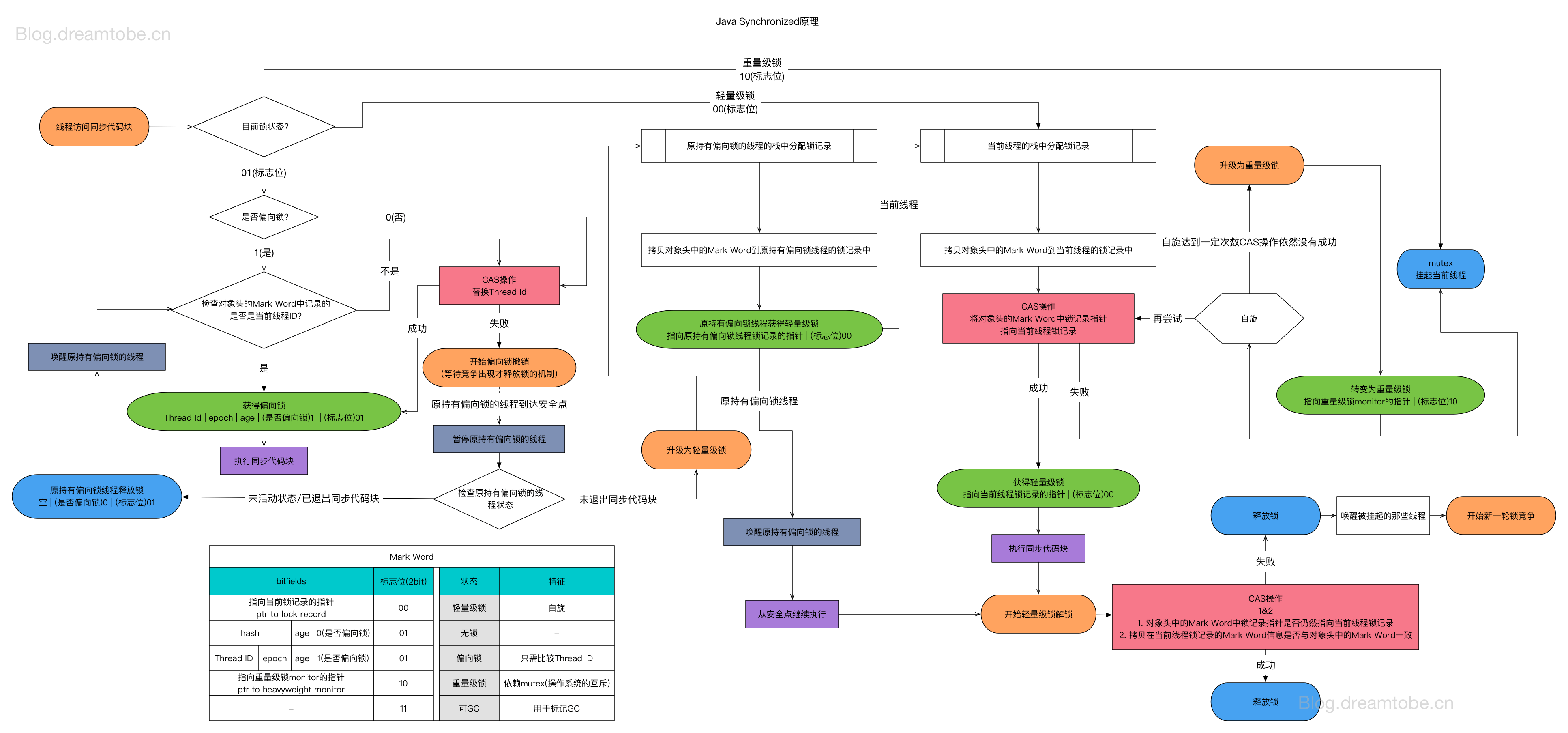
锁的状态总共有四种,无锁状态、偏向锁、轻量级锁和重量级锁。随着锁的竞争,锁可以从偏向锁升级到轻量级锁,再升级的重量级锁,但是锁的升级是单向的,也就是说只能从低到高升级,不会出现锁的降级,这种策略是为了提高获得锁和释放锁的效率
偏向锁
- 概述
向锁是 Java 6 之后加入的新锁,它是一种针对加锁操作的优化手段,经过研究发现,在大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得
1 | import java.util.ArrayList; |
在这个 demo 中为了保证对 list 操纵时线程安全,对 addString 方法加了synchronized的修饰,但实际使用时却只有一个线程调用到该方法,对于轻量级锁而言,每次调用 addString 时,加锁解锁都有一个 CAS 操作;对于重量级锁而言,加锁也会有一个或多个 CAS 操作。
因此为了减少同一线程获取锁(会涉及到一些 CAS 操作,耗时)的代价,或者说为了提高一个对象在一段很长的时间内都只被一个线程用做锁对象场景下的性能,我们引入了偏向锁。
- 思想
如果一个线程获得了锁,那么锁就进入偏向模式,此时 Mark Word 的结构也变为偏向锁结构,当这个线程再次请求锁时,无需再做任何同步操作,即获取锁的过程,这样就省去了大量有关锁申请的操作,从而也就提供程序的性能
- 具体执行
对象创建
当 JVM 启用了偏向锁模式(1.6 以上默认开启),当新创建一个对象的时候,如果该对象所属的 class 没有关闭偏向锁模式(默认所有 class 的偏向模式都是是开启的,可通过参数关闭),那新创建对象的
mark word将是可偏向状态,此时mark word中的thread id为0:表示未偏向任何线程,也叫做匿名偏向(anonymously biased)。加锁/获取锁过程
检测 Mark Word 是否为可偏向状态。即访问 Mark Word 中偏向锁的标识是否设置成 1,锁标志位是否为 01——确认为可偏向状态。
假如是可偏向状态,则测试线程 ID 是否指向当前线程,如果是,会往当前线程的栈中添加一条
Displaced Mark Word为空的Lock Record中,进入步骤(5);如果线程 ID 不指向当前线程,则进入步骤(3)。(当该对象第一次被线程获得锁的时候,发现是匿名偏向状态(即 thread id = 0),则会用 CAS 指令,将
mark word中的 thread id 由 0 改成当前线程 Id。如果成功,则代表获得了偏向锁,继续执行同步块中的代码。在以后只要不发生竞争,这个对象就归该线程所持有。失败的话,进入步骤(4))当被偏向的线程再次进入同步块时,操纵的是线程私有的栈,因此不需要用到 CAS 指令;由此可见偏向锁模式下,当被偏向的线程再次尝试获得锁时,仅仅进行几个简单的操作就可以了,在这种情况下,
synchronized关键字带来的性能开销基本可以忽略如果线程 ID 并未指向当前线程,则通过 CAS 操作竞争锁。如果竞争成功,则将 Mark Word 中线程 ID 设置为当前线程 ID(竞争成功的线程将获得偏向锁的所有权),然后执行(5);如果竞争失败,执行(4)。
【进行撤销偏向锁的操作】通过 CAS 竞争锁失败,证明当前存在多线程竞争情况,当到达全局安全点(safepoint),之前获得偏向锁的线程被挂起,对该线程进行状态判断。
- 若线程仍存活且还在同步块:锁升级为轻量级锁。
- 如果偏向的线程已经不存活或者不在同步块中:则将对象头的
mark word改为无锁状态(unlocked),偏向锁不升级,并且环形
执行同步代码块
由此可见:偏向锁升级的时机为:当锁已经发生偏向后,只要有另一个线程尝试获得偏向锁,则该偏向锁就会升级成轻量级锁。当然这个说法不绝对,因为还有批量重偏向这一机制。
解锁/偏向锁释放过程
偏向锁只有遇到其他线程尝试竞争偏向锁时,持有偏向锁的线程才会释放锁,线程不会主动去释放偏向锁。偏向锁的撤销,需要等待全局安全点
safe point(在这个时间点上没有字节码正在执行)- 它会首先暂停拥有偏向锁的线程,判断锁对象是否处于被锁定状态
- 撤销偏向锁后恢复到未锁定(标志位为“01”)或轻量级锁(标志位为“00”)的状态。
- 偏向锁的获取/解锁流程图解
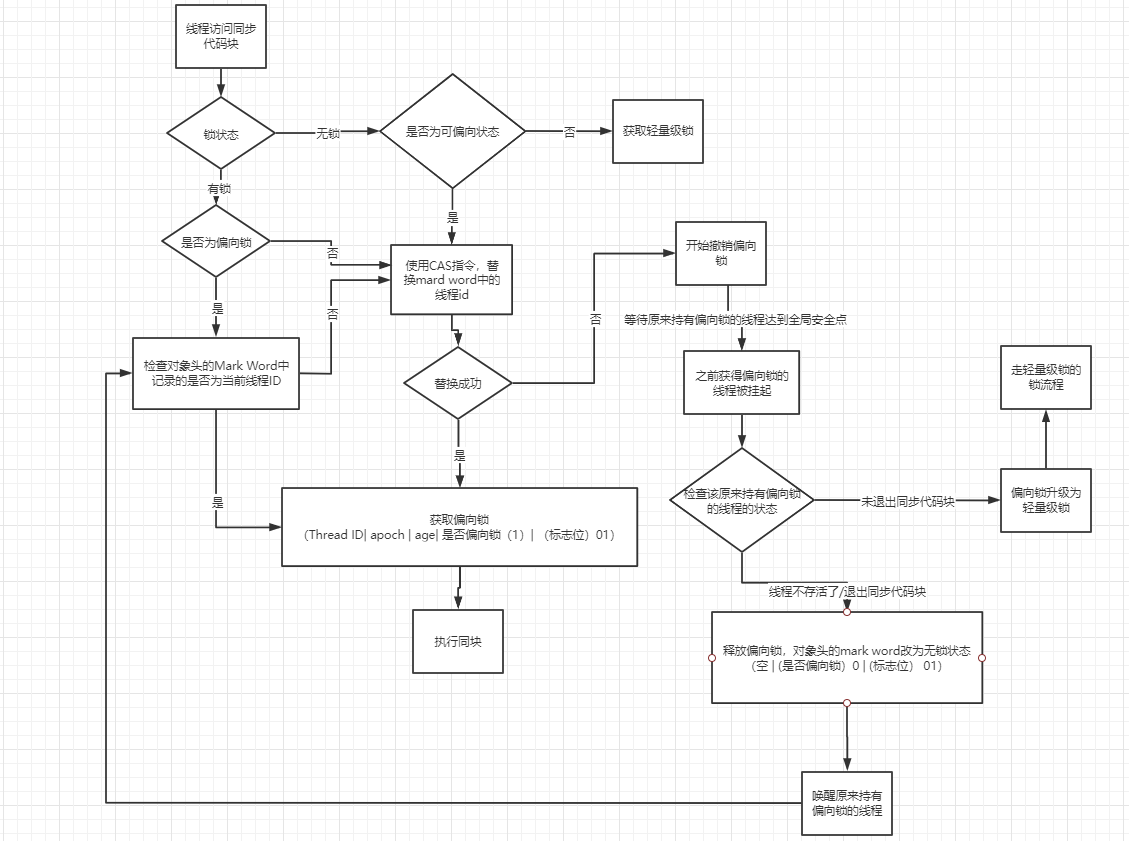
- 锁状态的转换流程
1)一个对象刚开始实例化的时候,没有任何线程来访问它的时候。它是可偏向的,意味着,它现在认为只可能有一个线程来访问它,所以当第一个线程来访问它的时候,它会偏向这个线程,此时,对象持有偏向锁。偏向第一个线程,这个线程在修改对象头成为偏向锁的时候使用 CAS 操作,并将对象头中的 ThreadID 改成自己的 ID,之后再次访问这个对象时,只需要对比 ID,不需要再使用 CAS 在进行操作。
2) 一旦有第二个线程访问这个对象,因为偏向锁不会主动释放,所以第二个线程可以看到对象时偏向状态,这时表明在这个对象上已经存在竞争了。检查原来持有该对象锁的线程是否依然存活,如果挂了,则可以将对象变为无锁状态,然后重新偏向新的线程。如果原来的线程依然存活,则马上执行那个线程的操作栈,检查该对象的使用情况,如果仍然需要持有偏向锁,则偏向锁升级为轻量级锁,(偏向锁就是这个时候升级为轻量级锁的),此时轻量级锁由原持有偏向锁的线程持有,继续执行其同步代码,而正在竞争的线程会进入自旋等待获得该轻量级锁;如果不存在使用了,则可以将对象回复成无锁状态,然后重新偏向。
3)轻量级锁认为竞争存在,但是竞争的程度很轻,一般两个线程对于同一个锁的操作都会错开,或者说稍微等待一下(自旋),另一个线程就会释放锁。 但是当自旋超过一定的次数,或者一个线程在持有锁,一个在自旋,又有第三个来访时,轻量级锁膨胀为重量级锁,重量级锁使除了拥有锁的线程以外的线程都阻塞,防止 CPU 空转。
批量重偏向与撤销
- 概述
对于偏向锁的加锁解锁过程,当只有一个线程反复进入同步块时,偏向锁带来的性能开销基本可以忽略,但是当有其他线程尝试获得锁时,就需要等到safe point时将偏向锁撤销为无锁状态或升级为轻量级/重量级锁。
想一想,如果说运行时的场景本身存在多线程竞争的,那偏向锁的存在不仅不能提高性能,而且会导致性能下降,那么有没有一种方法可以改变这种情况呢?JVM 替我们想到了这个问题的解决方案 —— 引入了批量重偏向/撤销的机制。
- 批量重偏向
一个线程创建了大量对象并执行了初始的同步操作,之后在另一个线程中将这些对象作为锁进行之后的操作。
举个例子:在不存在锁竞争的条件下,如果同一个类有 50 个对象偏向线程 t1,而线程 t2 又分别对这 50 个对象进行循环加锁,此时 t2 加锁的前 19 个对象会膨胀为轻量锁,等到第 20 个对象时,JVM 会预测这个类后面的所有对象都要偏向 t2,所以再加锁时,就不会执行锁膨胀了,而是重偏向到线程 t2。
具体实现
以 class 为单位,为每个 class 维护一个偏向锁撤销计数器,每一次该 class 的对象发生偏向撤销操作时,该计数器+1,当这个值达到重偏向阈值(默认 20)时,JVM 就认为该 class 的偏向锁有问题,因此会进行批量重偏向。每个 class 对象会有一个对应的epoch字段,每个处于偏向锁状态对象的mark word中也有该字段,其初始值为创建该对象时,class 中的epoch的值。每次发生批量重偏向时,就将该值+1,同时遍历 JVM 中所有线程的栈,找到该 class 所有正处于加锁状态的偏向锁,将其epoch字段改为新值。下次获得锁时,发现当前对象的epoch值和 class 的epoch不相等,那就算当前已经偏向了其他线程,也不会执行撤销操作,而是直接通过 CAS 操作将其mark word的 Thread Id 改成当前线程 Id。
- 批量撤销(批量撤销偏向锁)
存在明显多线程竞争的场景下使用偏向锁是不合适的,例如生产者/消费者队列。
举个例子:
假设有 80 个 A 类的对象实例,开始时全部偏向线程 t1,然后 t2 线程对第 1-40 个对象又进行了加锁处理
此时根据批量重定向机制,1-19个对象先是会膨胀为轻量级锁,退出同步块后变为无锁;
而第20-40个对象会因为触发批量重定向,锁状态变为偏向 t2 线程的偏向锁。
这时 t3 线程来了,它对第 21-43 个对象进行加锁处理(注意 t3 线程的前 20 个对象不能跟 t2 线程的前 20 个对象重合),这时由于 t2 线程撤销偏向锁撤销了 19 次(JVM 会按 20 次计算),t3 线程撤销偏向锁撤销了 19 次(JVM 会按 20 次计算),总共撤销的次数达到了 40 的阈值
此时 JVM 会判定为这个 A 类的对象有问题(不断的切换偏向线程会降低执行效率),从第 21-43,都会变为轻量级锁,不再进行重偏向操作,而且会对这个 A 类的对象关闭偏向的设置,即往后再 newA 类的对象时,不会进入偏向锁状态,只能走
无锁 - 轻量级锁 - 重量级锁的膨胀过程。所以批量撤销全称应该为:批量撤销偏向锁。
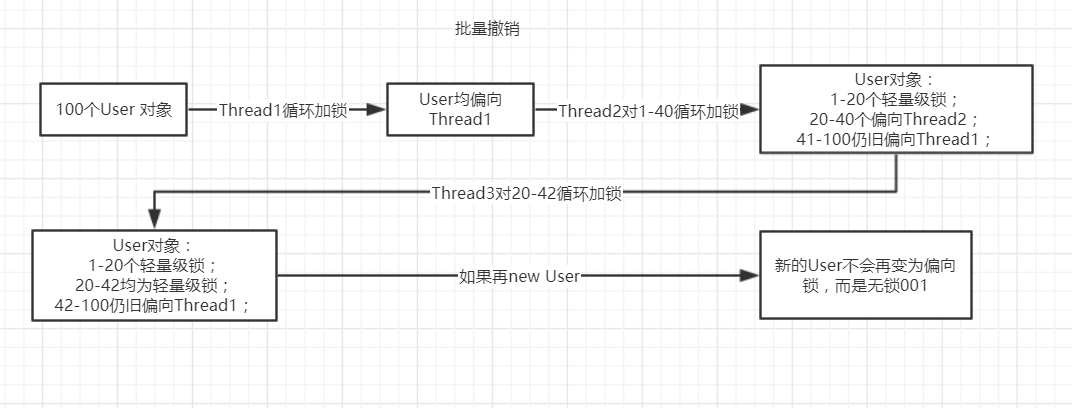
一言蔽之:当达到重偏向阈值(20)后,若 class 计数器还在继续增长,那么其达到批量撤销的阈值后(默认 40),JVM 认为该 class 的使用场景是存在多线程竞争的,就标记该 class 为不可偏向,之后,对于该 class 的锁,直接走轻量级锁的逻辑。
轻量级锁
- 背景
JVM 的开发者发现在很多情况下,在 Java 程序运行时,同步块中的代码都是不存在竞争的,即不同的线程交替的执行同步块中的代码。我们应该减少传统的重量级锁带来的性能消耗(重量级锁使用操作系统互斥量去实现同步)。
当关闭偏向锁功能或者多个线程竞争偏向锁将会导致偏向锁升级为轻量级锁
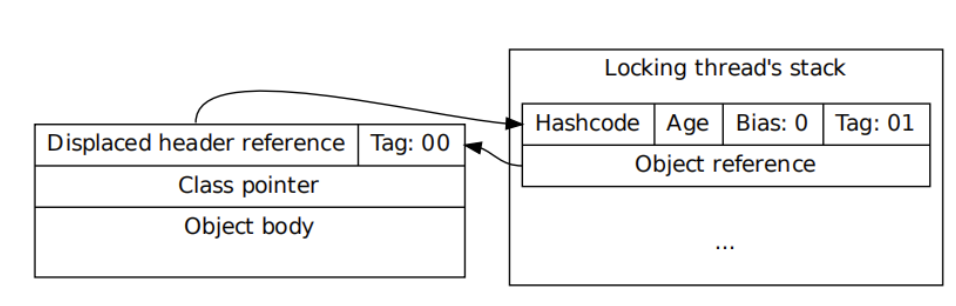
- Lock Record
线程在执行同步块之前,JVM 会先在当前的线程的栈帧中创建一个Lock Record,其包括一个用于存储对象头中的 mark word(官方称之为Displaced Mark Word)以及一个指向对象的指针。下图右边的部分就是一个Lock Record。
- 加锁过程
下列代码中:有 2 个方法同步代码块,利用同一个对象加锁
1 | static final Object obj = new Object(); |
创建锁记录(Lock Record)对象,每个线程的栈帧都会包含一个锁记录对象,内部可以存储锁定对象的 mark word(不再一开始就使用 Monitor)
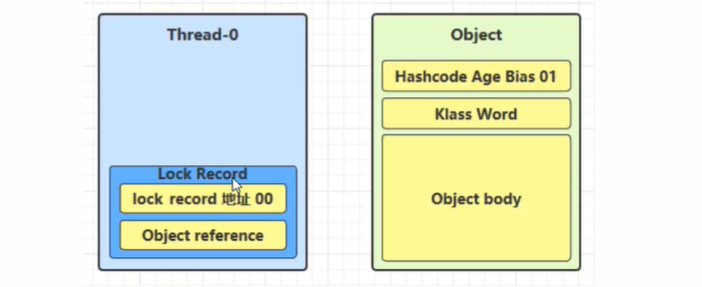
执行到
synchronized ( obj )后- 让
锁记录(Lock Record)中的 Object reference 指向锁对象(Object) - JVM 利用 CAS 去操作尝试用
Displaced Mark Word去替换对象头中的Mark Word如果成功了,就表示竞争到锁了,标志位从01更新为00(表示此对象处于轻量级锁状态)
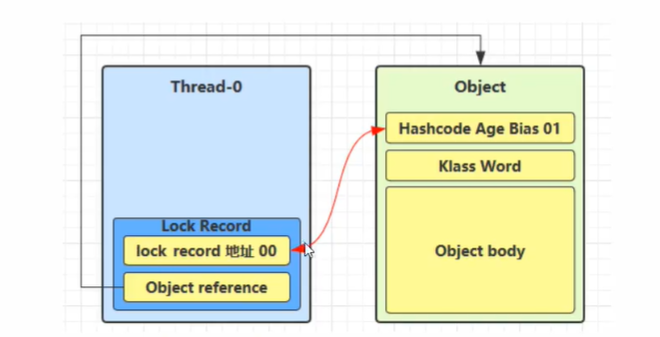
下图为 CAS 替换成功后的状态,对象头中存储了锁记录地址和状态 00,表示由该线程给对象加锁

- 让
假如 CAS 替换失败,则表示两种情况
若是其他线程已经持有了该Object的轻量级锁,就代表着有竞争,下面就进入锁膨胀过程
若是自己执行了
Synchronized锁重入,就设置Lock Record第一部分(Displaced Mark Word)为 null,起到了一个重入计数器的作用(即添加一条 Lock Record 作为重入的计数)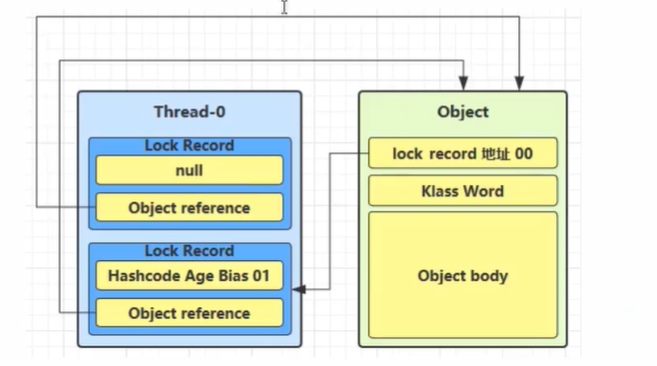
此时,将会发生锁膨胀(轻量级锁 升级为 重量级锁)
- 解锁过程
首先.遍历线程栈,找到所有
obj字段等于当前锁对象的Lock Record。如果
Lock Record的Displaced Mark Word为 null,代表这是一次重入,就重置锁记录(将obj设置为 null),表示重入计数 -1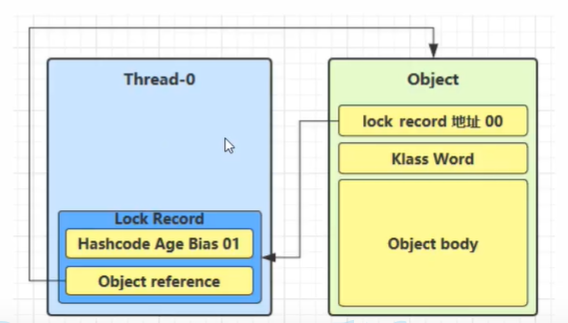
如果
Lock Record的Displaced Mark Word不为 null,则利用 CAS 指令将对象头的mark word恢复成为Displaced Mark Word。(这里也可以解释,为什么获得锁时,我们将
Lock Record中的Displaced Mark Word与对象头中的Mark Word进行交换操作了,在解锁的时候可以还原状态嘛)- 如果成功,则表示解锁成功
- 如果失败,说明轻量级锁进行锁膨胀/已经升级为重量级锁,就不能按照轻量级锁去办事,下面就会进入重量级锁解锁过程
- 轻量级锁的获取和释放过程
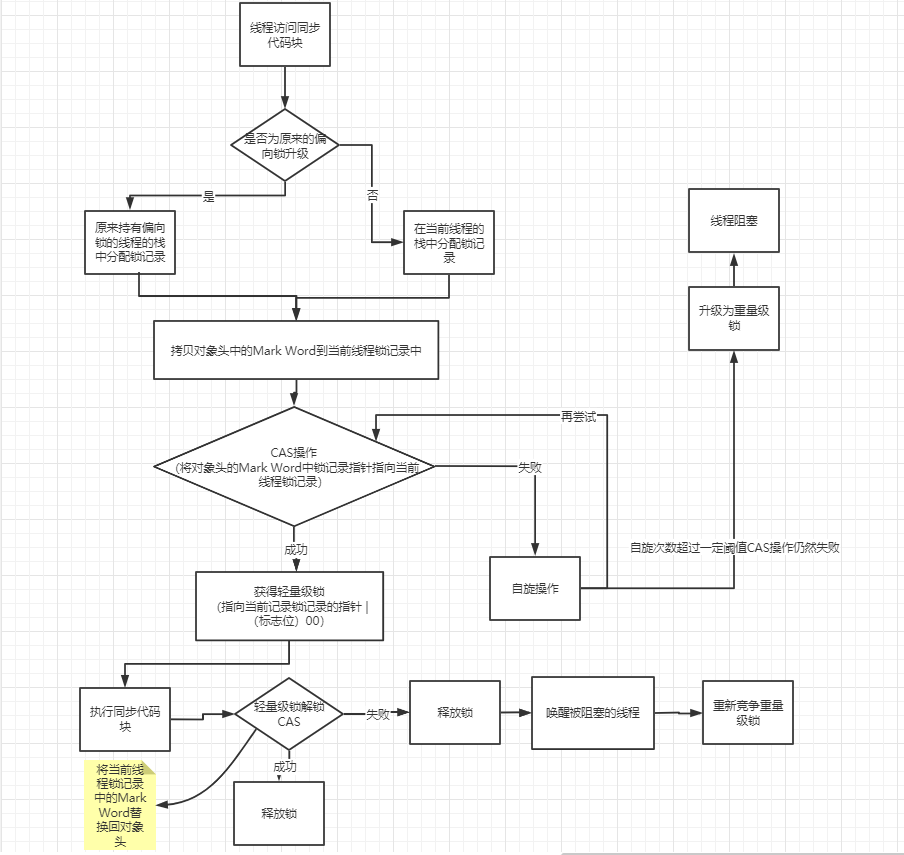
锁膨胀
在上述轻量级锁的获取步骤中,我们提及了一个锁膨胀的概念,其发生在其他线程为相同对象加上了轻量级锁,这个时候就需要进行锁膨胀了,即将轻量级锁升级为重量级锁
重量级锁是依赖对象内部的 monitor 锁来实现的,而 monitor 又依赖操作系统的 MutexLock(互斥锁)来实现的,所以重量级锁也被成为互斥锁。
而最为我们所熟知的重量级锁就是 Synchronized 了
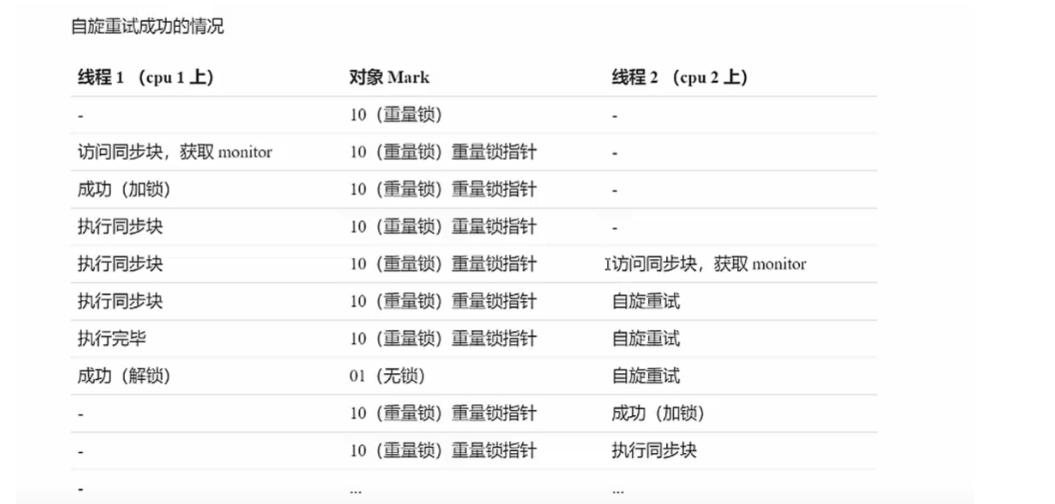
- 引入
如下图所示,T1 想要对对象进行轻量级加锁时,发现 T0 先它一步,已经给该对象加上了轻量级锁(发现后两位是 00)
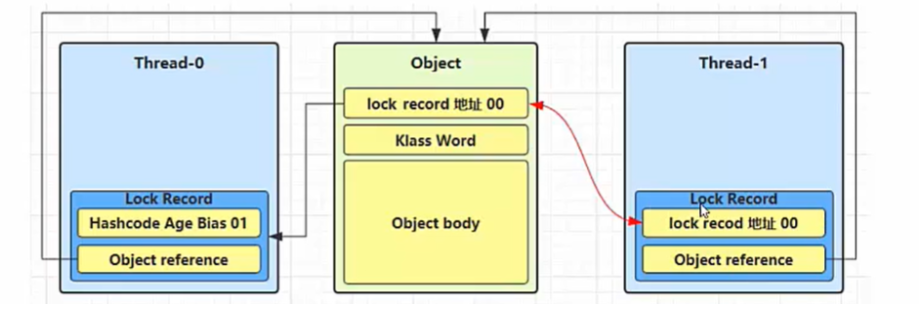
- 锁膨胀过程
以上述情况为例
获取锁
为 Objcet 对象申请
Monitor锁(最后两位改成 10),让 Object 指向重量级锁的地址接着 T1 线程进入
Monitor的*EnrtyList *发生阻塞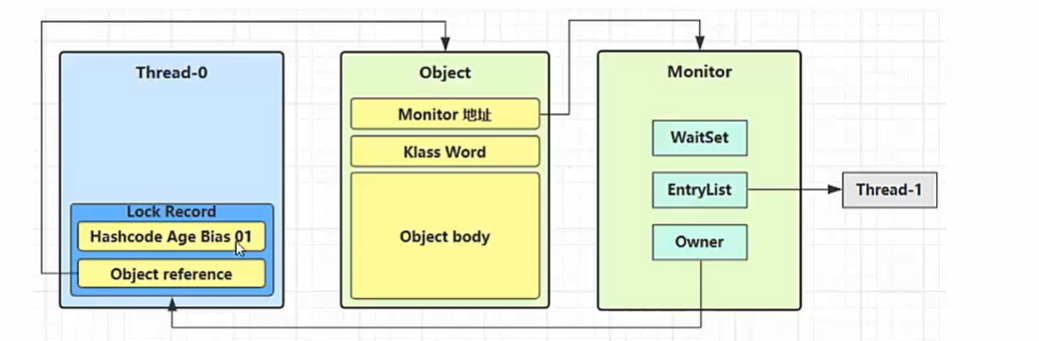
释放锁
当 T0 退出同步块进行解锁的时候,会使用CAS将Displaced Mark Word的值还原给对象头,但这一步能成功吗?不能,因为此时对象的后两位是 10,是重量级锁。之前轻量级锁那一套在这里不管用了,接下来就会进入重量级锁的解锁流程
- 首先按照 Monitor 的地址找到 Monitor 对象
- 设置 Owner 为 Null
- 唤醒EnrtyList中阻塞的线程
自旋锁
- 引入
由于线程的阻塞和唤醒需要 CPU 从用户态转为核心态,频繁的阻塞和唤醒对 CPU 来说是一件负担很重的工作,势必会给系统的并发性能带来很大的压力。而同时我们发现在许多应用上面,对象锁的锁状态只会持续很短一段时间,为了这一段很短的时间频繁地阻塞和唤醒线程是非常不值得的——因此我们引入了自旋锁
- 概述
所谓自旋锁,就是让该线程等待一段时间,不会被立即挂起,看持有锁的线程是否会很快释放锁。怎么等待呢?执行一段无意义的循环即可(自旋)。
使用场景:当重量级锁竞争的时候可以使用自旋进行优化处理,如果当前线程自旋成功了(即这时候持锁的线程已经退出了同步块,释放了锁 ),这个时候当前的线程就可以避免阻塞,减少 CPU 切换,提高系统并发性。
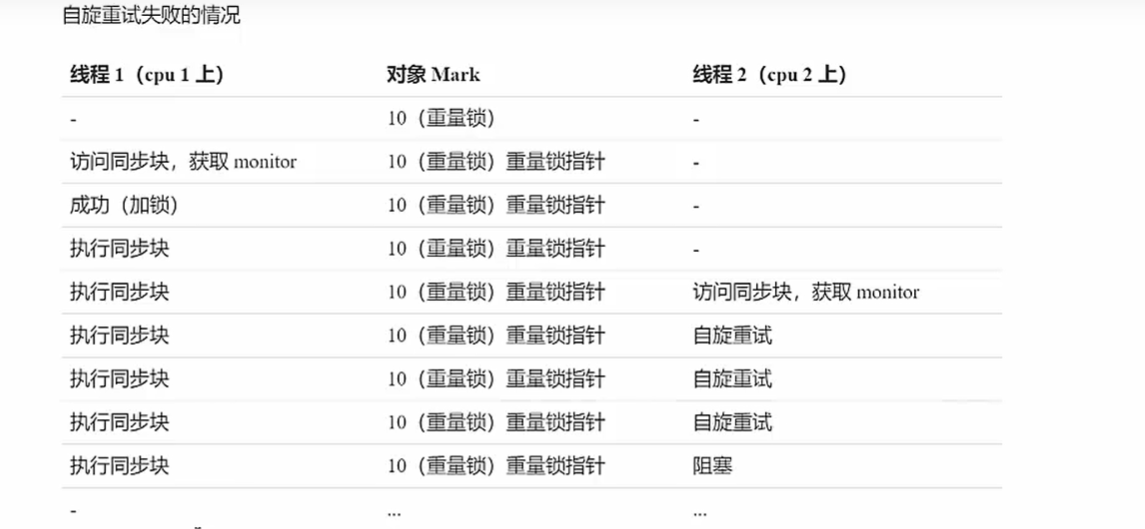
- 自旋成功情况
- 自旋失败情况
- 注意点
自旋等待不能替代阻塞。虽然它可以避免线程切换带来的开销,但是它占用了处理器的时间。如果持有锁的线程很快就释放了锁,那么自旋的效率就非常好,反之,自旋的线程就会白白消耗掉处理的资源,它不会做任何有意义的工作。(占有处理器,却不做任何事)。这会带来性能上的浪费。
因此,自旋不能无限自旋,自旋的次数必须要有一个限度,如果自旋超过了定义的时间仍然没有获取到锁,则应该被挂起。
自旋是会占用处理机的时间的,自旋的思想是先等待一下,让执行同步块的线程跑一下,看看自旋后的线程能不能过会能不能用上处理机,因此单核 CPU 使用自旋有意义吗?没有。因此单核 CPU 自旋就是浪费,只有多核 CPU 自旋才能够发挥优势
自旋锁在 JDK 1.4.2 中引入,默认关闭,但是可以使用-XX:+UseSpinning 开开启,在 JDK1.6 中默认开启。同时自旋的默认次数为 10 次,可以通过参数-XX:PreBlockSpin 来调整
适应自旋锁
- 引入
在学习自旋锁相关知识时,我们发现:如果通过参数-XX:preBlockSpin 来调整自旋锁的自旋次数,会带来诸多不便。假如我将参数调整为 10,但是系统很多线程都是等你刚刚退出的时候就释放了锁(假如你多自旋一两次就可以获取锁),这种情况就显得我们很蠢。
于是 JDK1.6 引入自适应的自旋锁,让虚拟机会变得越来越聪明。
- 概述
所谓自适应就意味着自旋的次数不再是固定的,它是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。它怎么做呢?线程如果自旋成功了,那么下次自旋的次数会更加多,因为虚拟机认为既然上次成功了,那么此次自旋也很有可能会再次成功,那么它就会允许自旋等待持续的次数更多。反之,如果对于某个锁,很少有自旋能够成功的,那么在以后要或者这个锁的时候自旋的次数会减少甚至省略掉自旋过程,以免浪费处理器资源。
有了自适应自旋锁,随着程序运行和性能监控信息的不断完善,虚拟机对程序锁的状况预测会越来越准确,虚拟机会变得越来越聪明。
锁转换流程图
锁消除
- 概述
为了保证数据的完整性,我们在进行操作时需要对这部分操作进行同步控制,但是在有些情况下,JVM 检测到不可能存在共享数据竞争,这是 JVM 会对这些同步锁进行锁消除;
- 依据
锁消除的依据是逃逸分析的数据支持。这也是 jvm 的语法糖的一种,是编译器的一种优化措施。
锁消除可以节省毫无意义的请求锁的时间。变量是否逃逸,对于虚拟机来说需要使用数据流分析来确定。
- 例子
有时候,我们虽然没有显示使用锁,但是我们在使用一些 JDK 的内置 API 时,如 StringBuffer、Vector、HashTable 等,这个时候会存在隐形的加锁操作。比如 StringBuffer 的 append()方法,Vector 的 add()方法:
1 | public void vectorTest(){ |
在运行这段代码时,JVM 可以明显检测到变量 vector 没有逃逸出方法 vectorTest()之外,所以 JVM 可以大胆地将 vector 内部的加锁操作消除。
锁粗化
- 概述
我们知道在使用同步锁的时候,需要让同步块的作用范围尽可能小,即仅在共享数据的实际作用域中才进行同步,这样做的目的是为了使需要同步的操作数量尽可能缩小,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
大部分情况下,这些都是正确的。但是,如果一些列的联系操作都是同一个对象反复加上和解锁,甚至加锁操作是出现在循环体中的,那么即使没有线程竞争,频繁地进行互斥同步操作也导致不必要的性能损耗。
- 例子
类似锁消除的concatString()方法。如果StringBuffer sb = new StringBuffer();定义在方法体之外,那么就会有线程竞争,但是每个 append()操作都对同一个对象反复加锁解锁,那么虚拟机探测到有这样的情况的话,会把加锁同步的范围扩展到整个操作序列的外部,即扩展到【第一个 append()操作之前和最后一个 append()操作之后】,这样的一个锁范围扩展的操作就称之为锁粗化。
用上述的锁消除的代码为例的话:
JVM 检测到对同一个对象(vector)连续加锁、解锁操作,会合并一个更大范围的加锁、解锁操作,即加锁解锁操作会移到 for 循环之外。
- 总结
将多个连续的加锁、解锁操作连接在一起,扩展成一个范围更大的锁
final
final 基础
final 基础在 java 基础部分有学习过:https://uesugier11.gitee.io/uesugi-er11/2020/11/14/Java%E5%9F%BA%E7%A1%80/#final
多线程中的 final
final 域重排序规则
final 域为基本类型
先看一段示例性的代码:
1 | public class FinalDemo { |
假设线程 A 在执行 writer()方法,线程 B 执行 reader()方法。
写 final 域重排序规则
写 final 域的重排序规则禁止对 final 域的写重排序到构造函数之外,这个规则的实现主要包含了两个方面:
- JMM 禁止编译器把 final 域的写重排序到构造函数之外;
- 编译器会在 final 域写之后,构造函数 return 之前,插入一个 storestore 屏障(关于内存屏障可以看这篇文章)。这个屏障可以禁止处理器把 final 域的写重排序到构造函数之外。
我们再来分析 writer 方法,虽然只有一行代码,但实际上做了两件事情:
- 构造了一个 FinalDemo 对象;
- 把这个对象赋值给成员变量 finalDemo。
我们来画下存在的一种可能执行时序图,如下:
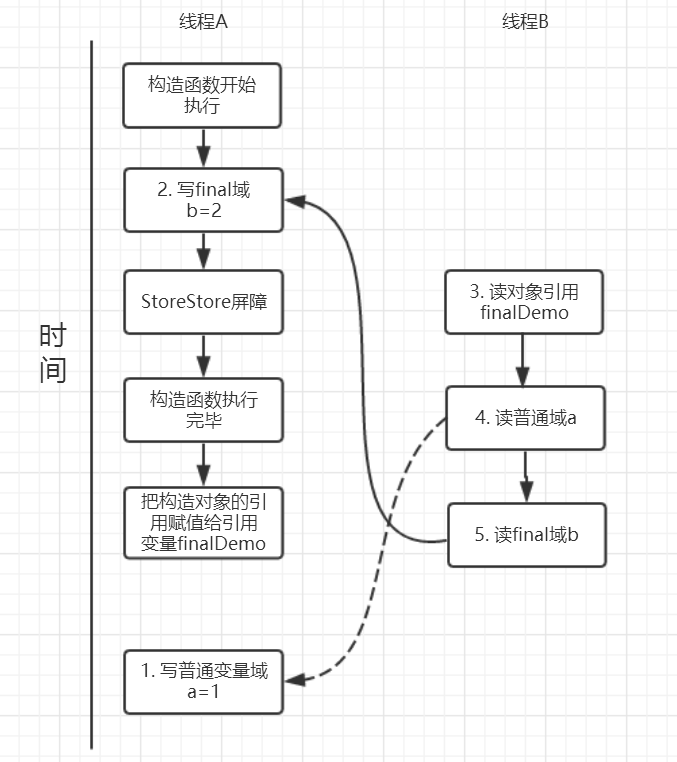
由于 a,b 之间没有数据依赖性,普通域(普通变量)a 可能会被重排序到构造函数之外,线程 B 就有可能读到的是普通变量 a 初始化之前的值(零值),这样就可能出现错误。而 final 域变量 b,根据重排序规则,会禁止 final 修饰的变量 b 重排序到构造函数之外,从而 b 能够正确赋值,线程 B 就能够读到 final 变量初始化后的值。
因此,写 final 域的重排序规则可以确保:在对象引用为任意线程可见之前,对象的 final 域已经被正确初始化过了,而普通域就不具有这个保障。比如在上例,线程 B 有可能就是一个未正确初始化的对象 finalDemo。
读 final 域重排序规则
读 final 域重排序规则为:在一个线程中,初次读对象引用和初次读该对象包含的 final 域,JMM 会禁止这两个操作的重排序。(注意,这个规则仅仅是针对处理器),处理器会在读 final 域操作的前面插入一个 LoadLoad 屏障。实际上,读对象的引用和读该对象的 final 域存在间接依赖性,一般处理器不会重排序这两个操作。但是有一些处理器会重排序,因此,这条禁止重排序规则就是针对这些处理器而设定的。
read()方法主要包含了三个操作:
- 初次读引用变量 finalDemo;
- 初次读引用变量 finalDemo 的普通域 a;
- 初次读引用变量 finalDemo 的 final 域 b;
假设线程 A 写过程没有重排序,那么线程 A 和线程 B 有一种的可能执行时序为下图:
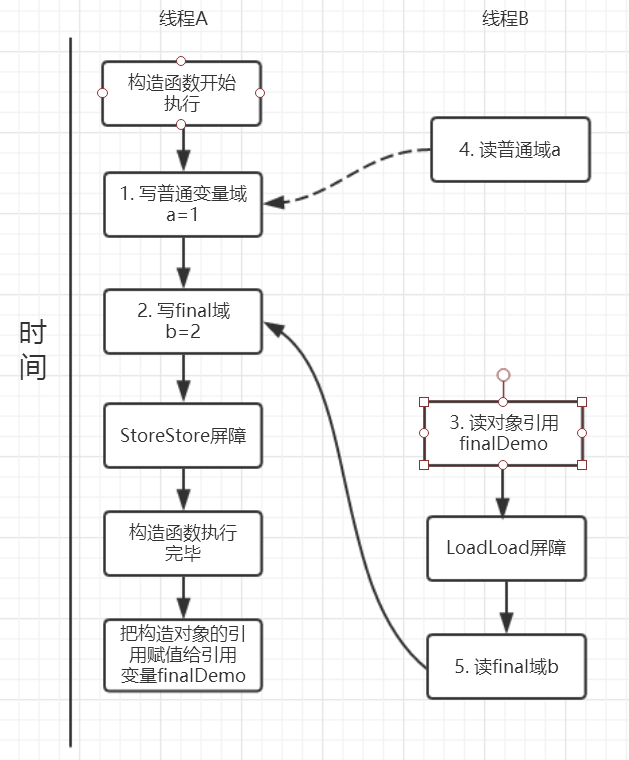
读对象的普通域被重排序到了读对象引用的前面就会出现线程 B 还未读到对象引用就在读取该对象的普通域变量,这显然是错误的操作。而 final 域的读操作就“限定”了在读 final 域变量前已经读到了该对象的引用,从而就可以避免这种情况。
读 final 域的重排序规则可以确保:在读一个对象的 final 域之前,一定会先读这个包含这个 final 域的对象的引用。
final 域为引用类型
我们已经知道了 final 域是基本数据类型的时候重排序规则是怎么的了?如果是引用数据类型呢?我们接着继续来探讨。
对 final 修饰的对象的成员域写操作
针对引用数据类型,final 域写针对编译器和处理器重排序增加了这样的约束:在构造函数内对一个 final 修饰的对象的成员域的写入,与随后在构造函数之外把这个被构造的对象的引用赋给一个引用变量,这两个操作是不能被重排序的。注意这里的是“增加”也就说前面对 final 基本数据类型的重排序规则在这里还是使用。这句话是比较拗口的,下面结合实例来看。
1 | public class FinalReferenceDemo { |
针对上面的实例程序,线程线程 A 执行 wirterOne 方法,执行完后线程 B 执行 writerTwo 方法,然后线程 C 执行 reader 方法。下图就以这种执行时序出现的一种情况来讨论(耐心看完才有收获)。
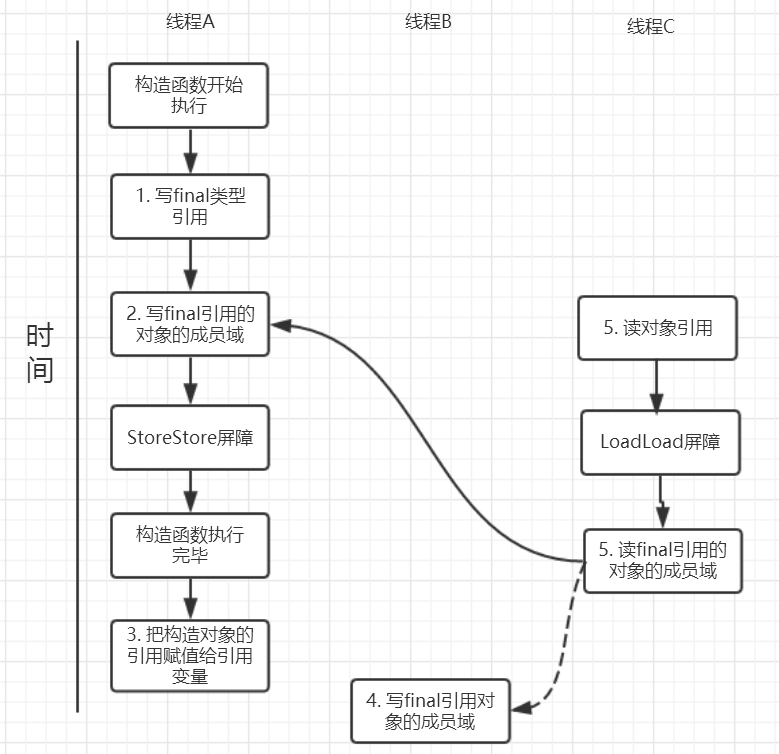
由于对 final 域的写禁止重排序到构造方法外,因此 1 和 3 不能被重排序。由于一个 final 域的引用对象的成员域写入不能与随后将这个被构造出来的对象赋给引用变量重排序,因此 2 和 3 不能重排序。
对 final 修饰的对象的成员域读操作
JMM 可以确保线程 C 至少能看到写线程 A 对 final 引用的对象的成员域的写入,即能看下 arrays[0] = 1,而写线程 B 对数组元素的写入可能看到可能看不到。JMM 不保证线程 B 的写入对线程 C 可见,线程 B 和线程 C 之间存在数据竞争,此时的结果是不可预知的。如果可见的,可使用锁或者 volatile。
关于 final 重排序的总结
按照 final 修饰的数据类型分类:
基本数据类型:
- final 域写:禁止final 域写与构造方法重排序,即禁止 final 域写重排序到构造方法之外,从而保证该对象对所有线程可见时,该对象的 final 域全部已经初始化过。
- final 域读:禁止初次读对象的引用与读该对象包含的 final 域的重排序。
引用数据类型:
额外增加约束:禁止在构造函数对一个 final 修饰的对象的成员域的写入与随后将这个被构造的对象的引用赋值给引用变量 重排序
final 实现原理
上面我们提到过,写 final 域会要求编译器在 final 域写之后,构造函数返回前插入一个 StoreStore 屏障。读 final 域的重排序规则会要求编译器在读 final 域的操作前插入一个 LoadLoad 屏障。
很有意思的是,如果以 X86 处理为例,X86 不会对写-写重排序,所以StoreStore 屏障可以省略。由于不会对有间接依赖性的操作重排序,所以在 X86 处理器中,读 final 域需要的LoadLoad 屏障也会被省略掉。也就是说,以 X86 为例的话,对 final 域的读/写的内存屏障都会被省略!具体是否插入还是得看是什么处理器
为什么 final 引用不能从构造函数中 “逸出”
这里还有一个比较有意思的问题:上面对 final 域写重排序规则可以确保我们在使用一个对象引用的时候该对象的 final 域已经在构造函数被初始化过了。但是这里其实是有一个前提条件的,也就是:在构造函数,不能让这个被构造的对象被其他线程可见,也就是说该对象引用不能在构造函数中“逸出”。以下面的例子来说:
1 | public class FinalReferenceEscapeDemo { |
可能的执行时序如图所示:
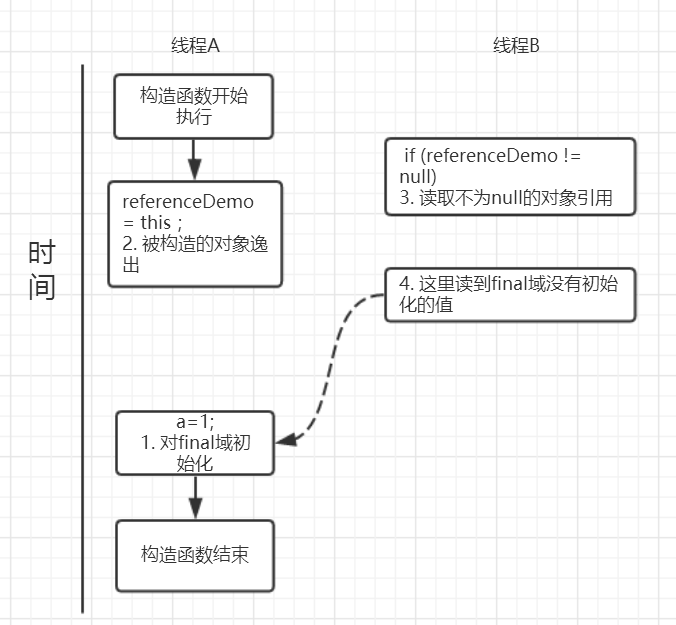
假设一个线程 A 执行 writer 方法另一个线程执行 reader 方法。因为构造函数中操作 1 和 2 之间没有数据依赖性,1 和 2 可以重排序,先执行了 2,这个时候引用对象 referenceDemo 是个没有完全初始化的对象,而当线程 B 去读取该对象时就会出错。尽管依然满足了 final 域写重排序规则:在引用对象对所有线程可见时,其 final 域已经完全初始化成功。但是,引用对象“this”逸出,该代码依然存在线程安全的问题。
Lock 体系
cocurrent 包结构层次
在针对并发编程中,Doug Lea 大师为我们提供了大量实用,高性能的工具类,针对这些代码进行研究会让我们队并发编程的掌握更加透彻也会大大提升我们队并发编程技术的热爱。这些代码在 java.util.concurrent 包下。如下图,即为 concurrent 包的目录结构图。
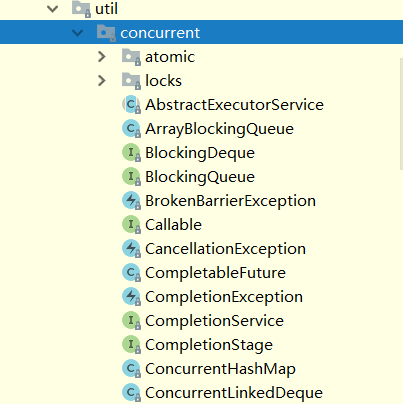
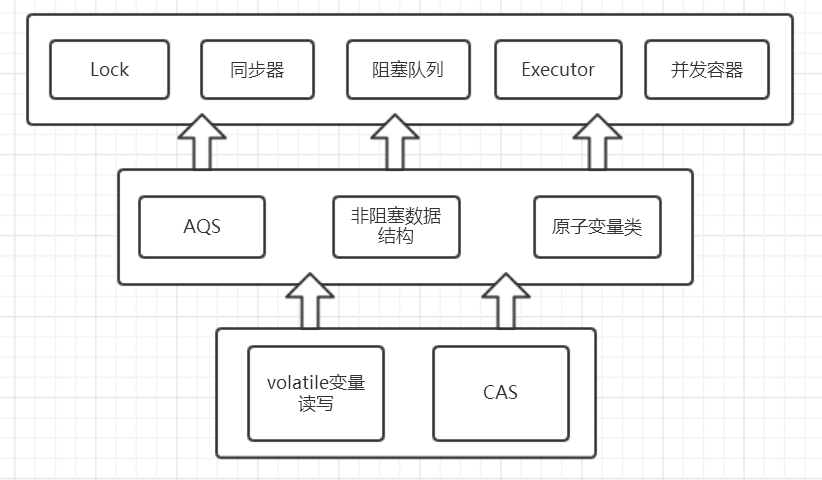
其中包含了两个子包:atomic 以及 lock,另外在 concurrent 下的阻塞队列以及 executors,这些就是 concurrent 包中的精华,之后会一一进行学习。而这些类的实现主要是依赖于 volatile 以及 CAS,从整体上来看 concurrent 包的整体实现图如下图所示:
Lock 简介
我们下来看 concurent 包下的 lock 子包。锁是用来控制多个线程访问共享资源的方式,一般来说,一个锁能够防止多个线程同时访问共享资源。
在 Lock 接口出现之前,java 程序主要是靠synchronized关键字实现锁功能的,而 java SE5 之后,并发包中增加了 lock 接口,它提供了与 synchronized 一样的锁功能。
虽然它失去了像 synchronize 关键字隐式加锁解锁的便捷性,但是却拥有了锁获取和释放的可操作性,可中断的获取锁以及超时获取锁等多种 synchronized 关键字所不具备的同步特性。通常使用显示使用 lock 的形式如下:
1 | Lock lock = new ReentrantLock(); |
需要注意的是synchronized 同步块执行完成或者遇到异常是锁会自动释放,而 lock 必须调用 unlock()方法释放锁,因此在 finally 块中释放锁。
Lock 接口 API
我们现在就来看看 lock 接口定义了哪些方法:
void lock(); //获取锁
void lockInterruptibly() throws InterruptedException;//获取锁的过程能够响应中断
boolean tryLock();//非阻塞式响应中断能立即返回,获取锁放回 true 反之返回 fasle
boolean tryLock(long time, TimeUnit unit) throws InterruptedException;//超时获取锁,在超时内或者未中断的情况下能够获取锁
Condition newCondition();//获取与 lock 绑定的等待通知组件,当前线程必须获得了锁才能进行等待,进行等待时会先释放锁,当再次获取锁时才能从等待中返回
上面是 lock 接口下的五个方法,也只是从源码中英译中翻译了一遍,感兴趣的可以自己的去看看。那么在 locks 包下有哪些类实现了该接口了?先从最熟悉的 ReentrantLock 说起。
public class ReentrantLock implements Lock, java.io.Serializable
很显然 ReentrantLock 实现了 lock 接口,接下来我们来仔细研究一下它是怎样实现的。
当你查看源码时你会惊讶的发现 ReentrantLock 并没有多少代码,另外有一个很明显的特点是:基本上所有的方法的实现实际上都是调用了其静态内存类Sync中的方法,而 Sync 类继承了AbstractQueuedSynchronizer(AQS)。
可以看出要想理解 ReentrantLock 关键核心在于对队列同步器 AbstractQueuedSynchronizer(简称同步器)的理解。
AbstractQueuedSynchronizer(AQS)
简介
- AQS - 抽象 队列 同步器;简称同步器
关于 AQS 在源码中有十分具体的解释:
Provides a framework for implementing blocking locks and related
synchronizers (semaphores, events, etc) that rely on
first-in-first-out (FIFO) wait queues. This class is designed to
be a useful basis for most kinds of synchronizers that rely on a
single atomic {@code int} value to represent state. Subclasses
must define the protected methods that change this state, and which
define what that state means in terms of this object being acquired
or released. Given these, the other methods in this class carry
out all queuing and blocking mechanics. Subclasses can maintain
other state fields, but only the atomically updated {@code int}
value manipulated using methods {@link #getState}, {@link
#setState} and {@link #compareAndSetState} is tracked with respect
to synchronization.
<p>Subclasses should be defined as non-public internal helper
classes that are used to implement the synchronization properties
of their enclosing class. Class
{@code AbstractQueuedSynchronizer} does not implement any
synchronization interface. Instead it defines methods such as
{@link #acquireInterruptibly} that can be invoked as
appropriate by concrete locks and related synchronizers to
implement their public methods.同步器是用来构建锁和其他同步组件的基础框架
- 它的实现方式(同步状态 + 等待队列)
- 依赖一个 int 成员变量来表示同步状态
- 再通过一个FIFO 队列构成等待队列。
它的子类必须重写 AQS 的几个 protected 修饰的用来改变同步状态的方法,其他方法主要是实现了排队和阻塞机制。
状态的更新使用 getState,setState 以及 compareAndSetState(也就是我们常说的CAS)这三个方法。
子类被推荐定义为自定义同步组件的静态内部类,同步器自身没有实现任何同步接口,它仅仅是定义了若干同步状态的获取和释放方法来供自定义同步组件的使用,同步器既支持独占式获取同步状态,也可以支持共享式获取同步状态,这样就可以方便的实现不同类型的同步组件。
同步器是实现锁(也可以是任意同步组件)的关键,在锁的实现中聚合同步器,利用同步器实现锁的语义。
- 理解二者的关系
锁是面向【使用者】,它定义了使用者与锁交互的接口,隐藏了实现细节;同步器是面向锁的【实现者】,它简化了锁的实现方式,屏蔽了同步状态的管理,线程的排队,等待和唤醒等底层操作。锁和同步器很好的隔离了使用者和实现者所需关注的领域。
AQS 模板方法设计模式
- AQS 的设计是使用【模板方法设计模式】,它将一些方法开放给子类进行重写,而同步器给同步组件所提供模板方法又会重新调用被子类所重写的方法
举个例子,AQS 中需要重写的方法 tryAcquire:
1 | protected boolean tryAcquire(int arg) { |
ReentrantLock 中 NonfairSync(继承 AQS,本质是一个锁)会重写该方法为:
1 | protected final boolean tryAcquire(int acquires) { |
而 AQS 中的模板方法 acquire():
1 | public final void acquire(int arg) { |
会调用 tryAcquire 方法,而此时当继承 AQS 的 NonfairSync 调用模板方法 acquire 时就会调用已经被 NonfairSync 重写的 tryAcquire 方法。这就是使用 AQS 的方式,在弄懂这点后会 lock 的实现理解有很大的提升。
- 总结
可以归纳总结为这么几点:
- 同步组件(这里不仅仅指锁,还包括 CountDownLatch 等)的实现依赖于同步器 AQS,在同步组件实现中,使用 AQS 的方式被推荐定义继承 AQS 的静态内存类;
- AQS 采用模板方法进行设计,AQS 的 protected 修饰的方法需要由继承 AQS 的子类进行重写实现,当调用 AQS 的子类的方法时就会调用被重写的方法;
- AQS 负责同步状态的管理,线程的排队,等待和唤醒这些底层操作,而 Lock 等同步组件主要专注于实现同步语义;
- 在重写 AQS 的方式时,使用 AQS 提供的
getState(),setState(),compareAndSetState()方法进行修改同步状态
AQS 可重写的方法如下图(摘自《java 并发编程的艺术》一书):
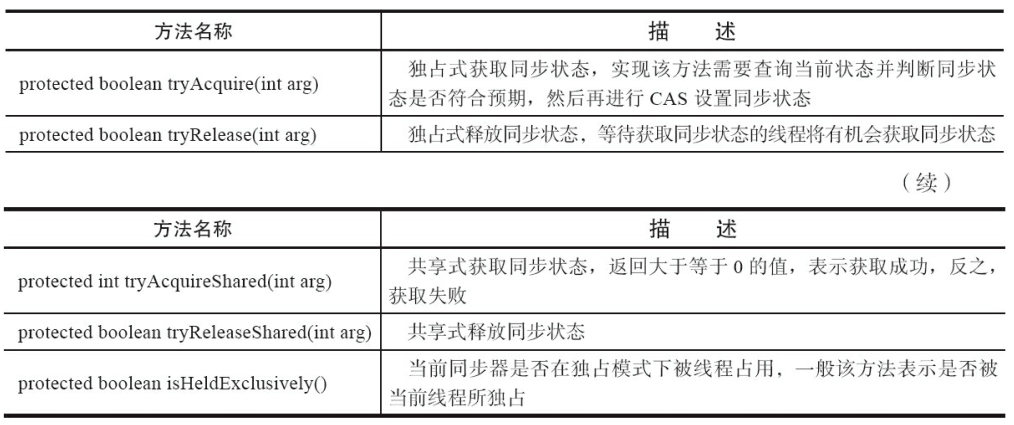
在实现同步组件时 AQS 提供的模板方法如下图:
AQS 提供的模板方法可以分为 3 类:
- 独占式获取与释放同步状态;
- 共享式获取与释放同步状态;
- 查询同步队列中等待线程情况;
同步组件通过 AQS 提供的模板方法实现自己的同步语义。
AQS 底层细节
AQS 模板方法
在同步组件的实现中,AQS 是核心部分,同步组件的实现者通过使用 AQS 提供的模板方法实现同步组件语义,AQS 则实现了对同步状态的管理,以及对阻塞线程进行排队,等待通知等等一些底层的实现处理。
AQS 的核心也包括了这些方面:同步队列,独占式锁的获取和释放,共享锁的获取和释放以及可中断锁,超时等待锁获取这些特性的实现,而这些实际上则是 AQS 提供出来的模板方法,归纳整理如下:
独占式锁:
void acquire(int arg):独占式获取同步状态,如果获取失败则插入同步队列进行等待;
void acquireInterruptibly(int arg):与 acquire 方法相同,但在同步队列中进行等待的时候可以检测中断;
boolean tryAcquireNanos(int arg, long nanosTimeout):在 acquireInterruptibly 基础上增加了超时等待功能,在超时时间内没有获得同步状态返回 false;
boolean release(int arg):释放同步状态,该方法会唤醒在同步队列中的下一个节点
共享式锁:
void acquireShared(int arg):共享式获取同步状态,与独占式的区别在于同一时刻有多个线程获取同步状态;
void acquireSharedInterruptibly(int arg):在 acquireShared 方法基础上增加了能响应中断的功能;
boolean tryAcquireSharedNanos(int arg, long nanosTimeout):在 acquireSharedInterruptibly 基础上增加了超时等待的功能;
boolean releaseShared(int arg):共享式释放同步状态
要想掌握 AQS 的底层实现,其实也就是对这些模板方法的逻辑进行学习。在学习这些模板方法之前,我们得首先了解下 AQS 中的同步队列是一种什么样的数据结构,因为同步队列是 AQS 对同步状态的管理的基石。
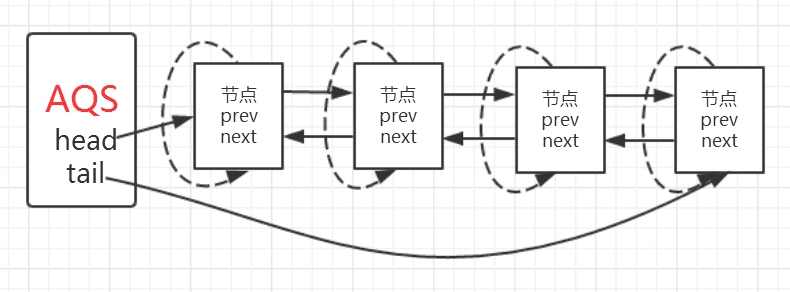
同步队列
当共享资源被某个线程占有,其他请求该资源的线程将会阻塞,从而进入同步队列。
就数据结构而言,队列的实现方式无外乎两者一是通过数组的形式,另外一种则是链表的形式。AQS 中的同步队列则是通过链式方式进行实现。接下来,很显然我们至少会抱有这样的疑问:
- 节点的数据结构是什么样的?
- 是单向还是双向?
- 是带头结点的还是不带头节点的?
- Node 类 属性
在 AQS 有一个静态内部类 Node,其中有这样一些属性:
volatile int waitStatus //节点状态
volatile Node prev //当前节点/线程的前驱节点
volatile Node next; //当前节点/线程的后继节点
volatile Thread thread;//加入同步队列的线程引用
Node nextWaiter;//等待队列中的下一个节点
- 节点状态
节点的状态有以下这些:
int CANCELLED = 1//节点从同步队列中取消
int SIGNAL = -1//后继节点的线程处于等待状态,如果当前节点释放同步状态会通知后继节点,使得后继节点的线程能够运行;
int CONDITION = -2//当前节点进入等待队列中
int PROPAGATE = -3//表示下一次共享式同步状态获取将会无条件传播下去
int INITIAL = 0;//初始状态
现在我们知道了节点的数据结构类型,并且每个节点拥有其前驱和后继节点,很显然这是一个双向队列。
同样的我们可以用一段 demo 看一下:
1 | public class LockDemo { |
实例代码中开启了 5 个线程,先获取锁之后再睡眠 10S 中,实际上这里让线程睡眠是想模拟出当线程无法获取锁时进入同步队列的情况。
通过 debug,当 Thread-4(在本例中最后一个线程)获取锁失败后进入同步时,AQS 时现在的同步队列如图所示:
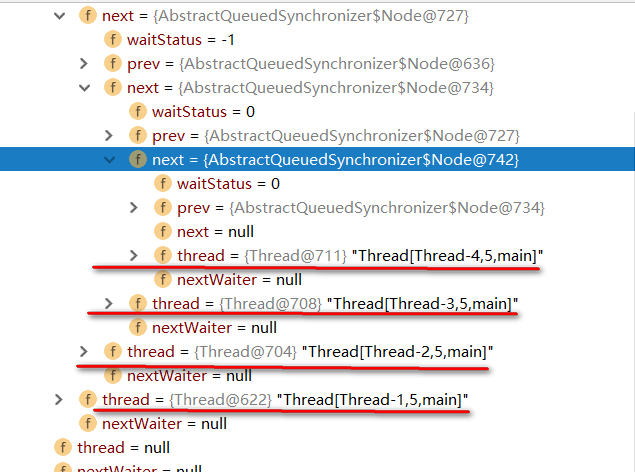
Thread-0 先获得锁后进行睡眠,其他线程(Thread-1,Thread-2,Thread-3,Thread-4)获取锁失败进入同步队列,同时也可以很清楚的看出来每个节点有两个域:prev(前驱)和 next(后继),并且每个节点用来保存获取同步状态失败的线程引用以及等待状态等信息。
另外 AQS 中有两个重要的成员变量:
1 | //头指针 |
也就是说 AQS 实际上通过头尾指针来管理同步队列,同时实现包括获取锁失败的线程进行入队,释放锁时对同步队列中的线程进行通知等核心方法。其示意图如下:
通过对源码的理解以及做实验的方式,现在我们可以清楚的知道这样几点:
- 节点的数据结构,即 AQS 的静态内部类 Node,节点的等待状态等信息;
- 同步队列是一个双向队列,AQS 通过持有头尾指针管理同步队列;
那么,节点如何进行入队和出队是怎样做的了?实际上这对应着锁的获取和释放两个操作:获取锁失败进行入队操作,获取锁成功进行出队操作。
独占锁
独占锁的获取
在上面的 demo 中我们使用了Lock.lock()上了锁,其本质是获取独占锁,获取失败就将当前线程加入同步队列,成功则线程执行
lock()方法实际上会调用 AQS 的acquire()方法
1 | public final void acquire(int arg) { |
acquire 根据当前获得同步状态成功与否做了两件事情:
- 成功,则方法结束返回
- 失败,则先调用 addWaiter()然后在调用 acquireQueued()方法。
获取同步状态失败,入队操作
当线程获取独占式锁失败后就会将当前线程加入同步队列,那么加入队列的方式是怎样的了?
我们接下来就应该去研究一下 addWaiter()和 acquireQueued()。addWaiter()源码如下:
1 | private Node addWaiter(Node mode) { |
分析可以看上面的注释。程序的逻辑主要分为两个部分:
1. 当前同步队列的尾节点为 null,调用方法 enq()插入;
2. 当前队列的尾节点不为 null,则采用尾插入(compareAndSetTail()方法)的方式入队。
另外还会有另外一个问题:如果 if (compareAndSetTail(pred, node))为 false 怎么办?会继续执行到 enq()方法,同时很明显 compareAndSetTail 是一个 CAS 操作,通常来说如果 CAS 操作失败会继续自旋(死循环)进行重试。
因此,经过我们这样的分析,enq()方法可能承担两个任务:
- 处理当前同步队列尾节点为 null 时进行入队操作;
- 如果 CAS 尾插入节点失败后负责自旋进行尝试。
- enq()源码
1 | private Node enq(final Node node) { |
在上面的分析中我们可以看出在第 1 步中会先创建头结点,说明同步队列是带头结点的链式存储结构。
- 带头结点与不带头结点区别
带头结点与不带头结点相比,会在入队和出队的操作中获得更大的便捷性,因此同步队列选择了带头结点的链式存储结构。
- 队列初始化时机
那么带头节点的队列初始化时机是什么?自然而然是在tail 为 null 时,即当前线程是第一次插入同步队列。compareAndSetTail(t, node)方法会利用 CAS 操作设置尾节点,如果 CAS 操作失败会在for (;;)for 死循环中不断尝试,直至成功 return 返回为止。
- enq 方法总结
因此,对 enq()方法可以做这样的总结:
- 在当前线程是第一个加入同步队列时,调用 compareAndSetHead(new Node())方法,完成链式队列的头结点的初始化;
- 自旋不断尝试 CAS 尾插入节点直至成功为止。
现在我们已经很清楚获取独占式锁失败的线程包装成 Node 然后插入同步队列的过程了。
那么紧接着会有下一个问题 —— 在同步队列中的节点(线程)会做什么事情了来保证自己能够有机会获得独占式锁呢?
带着这样的问题我们就来看看acquireQueued()方法,从方法名就可以很清楚,这个方法的作用就是排队获取锁的过程,源码如下:
1 | final boolean acquireQueued(final Node node, int arg) { |
程序逻辑通过注释已经标出,整体来看这是一个这又是一个自旋的过程(for (;;)),代码首先获取当前节点的先驱节点,如果先驱节点是头结点的并且成功获得同步状态的时候(if (p == head && tryAcquire(arg))),当前节点所指向的线程能够获取锁。
反之,获取锁失败进入等待状态。整体示意图为下图:
获取锁成功,出队操作
获取锁的节点出队的逻辑是:
1 | //队列头结点引用指向当前节点 |
setHead()方法为:
1 | private void setHead(Node node) { |
将当前节点通过 setHead()方法设置为队列的头结点,然后将之前的头结点的 next 域设置为 null 并且 pre 域也为 null,即与队列断开,无任何引用,这样做方便 GC 时能够将内存进行回收。示意图如下:
那么当获取锁失败的时候会调用 shouldParkAfterFailedAcquire()方法和 parkAndCheckInterrupt()方法,看看他们做了什么事情。
shouldParkAfterFailedAcquire()方法源码为:
1 | private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { |
- 方法逻辑
shouldParkAfterFailedAcquire()方法主要逻辑是使用compareAndSetWaitStatus(pred, ws, Node.SIGNAL)使用 CAS 将节点状态由 INITIAL 设置成 SIGNAL,表示当前线程阻塞。
当 compareAndSetWaitStatus 设置失败则说明 shouldParkAfterFailedAcquire 方法返回 false,然后会在 acquireQueued()方法中 for (;;)死循环中会继续重试,直至 compareAndSetWaitStatus 设置节点状态位为 SIGNAL 时 shouldParkAfterFailedAcquire 返回 true 时才会执行方法parkAndCheckInterrupt()方法
该方法的源码为:
1 | private final boolean parkAndCheckInterrupt() { |
该方法的关键是会调用 LookSupport.park()方法(关于 LookSupport 会在以后的文章进行讨论),该方法是用来阻塞当前线程的。因此到这里就应该清楚了,acquireQueued()在自旋过程中主要完成了两件事情:
- 如果当前节点的前驱节点是头节点,并且能够获得同步状态的话,当前线程能够获得锁该方法执行结束退出;
- 获取锁失败的话,先将节点状态设置成 SIGNAL,然后调用 LookSupport.park 方法使得当前线程阻塞。
- 整体流程图
.jpg)
独占锁的释放
独占锁的释放就相对来说比较容易理解了,废话不多说先来看下源码:
1 | public final boolean release(int arg) { |
这段代码逻辑就比较容易理解了,如果同步状态释放成功(tryRelease 返回 true)则会执行 if 块中的代码,当 head 指向的头结点不为 null,并且该节点的状态值不为 0 的话才会执行 unparkSuccessor()方法。
- unparkSuccessor 方法源码
1 | private void unparkSuccessor(Node node) { |
源码的关键信息请看注释,首先获取头节点的后继节点,当后继节点的时候会调用 LookSupport.unpark()方法,该方法会唤醒该节点的后继节点所包装的线程。因此,每一次锁释放后就会唤醒队列中该节点的后继节点所引用的线程,从而进一步可以佐证获得锁的过程是一个 FIFO(先进先出)的过程。
到现在我们终于啃下了一块硬骨头了,通过学习源码的方式非常深刻的学习到了独占式锁的获取和释放的过程以及同步队列。
- 独占锁总结
AQS 的本质是去维护一个 CLH 同步队列,具体细节如下:
- 线程获取锁失败,线程被封装成 Node 进行入队操作,核心方法在于 addWaiter()和 enq(),同时 enq()完成对同步队列的头结点初始化工作以及 CAS 操作失败的重试;
- 线程获取锁是一个自旋的过程,当且仅当 当前节点的前驱节点是头结点.并且成功获得同步状态时,节点出队即该节点引用的线程获得锁,否则,当不满足条件时就会调用 LookSupport.park()方法使得线程阻塞;
- 释放锁的时候会唤醒后继节点;
总体来说:在获取同步状态时,AQS 维护一个同步队列,获取同步状态失败的线程会加入到队列中进行自旋;移除队列(或停止自旋)的条件是前驱节点是头结点并且成功获得了同步状态。在释放同步状态时,同步器会调用 unparkSuccessor()方法唤醒后继节点。
独占锁特性学习
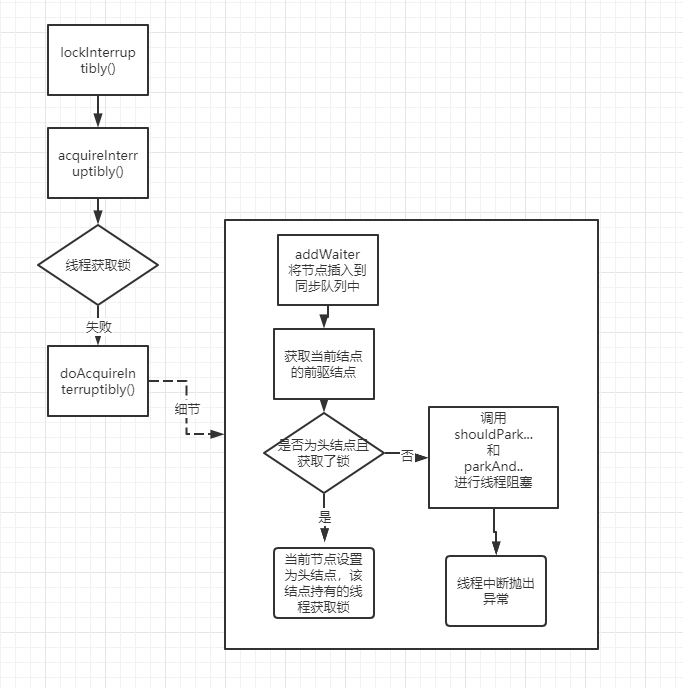
可中断式获取锁(acquireInterruptibly 方法)
我们知道 lock 相较于 synchronized 有一些更方便的特性,比如能响应中断以及超时等待等特性,现在我们依旧采用通过学习源码的方式来看看能够响应中断是怎么实现的。
可响应中断式锁可调用方法lock.lockInterruptibly();而该方法其底层会调用 AQS 的acquireInterruptibly方法
- 源码
1 | public final void acquireInterruptibly(int arg) |
在获取同步状态失败后就会调用doAcquireInterruptibly方法:
1 | private void doAcquireInterruptibly(int arg) |
关键信息请看注释,现在看这段代码就很轻松了吧:),与 acquire 方法逻辑几乎一致、唯一的区别是当parkAndCheckInterrupt返回 true 时即线程阻塞时该线程被中断,代码抛出被中断异常。
- 流程图
超时等待式获取锁(tryAcquireNanos()方法)
通过调用 lock.tryLock(timeout,TimeUnit)方式达到超时等待获取锁的效果,该方法会在三种情况下才会返回:
- 在超时时间内,当前线程成功获取了锁;
- 当前线程在超时时间内被中断;
- 超时时间结束,仍未获得锁返回 false。
我们仍然通过采取阅读源码的方式来学习底层具体是怎么实现的,该方法会调用 AQS 的方法 tryAcquireNanos(),源码为:
1 | public final boolean tryAcquireNanos(int arg, long nanosTimeout) |
很显然这段源码最终是靠 doAcquireNanos 方法实现超时等待的效果,该方法源码如下:
1 | private boolean doAcquireNanos(int arg, long nanosTimeout) |
程序逻辑如图所示:
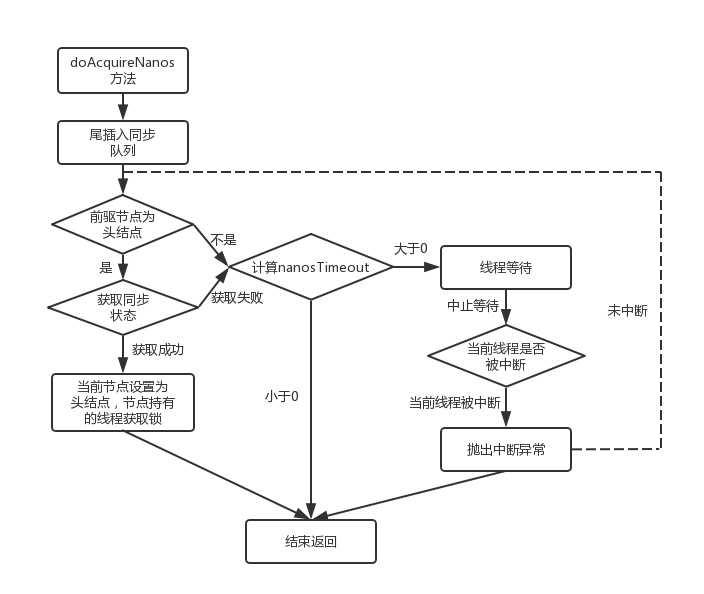
程序逻辑同独占锁可响应中断式获取基本一致,唯一的不同在于获取锁失败后,对超时时间的处理上:
- 在第 1 步会先计算出按照现在时间和超时时间计算出理论上的截止时间,比如当前时间是 8h10min,超时时间是 10min,那么根据
deadline = System.nanoTime() + nanosTimeout计算出刚好达到超时时间时的系统时间就是 8h 10min+10min = 8h 20min。 - 然后根据
deadline - System.nanoTime()就可以判断是否已经超时了,比如,当前系统时间是 8h 30min 很明显已经超过了理论上的系统时间 8h 20min,deadline - System.nanoTime()计算出来就是一个负数,自然而然会在 3.2 步中的 If 判断之间返回 false。 - 如果还没有超时即 3.2 步中的 if 判断为 true 时就会继续执行 3.3 步通过LockSupport.parkNanos使得当前线程阻塞,同时在 3.4 步增加了对中断的检测,若检测出被中断直接抛出被中断异常。
共享锁
共享锁的获取(acquireShared()方法)
在聊完 AQS 对独占锁的实现后,我们继续一鼓作气的来看看共享锁是怎样实现的?共享锁的获取方法为 acquireShared,源码为:
1 | public final void acquireShared(int arg) { |
这段源码的逻辑很容易理解,在该方法中会首先调用 tryAcquireShared 方法,tryAcquireShared 返回值是一个 int 类型,当返回值为大于等于 0 的时候方法结束说明获得成功获取锁,否则,表明获取同步状态失败即所引用的线程获取锁失败,会执行doAcquireShared方法,
该方法的源码为:
1 | private void doAcquireShared(int arg) { |
共享锁的获取逻辑几乎和独占式锁的获取一模一样,这里的自旋过程中能够退出的条件是当前节点的前驱节点是头结点并且 tryAcquireShared(arg)返回值大于等于 0(表示获得了锁)即能成功获得同步状态。
共享锁的释放(releaseShared()方法)
- 背景
在setHeadAndPropagate(node, r);方法中,代码功能分为两部分:
- 设置头结点
- 释放同步状态,唤醒下一个节点,其中的释放同步状态就使用了
releaseShared方法
共享锁的释放在 AQS 中会调用方法releaseShared:
1 | public final boolean releaseShared(int arg) { |
当成功释放同步状态之后即 tryReleaseShared 会继续执行 doReleaseShared 方法:
1 | private void doReleaseShared() { |
这段方法跟独占式锁释放过程有点点不同,在共享式锁的释放过程中,对于能够支持多个线程同时访问的并发组件,必须保证多个线程能够安全的释放同步状态,这里采用的 CAS 保证,当 CAS 操作失败 continue,在下一次循环中进行重试。
ReentrantLock - 可重入锁
ReentrantLock 简介
ReentrantLock 重入锁,是基于AQS同时实现Lock 接口的一个类,在并发编程的时候实现公平锁和非公平锁两种方式对共享资源进行同步。
重入性,表示能够对共享资源能够重复加锁,即当前线程获取该锁再次获取不会被阻塞。
在 java 关键字 synchronized 隐式支持重入性,synchronized 通过获取自增,释放自减的方式实现重入。
要想完完全全的弄懂 ReentrantLock 的话,主要也就是 ReentrantLock 同步语义的学习:
- 重入性的实现原理
- 公平锁和非公平锁
重入性的实现原理
要想支持重入性,就要解决两个问题:
1. 在线程获取锁的时候,如果已经获取锁的线程是当前线程的话则直接再次获取成功;
2. 由于锁会被获取 n 次,那么只有锁在被释放同样的 n 次之后,该锁才算是完全释放成功。
通过[AQS](# AbstractQueuedSynchronizer(AQS)的学习,我们知道,同步组件主要是通过重写 AQS 的几个 protected 方法来表达自己的同步语义。针对第一个问题,我们来看看 ReentrantLock 是怎样实现的,以非公平锁为例,判断当前线程能否获得锁为例,核心方法为nonfairTryAcquire:
1 | final boolean nonfairTryAcquire(int acquires) { |
这段代码的逻辑也很简单,具体请看注释。为了支持重入性,在第二步增加了处理逻辑,如果该锁已经被线程所占有了,会继续检查占有线程是否为当前线程,如果是的话,同步状态加 1 返回 true,表示可以再次获取成功。每次重新获取都会对同步状态进行加一的操作,那么释放的时候处理思路是怎样的了?(依然还是以非公平锁为例)核心方法为 tryRelease:
1 | protected final boolean tryRelease(int releases) { |
代码逻辑看注释
- 注意点
需要注意的是,重入锁的释放必须得等到同步状态为 0 时锁才算成功释放,否则锁仍未释放。如果锁被获取 n 次,释放了 n-1 次,该锁未完全释放返回 false,只有被释放 n 次才算成功释放,返回 true。因此,return 的值并不是代表有没有释放成功,而是代表有没有完全释放!
到现在我们可以理清 ReentrantLock 重入性的实现了,也就是理解了同步语义的第一条。
公平锁与非公平锁
- ReentrantLock 支持两种锁:公平锁和非公平锁。何谓公平性,是针对获取锁而言的,如果一个锁是公平的,那么锁的获取顺序就应该符合请求上的绝对时间顺序,满足 FIFO。
公平锁 VS 非公平锁
公平锁每次获取到锁为同步队列中的第一个节点,保证请求资源时间上的绝对顺序,而非公平锁有可能刚释放锁的线程下次继续获取该锁,则有可能导致其他线程永远无法获取到锁,造成“饥饿”现象。
公平锁为了保证时间上的绝对顺序,需要频繁的上下文切换,而非公平锁会降低一定的上下文切换,降低性能开销。因此,ReentrantLock 默认选择的是非公平锁,则是为了减少一部分上下文切换,保证了系统更大的吞吐量。
- 公平锁:按照请求锁的顺序分配,拥有稳定获得锁的机会,但是性能可能比非公平锁低
- 非公平锁:不按照请求锁的顺序分配,不一定拥有获得锁的机会,但是性能可能比公平锁高
- 非公平锁源码
1 | /** |
- 公平锁源码
1 | /** |
ReentrantLock 的构造方法无参时是构造非公平锁,源码为:
1 | public ReentrantLock() { |
另外还提供了另外一种方式,可传入一个 boolean 值,true 时为公平锁,false 时为非公平锁,源码为:
1 | public ReentrantLock(boolean fair) { |
在上面非公平锁获取时(nonfairTryAcquire 方法)只是简单的获取了一下当前状态做了一些逻辑处理,并没有考虑到当前同步队列中线程等待的情况。我们来看看公平锁的处理逻辑是怎样的,核心方法为:
1 | protected final boolean tryAcquire(int acquires) { |
这段代码的逻辑与 nonfairTryAcquire 基本上一致,唯一的不同在于增加了hasQueuedPredecessors的逻辑判断,方法名就可知道该方法用来判断当前节点在同步队列中是否有前驱节点的判断,如果有前驱节点说明有线程比当前线程更早的请求资源,根据公平性,当前线程请求资源失败。
如果当前节点没有前驱节点的话,再才有做后面的逻辑判断的必要性。公平锁每次都是从同步队列中的第一个节点获取到锁,而非公平性锁则不一定,有可能刚释放锁的线程能再次获取到锁。
ReentrantReadWriteLock - 读写锁
ReadLock
1 | public static class ReadLock implements Lock, java.io.Serializable { |
读锁的获取
它的各种代码都与 AQS 的没太大变化,我们关心一下其独特的部分:tryAcquireShared方法
- 源码
1 | protected final int tryAcquireShared(int unused) { |
大体流程:
- step1:如果写锁被获取,直接获取资源
acquire失败(返回 -1)。 - step2:写锁没被获取,则首先根据
queue policy(公平锁或非公平锁) 判断一下要不要阻塞。不需要阻塞则有其次,通过修改 原子state来尝试获取资源,成功则要修改一下重入计数。 - step3:上面的都失败了,则进入到
fullTryAcquireShared中。
- exclusiveCount(c) 与 sharedCount(c)
exclusiveCount(c)方法,其源码为:
1 | static final int SHARED_SHIFT = 16; |
这个函数表达的意思是:
c & EXCLUSIVE_MASK != 0,c 是我们的 原子state,如果 c 和 EXCLUSIVE_MASK 按位与后不为零,代表无权获取资源,即已经有线程持有了写锁。
其中EXCLUSIVE_MASK为: static final int EXCLUSIVE_MASK = (1 << SHARED_SHIFT) - 1; EXCLUSIVE _MASK 为 1 左移 16 位然后减 1,即为 0x0000FFFF(二进制的 1111 1111,即十进制的 255)。
而 exclusiveCount 方法是将同步状态(state 为 int 类型)与 0x0000FFFF 相与,即取同步状态的低 16 位。那么低 16 位代表什么呢?根据 exclusiveCount 方法的注释为独占式获取的次数即写锁被获取的次数,现在就可以得出来一个结论同步状态的低 16 位用来表示写锁的获取次数。
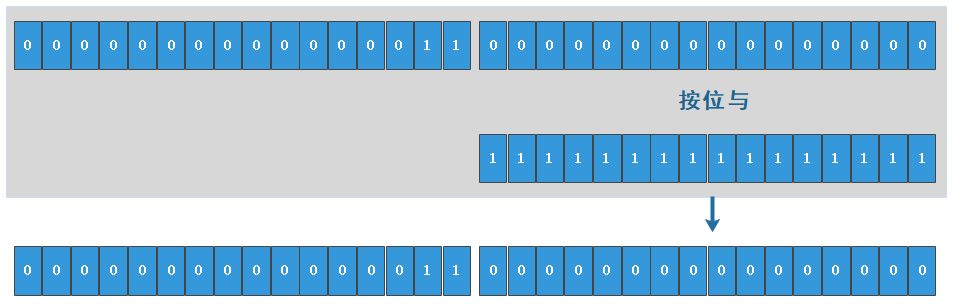
那么问题就来了,为什么高位不需要做判断呢?别急,往下看。
sharedCount(c)方法,其源码为:
1 | static int sharedCount(int c) { return c >>> SHARED_SHIFT; } |
该方法是获取读锁被获取的次数,是将同步状态(int c)右移 16 次,即取同步状态的高 16 位,现在我们可以得出另外一个结论同步状态的高 16 位用来表示读锁被获取的次数。读写锁是怎样实现分别记录读锁和写锁的状态的,现在这个问题的答案就已经被我们弄清楚了,其示意图如下图所示:
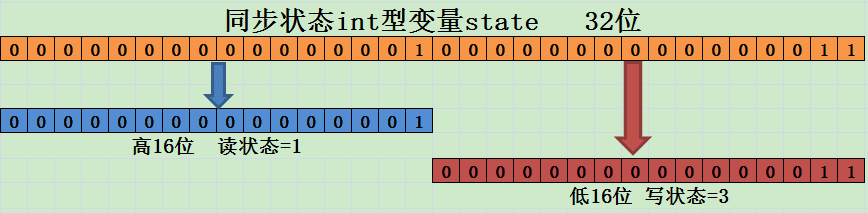
读写锁共用一个 原子
state,但读锁控制高 16 位,写锁控制低 16 位。 对于写锁来说,低 16 位都为 0 代表没有持锁,只要有一个 1 ,则代表某线程已经持有写锁。
- fullTryAcquireShared方法
这个方法与tryAcquireShared高度类似,代码逻辑在注释中:
1 | final int fullTryAcquireShared(Thread current) { |
firstReader是获取读锁的第一个线程。如果只有一个线程获取读锁,很明显,使用这样一个变量速度更快。firstReaderHoldCount是firstReader的计数器。同上。cachedHoldCounter是最后一个获取到读锁的线程计数器,每当有新的线程获取到读锁,这个变量都会更新。这个变量的目的是:当最后一个获取读锁的线程重复获取读锁,或者释放读锁,就会直接使用这个变量,速度更快,相当于缓存。
图解流程
发现了没?我们获取读锁的时候根本不关心读锁有没有被获取,因此从这点也可以知道读锁的共享锁,也就是允许 读 - 读 的场景,而不允许 读 -写 的场景。
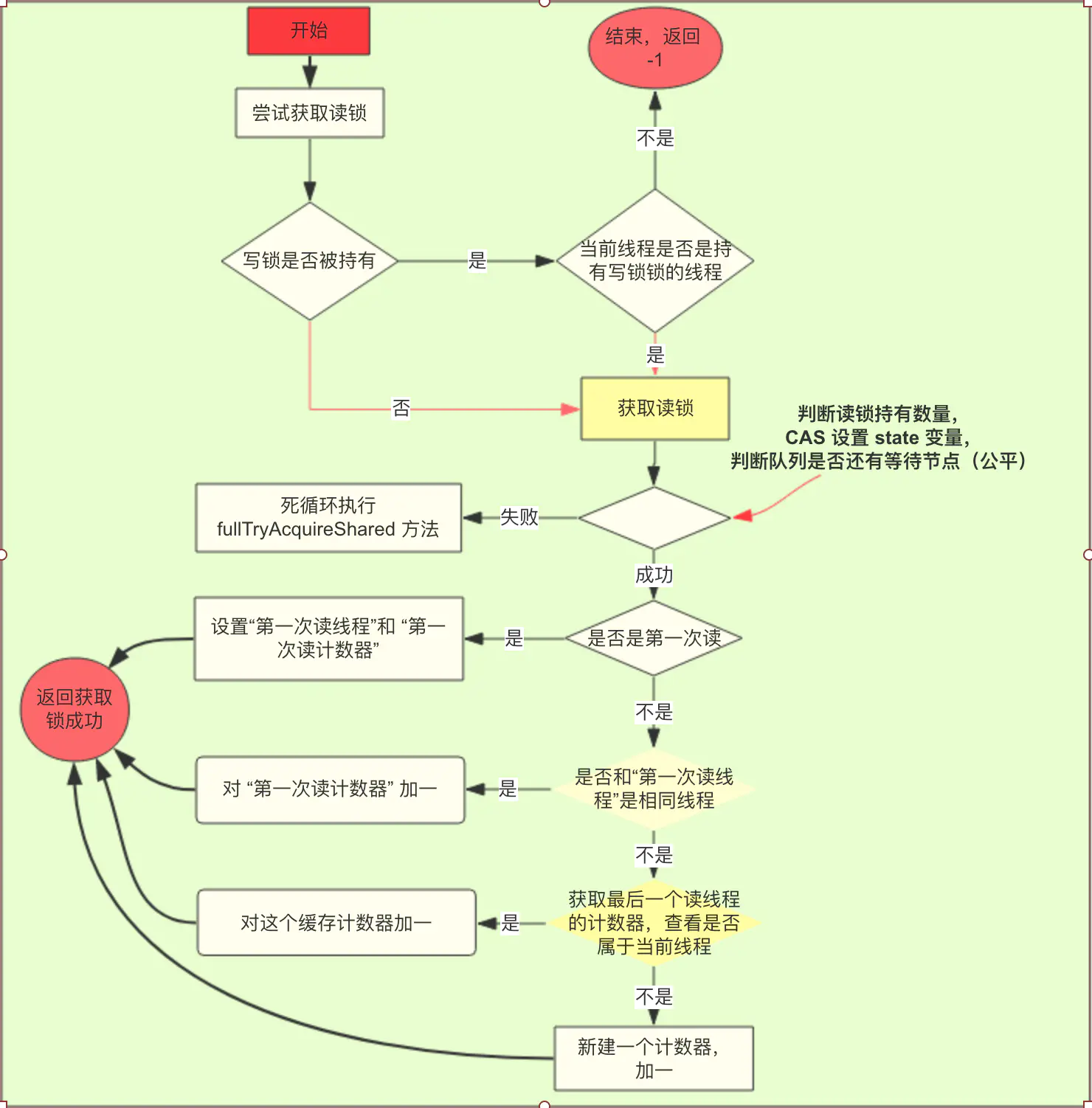
读锁的释放
读锁释放的实现主要通过方法tryReleaseShared
1 | protected final boolean tryReleaseShared(int unused) { |
回想一下重入锁,重入锁每次释放资源使得 原子state - -,当 原子state 为零时,则唤醒队列中下一个等待的线程。
读锁实际上也是如此,但要注意读锁是有两个状态来维护锁的层级和持有共享锁的线程数量的:
- 一个是
HoldCounter负责重入计数, - 一个是 原子
state高位,负责记录有多少个线程持有了共享锁。
也就是说,我们释放资源release时,需要首先使得 HoldCounter--,直到其为零,再去操作 原子state高位。
最后,直到原子state高位归零了,就去唤醒下一个等待的线程。
WriteLock
1 | public static class WriteLock implements Lock, java.io.Serializable { |
写锁的获取
1 | protected final boolean tryAcquire(int acquires) { |
现在我们回过头来看写锁获取方法 tryAcquire,其主要逻辑为:当读锁已经被读线程获取或者写锁已经被其他写线程获取,则写锁获取失败;否则,获取成功并支持重入,增加写状态。
写锁的释放
1 | // 写锁的释放是线程安全的,因为写锁是独占锁,具有排他性(一次只能有一个线程拥有) |
这里需要注意的是,减少写状态int nextc = getState() - releases;只需要用当前同步状态直接减去写状态的原因正是我们刚才所说的写状态是由同步状态的低 16 位表示的。
锁降级
锁降级指的是写锁降级成为读锁。
- 如果当前线程拥有写锁,然后将其释放,最后再获取读锁,这种分段完成的过程不能称之为锁降级。
- 锁降级是指把持住(当前拥有的)写锁,再获取到读锁,随后释放(先前拥有的)写锁的过程。
(有锁降级,那有没有锁升级呢?答案是没有的)
1 | public void processData() { |
细节解析:
- update 变量用 volatile 修饰,使得所有访问 processData() 方法的线程都能够感知到变化,保证了可见性
- 只有一个线程能够获取到写锁,其他线程会被阻塞在读锁和写锁的 lock()方法上。
- 当前线程获取写锁完成数据准备之后,再获取读锁,随后释放写锁,完成锁降级。
问题:
锁降级中的读锁的获取是否是必须?
是必须的,为了保证数据的可见性。怎么保证呢?假如现在有一个线程 A 他拥有写锁,现在要释放该写锁。但他不先去获得读锁,就直接释放了写锁。这就导致了一个问题,有另一个线程 B,它获取了你释放掉的写锁,去修改了数据,但 A 线程是无法感知到这个数据被修改了的,就会导致一些错误。
但假如遵循锁降级步骤,释放写锁前获得了读锁,那么线程 B 在获取该写锁的时候就会阻塞,直到线程 A 把数据处理完了,真正释放了读锁后,才能轮到线程 B 去进行相应的写锁获取流程。
Condition
简介
- Condition 用途
当多个线程需要访问一个共享资源时,需要给共享资源加锁。 当一个线程释放锁时,所有等待锁的线程都会尝试去获取锁。 但是如果想只让部分等待锁的线程去获取锁时,就需要用到Condition。
- 整体分析
从整体上来看Object 的 wait 和 notify/notify 是与对象监视器配合完成线程间的等待/通知机制,而 Condition 与 Lock 配合完成等待通知机制,前者是 java 底层级别的,后者是语言级别的,具有更高的可控制性和扩展性。
Condition 具体实现在 AbstractQueuedSynchronizer 类中。这个类中管理了一个阻塞队列和 N 多个条件队列。
阻塞队列记录了等待获取锁的线程,头结点记录了当前正在运行的线程。
条件队列记录了由 Condition.await()阻塞的线程,一个 Lock 可以有多个 Condition,每个 Condition 是一个队列。
Condition 是 AbstractQueuedSynchronizer 的一个内部类 ConditionObject,所以创建的 Condition 对象是可以访问整个 AbstractQueuedSynchronizer 对象的属性的,通过这样将 Condition 与 Lock 相关联。
原理分析
等待队列
- 前言
Condition 是 AQS 的内部类,准确的来说创建一个 condition 对象是通过lock.newCondition(),而这个方法实际上是会 new 出一个ConditionObject对象,而这个ConditionObject对象是 AQS 的一个内部类。
前面我们说过,Condition 是要和 lock 配合使用的也就是 condition 和 Lock 是绑定在一起的,而 lock 的实现原理又依赖于 AQS,自然而然 ConditionObject 作为 AQS 的一个内部类无可厚非。
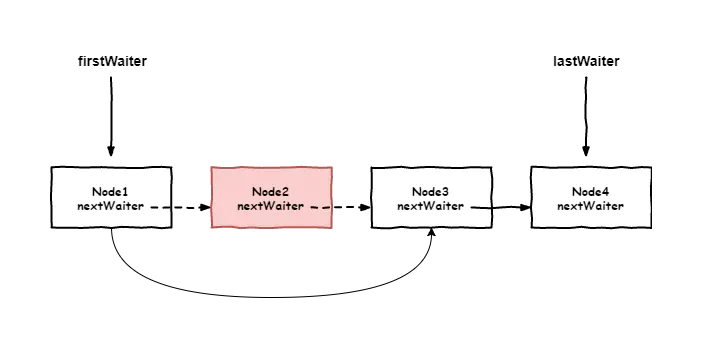
- 等待队列
每个 Condition 对象都包含一个条件队列 (等待队列)。
等待队列是一个 FIFO 的队列,在队列中的每个节点 Node 都包含了一个线程引用,该线程就是在 Condition 对象上等待的线程。
详细来说的话:如果是独占式锁的话,所有获取锁失败的线程的尾插入到同步队列,同样的,Condition 内部也是使用同样的方式,内部维护了一个 等待队列,所有调用condition.await方法的线程会加入到等待队列中,并且线程状态转换为等待状态。
- ConditionObject 中两个成员变量
1 | /** First node of condition queue. */ |
这样我们就可以看出来 ConditionObject 通过持有等待队列的头尾指针来管理等待队列。
- 等待队列为单向队列
值得注意的是 Node 类复用了在 AQS 中的 Node 类,而 Node 类有这样一个属性:
1 | //后继节点 |
这说明 ,等待队列是一个单向队列,而学习 AQS 的时候我们学习到了,同步队列是双向队列
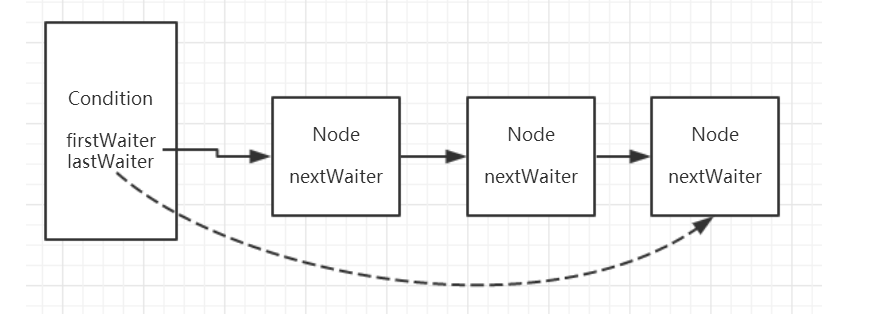
- 一个 Lock 可以持有多个等待队列
我们可以多次调用 lock.newCondition()方法创建多个 condition 对象,也就是一个 lock 可以持有多个等待队列。而在之前利用 Object 的方式实际上是指在对象 Object 对象监视器上只能拥有一个同步队列和一个等待队列,而并发包中的 Lock 拥有一个同步队列和多个等待队列。
需要注意概念混淆的问题:同步队列是在同步的环境下才有的概念,一个对象(即一个锁)永远只对应一个同步队列。
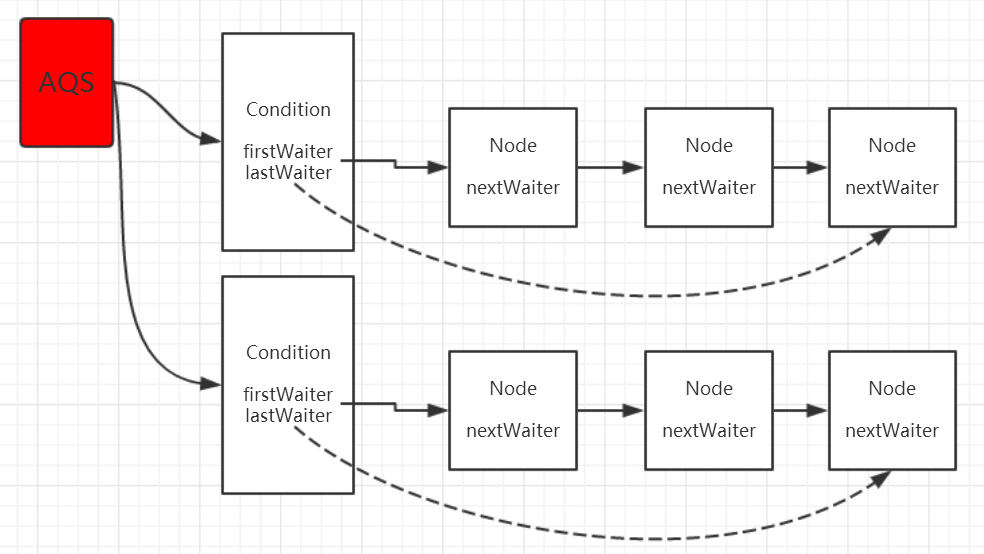
如图所示,ConditionObject 是 AQS 的内部类,因此每个 ConditionObject 能够访问到 AQS 提供的方法,相当于每个 Condition 都拥有所属同步器的引用。
那么为什么每个并发包的同步器需要有多个等待队列呢?有什么作用呢?
因为 AQS 可以实现排他锁(ReentrantLock)和非排他锁(ReentrantReadWriteLock——读写锁),读写锁就是一个需要多个等待队列的锁。等待队列(Condition)用来保存被阻塞的线程的。因为读写锁是一对锁,所以需要两个等待队列来分别保存被阻塞的读锁和被阻塞的写锁。
await 实现原理
- await 流程
当调用 condition.await()方法后会使得当前获取 lock 的线程进入到等待队列,并且释放锁。
注意点:当该方法返回时,当前线程一定获取了同步状态(锁);
具体原因是当通过
signal()等系列方法,线程才会从await()方法返回,而唤醒该线程后会加入同步队列
- await 源码
1 | public final void await() throws InterruptedException { |
代码整体流程:
当当前线程调用 condition.await()方法后,会使得当前线程释放 lock 然后加入到等待队列中,直至被 signal/signalAll 后会使得当前线程从等待队列中移至到同步队列中去,直到获得了 lock 后才会从 await 方法返回,或者在等待时被中断会做中断处理。
- 细节/问题
那么关于这个实现过程我们会有这样几个问题:
- 是怎样将当前线程添加到等待队列中去的?
- 释放锁的过程?
- 怎样才能从 await 方法退出?
要回答这几个问题,我们就需要去注意这几个方法:
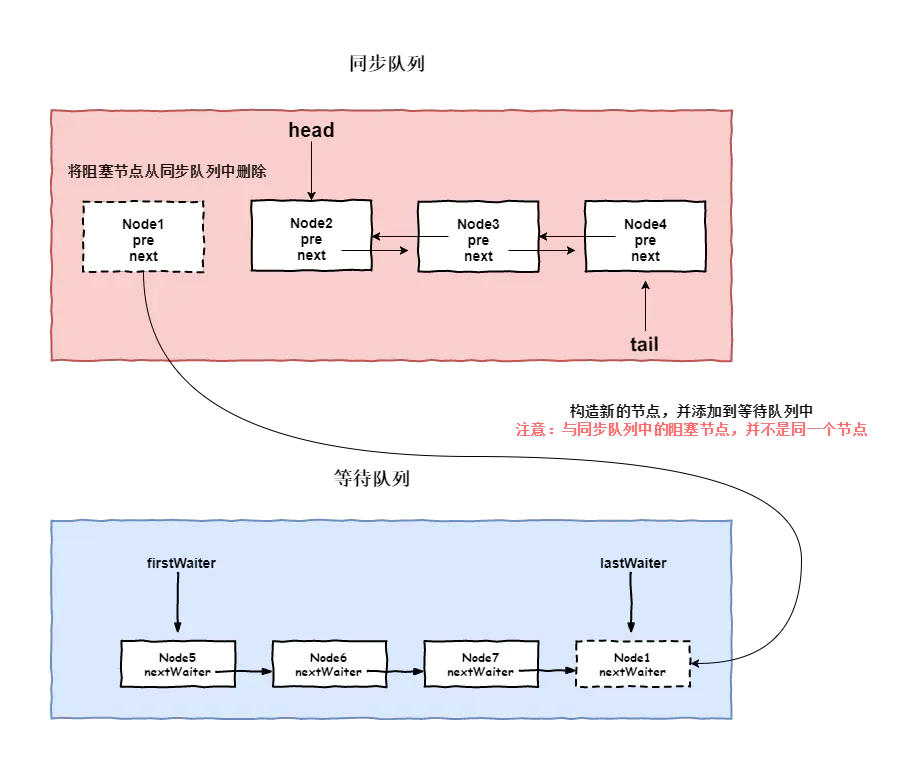
addConditionWaiter unlinkCancelledWaiters() fullyRelease(Node node) isOnSyncQueue(Node node)
- addConditionWaiter 方法 - 线程添加到等待队列
1 | private Node addConditionWaiter() { |
这段代码的流程是:
首先判断尾结点状态,如果尾结点已经中断的话,那么我们就不应该把当前线程包装成节点,接在它的后面,因此需要调用unlinkCancelledWaiters去剔除等待队列中所有的已经中断或已经释放同步状态的线程节点。
接着,将当前节点包装成 Node,如果等待队列的 firstWaiter 为 null 的话(等待队列为空队列),则将 firstWaiter 指向当前的 Node,
否则,更新 lastWaiter(尾节点)即可,即通过尾插入的方式将当前线程封装的 Node 插入到等待队列中即可,同时可以看出等待队列是一个不带头结点的链式队列,之前我们学习 AQS 时知道同步队列是一个带头结点的链式队列,这是两者的一个区别。
将当前节点插入到等待对列之后,会使当前线程释放 lock,由fullyRelease方法实现
- unlinkCancelledWaiters()方法
1 | private void unlinkCancelledWaiters() { |
方法流程:
- fullyRelease 方法 - 释放锁的方法
1 | final int fullyRelease(Node node) { |
代码逻辑:
调用 AQS 的模板方法 release 方法释放 AQS 的同步状态并且唤醒在同步队列中头结点的后继节点引用的线程,如果释放成功则正常返回,若失败的话就抛出异常。
- isOnSyncQueue(Node node)
该方法主要用于判断当前线程节点是否在【同步队列】中。具体代码如下所示:
1 | final boolean isOnSyncQueue(Node node) { |
如果你还记得 AQS 中的同步队列,那么你应该知道同步队列中的 Node 节点才会使用其内部的pre与next字段,那么在同步队列中因为只使用了nextWaiter字段,所以我们就能很简单的通过这两个字段是否为==null,来判断是否在同步队列中。
当然也有可能有一种特殊情况:有可能需要阻塞的线程节点还没有加入到同步队列中,那么这个时候我们需要遍历同步队列来判断是该线程节点是否已存在。
具体代码如下所示:
1 | private boolean findNodeFromTail(Node node) { |
这里为什么是从尾结点向前遍历呢?思考一下,这个方法是用于找哪种线程节点的呢?是找那种还没有加入到同步队列中的线程,这种线程是独立的一个节点,它并没有被连接在任何一个在同步队列中的线程后面,因此,我们需要从后往前找,找到一个node.next == null的,就代表他不在同步队列中,反之,他在同步队列中。
- 如何从 await 方法退出
学习了上面几个方法,我们也可以回答这第三个问题了;
1 | while (!isOnSyncQueue(node)) { |
很显然,当线程第一次调用 condition.await()方法时,会进入到这个 while()循环中,然后通过 LockSupport.park(this)方法使得当前线程进入等待状态,那么要想退出这个 await 方法第一个前提条件自然而然的是要先退出这个 while 循环,出口就只剩下两个地方:
1. 逻辑走到 break 退出 while 循环;
2. while 循环中的逻辑判断为 false。
那么下面就分点讨论这两种情况该如何实现:
- 当前等待的线程被中断后,代码就会走到
break处退出 - 当前节点被移动到了【同步队列】中(即另外线程调用的 condition 的 signal 或者 signalAll 方法),此时 while 循环中判断结果就会为 false,结束循环
总结下,就是当前线程被中断或者调用 condition.signal/condition.signalAll 方法当前节点移动到了同步队列后 ,这是当前线程退出 await 方法的前提条件。当退出 while 循环后就会调用acquireQueued(node, savedState),这个方法在介绍 AQS 的底层实现时说过了,该方法的作用是在自旋过程中线程不断尝试获取同步状态,直至成功(线程获取到 lock)。这样也说明了退出 await 方法必须是已经获得了 condition 引用(关联)的 lock。
- 图解阻塞流程
- 将该线程节点从同步队列中移除,并释放其同步状态。
- 构造新的阻塞节点,加入到等待队列中。
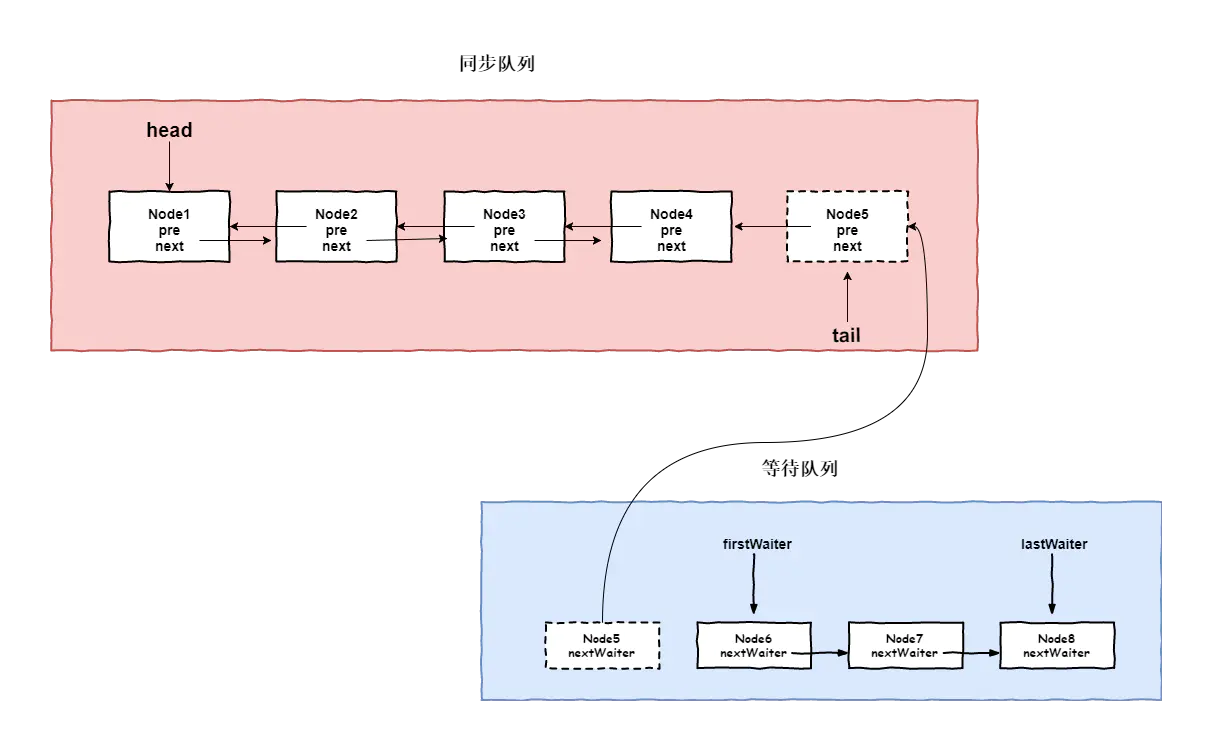
signal/signalAll 实现原理
调用 condition 的 signal 或者 signalAll 方法可以将等待队列中等待时间最长的节点移动到同步队列中,使得该节点能够有机会获得 lock。
按照等待队列是先进先出(FIFO)的,所以等待队列的头节点必然会是等待时间最长的节点,也就是每次调用 condition 的 signal 方法是将头节点移动到同步队列中。
signal源码
1 | public final void signal() { |
这里涉及到了两个方法:
- isHeldExclusively()方法
- doSignal(first)方法
下面对这两个方法进行学习
- isHeldExclusively()方法
isHeldExclusively()方法是 AQS 中的方法,默认交给其子类实现,主要用于判断当前调用singal()方法的线程,是否在同步队列中,且已经获取了同步状态。具体代码如下所示:
1 | protected boolean isHeldExclusively() { |
- doSignal(first)方法
1 | private void doSignal(Node first) { |
将等待队列中的首节点从等待队列中移除,并设置 firstWaiter 的指向为首节点的下一个节点

通过
transferForSignal(Node node)方法,将等待队列中的首节点,加入到同步队列中去,然后重新唤醒该线程节点。
1 | final boolean transferForSignal(Node node) { |
关键逻辑请看注释,这段代码主要做了两件事情
- 将头结点的状态更改为 CONDITION;
- 调用 enq 方法,将该节点尾插入到同步队列中;
- 当将该线程节点放入同步队列后,获取当前节点的状态并判断,如果该节点的
waitStatus>0或者通过compareAndSetWaitStatus(ws, Node.SIGNAL)将该节点的状态设置为 Singal,如果失败则通过LockSupport.unpark(node.thread)唤醒线程。
- 结论
调用 condition 的 signal 的前提条件是当前线程已经获取了 lock,该方法会使得等待队列中的头节点即等待时间最长的那个节点移入到同步队列,而移入到同步队列后才有机会使得等待线程被唤醒,即从 await 方法中的 LockSupport.park(this)方法中返回,从而才有机会使得调用 await 方法的线程成功退出。
- 图解流程
await 与 signal 结合
await 和 signal 和 signalAll 方法就像一个开关控制着线程 A(等待方)和线程 B(通知方):
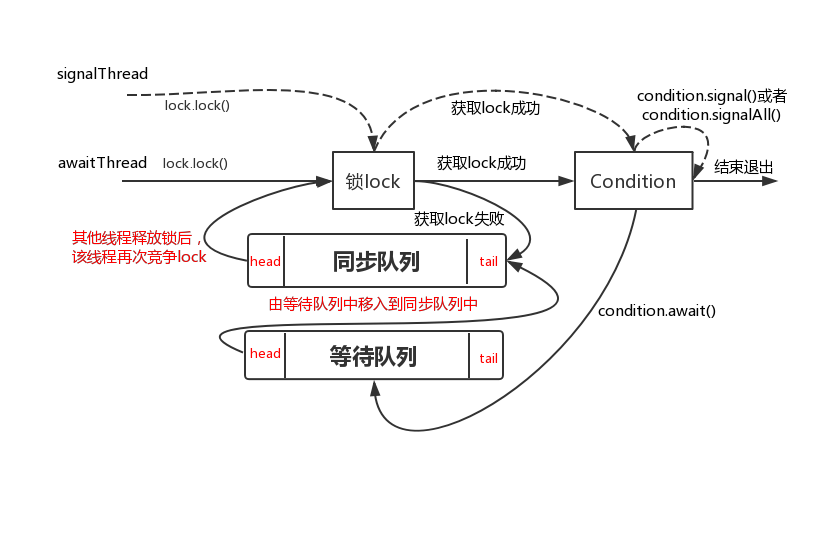
如图,线程 awaitThread 先通过 lock.lock()方法获取锁成功后调用了 condition.await 方法进入等待队列,而另一个线程 signalThread 通过 lock.lock()方法获取锁成功后调用了 condition.signal 或者 signalAll 方法,使得线程 awaitThread 能够有机会移入到同步队列中,当其他线程释放 lock 后使得线程 awaitThread 能够有机会获取 lock,从而使得线程 awaitThread 能够从 await 方法中退出执行后续操作。如果 awaitThread 获取 lock 失败会直接进入到同步队列。
代码例子
1 | public class AwaitSignal { |
输出结果为:
Thread-0 当前条件不满足等待
Thread-0 接收到通知,条件满足
- 代码流程
开启了两个线程 waiter 和 signaler,waiter 线程开始执行的时候由于条件不满足,执行 condition.await 方法使该线程进入等待状态同时释放锁,signaler 线程获取到锁之后更改条件,并通知所有的等待线程后释放锁。这时,waiter 线程获取到锁,并由于 signaler 线程更改了条件此时相对于 waiter 来说条件满足,继续执行。
LockSupport
- 源码
1 | public class LockSupport { |
并发容器
ConcurrentHashMap
ConcurrentHashMap 简介
在使用 HashMap 时在多线程情况下扩容会出现 CPU 接近 100%的情况,因为 Hashmap 并不是线程安全的,通常我们可以使用在 java 体系中古老的 hashtable 类,该类基本上所有的方法都采用 synchronized 进行线程安全的控制,可想而知,在高并发的情况下,每次只有一个线程能够获取对象监视器锁,这样的并发性能的确不令人满意。
另外一种方式通过 Collections 的Map<K,V> synchronizedMap(Map<K,V> m)将 hashmap 包装成一个线程安全的 map。比如 SynchronzedMap 的 put 方法源码为:
1 | public V put(K key, V value) { |
实际上 SynchronizedMap 实现依然是采用 synchronized 独占式锁进行线程安全的并发控制的。同样,这种方案的性能也是令人不太满意的。
相对于 hashmap 来说,ConcurrentHashMap 就是线程安全的 map,其中利用了锁分段的思想提高了并发度。
- JDK 1.6 版本关键要素
- segment 继承了 ReentrantLock 充当锁的角色,为每一个 segment 提供了线程安全的保障;
- segment 维护了哈希散列表的若干个桶,每个桶由 HashEntry 构成的链表。
JDK 1.8 版本关键要素
1.8 版本舍弃了 segment,并且大量使用了 synchronized,以及 CAS 无锁操作以保证 ConcurrentHashMap 操作的线程安全性。
至于为什么不用 ReentrantLock 而是 Synchronzied 呢?实际上,synchronzied 做了很多的优化,包括偏向锁,轻量级锁,重量级锁,可以依次向上升级锁状态,但不能降级,因此,使用 synchronized 相较于 ReentrantLock 的性能会持平甚至在某些情况更优,具体的性能测试可以去网上查阅一些资料。
另外,底层数据结构改变为采用数组+链表+红黑树的数据形式。(之前是数组 + 链表的形式)
关键属性 & 类
在了解 ConcurrentHashMap 的具体方法实现前,我们需要系统的来看一下几个关键的地方。
ConcurrentHashMap 的关键属性
table
volatile Node<K,V>[] table://装载 Node 的数组,作为 ConcurrentHashMap 的数据容器,采用懒加载的方式,直到第一次插入数据的时候才会进行初始化操作,数组的大小总是为 2 的幂次方。nextTable
volatile Node<K,V>[] nextTable; //扩容时使用,平时为 null,只有在扩容的时候才为非 nullsizeCtl
volatile int sizeCtl;(Ctl 的意思 Control,从 sizeControl 也可以明白这个变量的作用了)
sizeCtl为 0,代表数组未初始化, 且数组的初始容量为 16sizeCtl为正数,如果数组未初始化,那么其记录的是数组的初始容量,如果数组已经初始化,那么其记录的是数组的扩容阈值(数组的初始容量*0.75【加载因子】)sizeCtl为-1,表示数组正在进行初始化,如果为-N 则表示当前正有 N-1 个线程进行扩容操作;sizeCtl小于 0,并且不是-1,表示数组正在扩容, -(1+n),表示此时有 n 个线程正在共同完成数组的扩容操作sun.misc.Unsafe U
在 ConcurrentHashMapde 的实现中可以看到大量的 U.compareAndSwapXXXX 的方法去修改 ConcurrentHashMap 的一些属性。这些方法实际上是利用了 CAS 算法保证了线程安全性,这是一种乐观策略,假设每一次操作都不会产生冲突,当且仅当冲突发生的时候再去尝试。而 CAS 操作依赖于现代处理器指令集,通过底层CMPXCHG指令实现。CAS(V,O,N)核心思想为:若当前变量实际值 V 与期望的旧值 O 相同,则表明该变量没被其他线程进行修改,因此可以安全的将新值 N 赋值给变量;若当前变量实际值 V 与期望的旧值 O 不相同,则表明该变量已经被其他线程做了处理,此时将新值 N 赋给变量操作就是不安全的,在进行重试。而在大量的同步组件和并发容器的实现中使用 CAS 是通过sun.misc.Unsafe类实现的,该类提供了一些可以直接操控内存和线程的底层操作,可以理解为 java 中的“指针”。该成员变量的获取是在静态代码块中:1
2
3
4
5
6
7
8static {
try {
U = sun.misc.Unsafe.getUnsafe();
.......
} catch (Exception e) {
throw new Error(e);
}
}
ConcurrentHashMap 中关键内部类
Node
Node 类实现了 Map.Entry 接口,主要存放 key-value 对,并且具有 next 域1
2
3
4
5
6
7static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
......
}
另外可以看出很多属性都是用 volatile 进行修饰的,也就是为了保证内存可见性。
TreeNode
树节点,继承于承载数据的 Node 类。而红黑树的操作是针对 TreeBin 类的,从该类的注释也可以看出,也就是 TreeBin 会将 TreeNode 进行再一次封装1
2
3
4
5
6
7
8
9
10
11**
* Nodes for use in TreeBins
*/
static final class TreeNode<K,V> extends Node<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
......
}TreeBin
这个类并不负责包装用户的 key、value 信息,而是包装的很多 TreeNode 节点。实际的 ConcurrentHashMap“数组”中,存放的是 TreeBin 对象,而不是 TreeNode 对象。1
2
3
4
5
6
7
8
9
10
11static final class TreeBin<K,V> extends Node<K,V> {
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
......
}ForwardingNode
在扩容时才会出现的特殊节点,其 key,value,hash 全部为 null。并拥有 nextTable 指针引用新的 table 数组。1
2
3
4
5
6
7
8static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
.....
}
CAS 关键操作
在上面我们提及到在 ConcurrentHashMap 中会大量使用 CAS 修改它的属性和一些操作。因此,在理解 ConcurrentHashMap 的方法前我们需要了解下面几个常用的利用 CAS 算法来保障线程安全的操作。
tabAt
1
2
3static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}该方法用来获取 table 数组中索引为 i 的 Node 元素。
casTabAt
1
2
3
4static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i,
Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}利用 CAS 操作设置 table 数组中索引为 i 的元素
setTabAt
1
2
3static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v) {
U.putObjectVolatile(tab, ((long)i << ASHIFT) + ABASE, v);
}该方法用来设置 table 数组中索引为 i 的元素
容器初始化方法
实例构造器方法
在 jdk8 的 ConcurrentHashMap 中一共有 5 个构造方法,这四个构造方法中都没有对内部的数组做初始化, 只是对一些变量的初始值做了处理
jdk8 的 ConcurrentHashMap 的数组初始化是在第一次添加元素时完成
1 | // 1. 构造一个空的map,即table数组还未初始化,初始化放在第一次插入数据时,默认大小为16 |
- 无参构造方法
1 | //没有维护任何变量的操作,如果调用该方法,数组长度默认是16 |
- 带参构造方法
1 | //传递进来一个初始容量,ConcurrentHashMap会基于这个值计算一个比这个值大的2的幂次方数作为初始容量 |
注意,调用这个方法,得到的初始容量和我们之前讲的 HashMap 以及 jdk7 的 ConcurrentHashMap 不同,即使你传递的是一个 2 的幂次方数,该方法计算出来的初始容量依然是比这个值大的 2 的幂次方数
- tableSizeFor 源码
1 | /** |
通过注释就很清楚了,该方法会将调用构造器方法时指定的大小转换成一个 2 的幂次方数,也就是说 ConcurrentHashMap 的大小一定是 2 的幂次方,比如,当指定大小为 18 时,为了满足 2 的幂次方特性,实际上 concurrentHashMapd 的大小为 2 的 5 次方(32)。
另外,需要注意的是,调用构造器方法的时候并未构造出 table 数组(可以理解为 ConcurrentHashMap 的数据容器),只是算出 table 数组的长度,当第一次向 ConcurrentHashMap 插入数据的时候才真正的完成初始化创建 table 数组的工作。
- 带加载因子构造方法
1 | //调用四个参数的构造 |
- 给定一个 Map 构造方法
1 | //基于一个Map集合,构建一个ConcurrentHashMap |
- 给定 Map 大小,加载因子以及并发度构造方法
1 | //计算一个大于或者等于给定的容量值,该值是2的幂次方数作为初始容量 |
initTable 方法
1 | private final Node<K,V>[] initTable() { |
- 代码逻辑
由于有可能存在一个情况是多个线程同时走到这个方法中,为了保证能够正确初始化:
- 首先通过 if 进行判断,若当前已经有一个线程正在初始化即 sizeCtl 值变为-1,这个时候其他线程在 If 判断为 true 从而调用 Thread.yield()让出 CPU 时间片
- 正在进行初始化的线程会调用 U.compareAndSwapInt 方法将 sizeCtl 改为-1 即正在初始化的状态。
如果选择是无参的构造器的话,这里在 new Node 数组的时候会使用默认大小为DEFAULT_CAPACITY(16),然后乘以加载因子 0.75 为 12,也就是说数组的可用大小为 12。
添加(put)方法
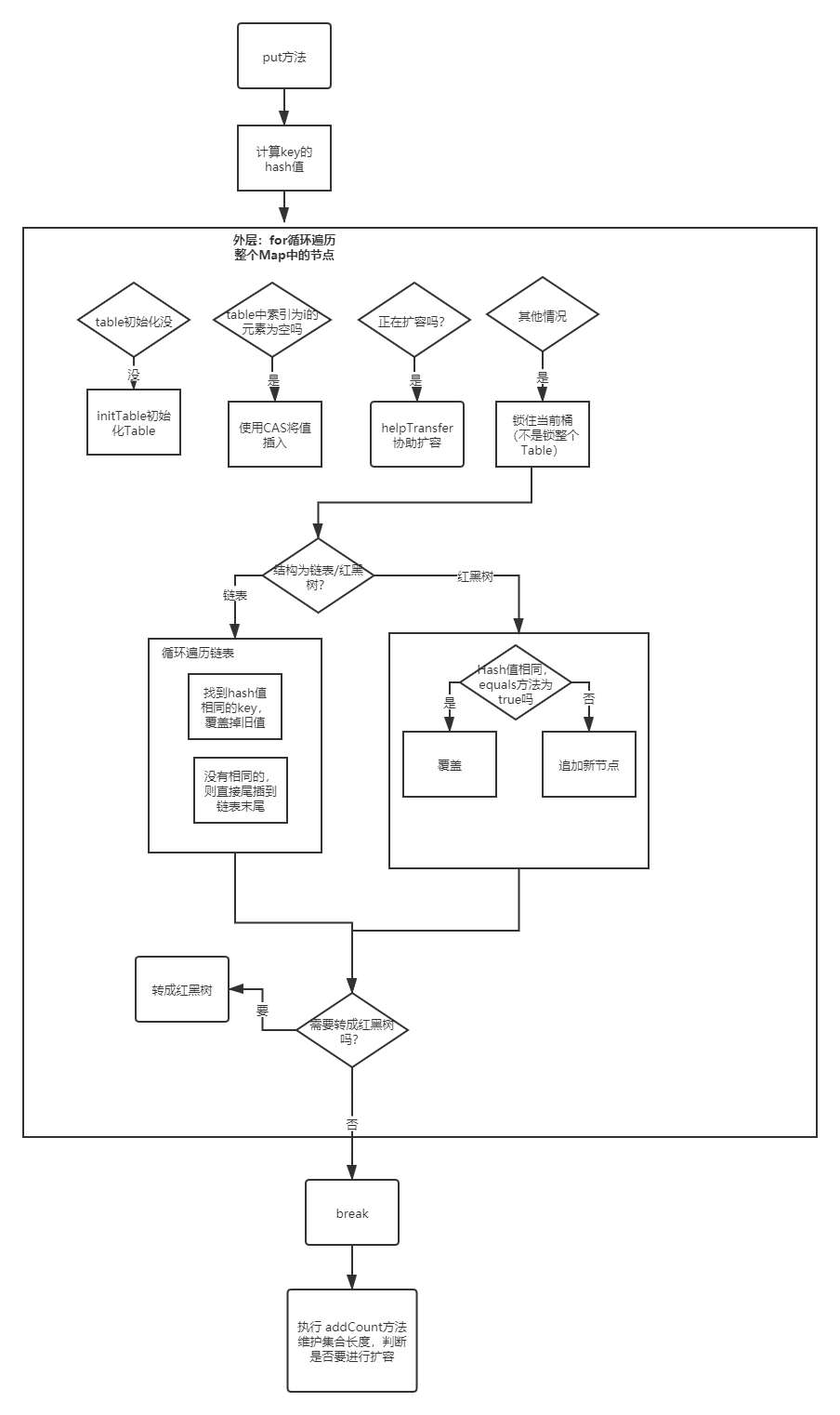
源码
1 | public V put(K key, V value) { |
它的本质是调用putVal方法
1 | final V putVal(K key, V value, boolean onlyIfAbsent) { |
代码细节 & 逻辑分析
下图为 ConcurrentHashMap 的数据结构形式,为一个哈希桶数组;
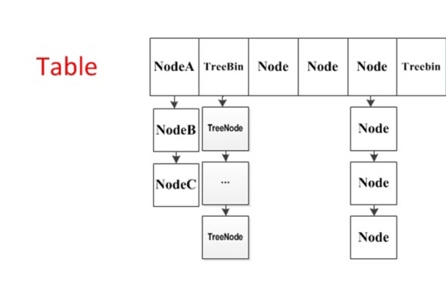
如果不出现哈希冲突的时候,每个元素均匀的分布在哈希桶数组中。当出现哈希冲突的时候,是标准的链地址的解决方式,将 hash 值相同的节点构成链表的形式,称为“拉链法”。
另外,在 1.8 版本中为了防止拉链过长,当链表的长度大于 8(其实是大于 64,在 8 - 64 之间只会扩容)的时候会将链表转换成红黑树。table 数组中的每个元素实际上是单链表的头结点或者红黑树的根节点。当插入键值对时首先应该定位到要插入的桶,即插入 table 数组的索引 i 处。
引申出来一个问题:如何计算得出索引?
回答:通过 key 的 HashCode 值
如何计算呢?
- spread()重哈希,以减小 Hash 冲突
对于一个 hash 表来说,hash 值分散的不够均匀的话会大大增加哈希冲突的概率,从而影响到 hash 表的性能。
因此通过spread方法进行了一次重 hash 从而大大减小哈希冲突的可能性
1 | static final int spread(int h) { |
该方法主要是将 key 的 hashCode 的低 16 位于高 16 位进行异或运算,这样不仅能够使得 hash 值能够分散能够均匀减小 hash 冲突的概率,另外只用到了异或运算,在性能开销上也能兼顾,做到平衡的 trade-off。
- 初始化 table
这里会判断 table 是否是经过初始化的,没有的话,就调用initTable进行初始化;
- 判断是否正在扩容
如果当前节点不为 null,且该节点为特殊节点(forwardingNode)的话,就说明当前 concurrentHashMap 正在进行扩容操作,关于扩容操作,之后会详细讲述。
那么怎样确定当前的这个 Node 是不是特殊的节点了?是通过判断该节点的 hash 值是不是等于-1(MOVED),代码为(fh = f.hash) == MOVED
1 | static final int MOVED = -1; // hash for forwarding nodes |
- 图解流程
取出(get)方法
源码
1 | public V get(Object key) { |
代码逻辑
首先先看当前的 hash 桶数组节点即 table[i]是否为查找的节点,若是则直接返回;若不是,则继续再看当前是不是树节点?通过看节点的 hash 值是否为小于 0,如果小于 0 则为树节点。如果是树节点在红黑树中查找节点;如果不是树节点,那就只剩下为链表的形式的一种可能性了,就向后遍历查找节点,若查找到则返回节点的 value 即可,若没有找到就返回 null。
- 图解
.png)
扩容( transfer)方法
源码
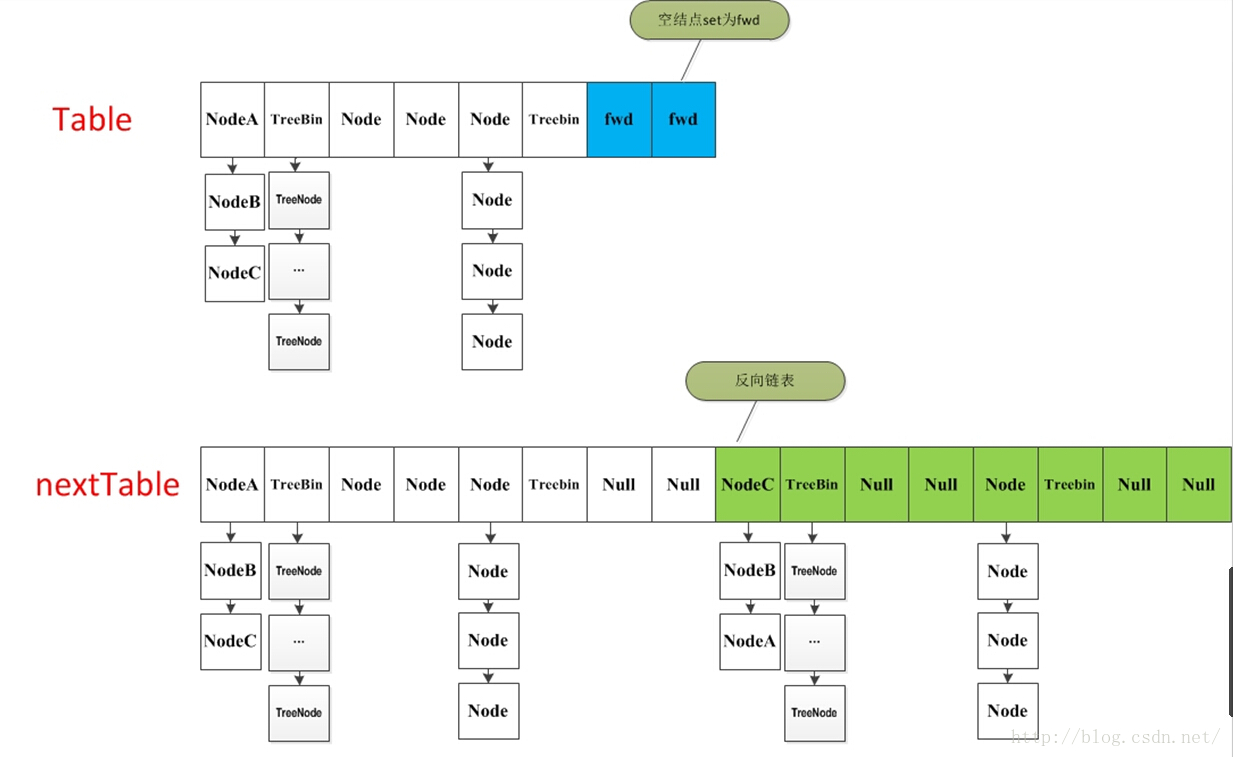
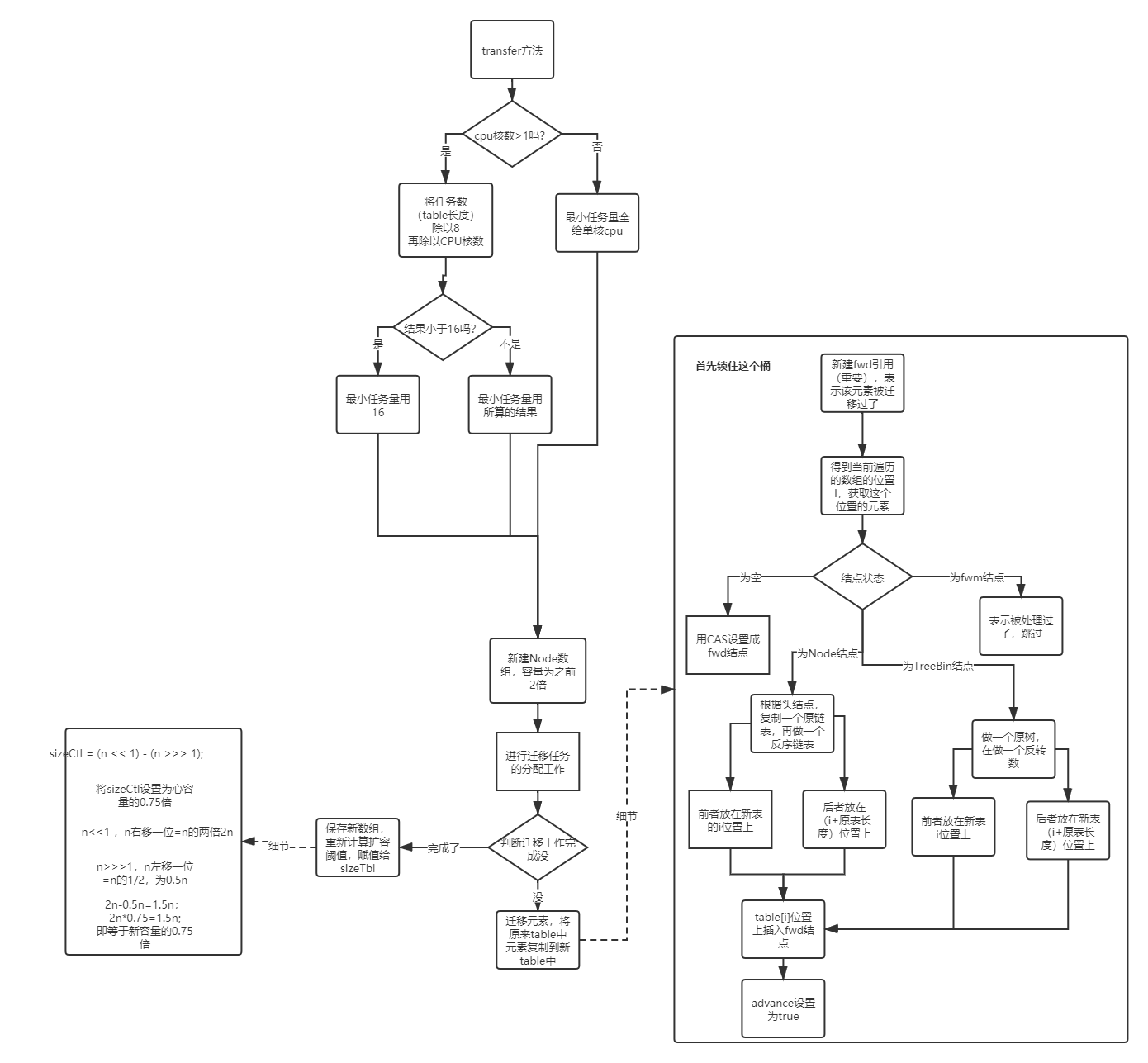
1 | private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { |
代码流程/细节
代码逻辑请看注释,整个扩容操作分为两个部分:
第一部分是构建一个 nextTable,它的容量是原来的两倍,这个操作是单线程完成的。新建 table 数组的代码为:Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1],在原容量大小的基础上右移一位。
第二个部分就是将原来 table 中的元素复制到 nextTable 中,主要是遍历复制的过程。
根据运算得到当前遍历的数组的位置 i,然后利用 tabAt 方法获得 i 位置的元素再进行判断:
- 如果这个位置为空,就在原 table 中的 i 位置放入 forwardNode 节点,这个也是触发并发扩容的关键点;
- 如果这个位置是 Node 节点(fh>=0),如果它是一个链表的头节点,就构造一个反序链表,把他们分别放在 nextTable 的 i 和 i+n 的位置上
- 如果这个位置是 TreeBin 节点(fh<0),也做一个反序处理,并且判断是否需要 untreefi,把处理的结果分别放在 nextTable 的 i 和 i+n 的位置上
- 遍历过所有的节点以后就完成了复制工作,这时让 nextTable 作为新的 table,并且更新 sizeCtl 为新容量的 0.75 倍 ,完成扩容。
- 图解流程
协助扩容(helpTransfer)方法
在putVal处,有helpTransfer方法,
1 | //发现此处为fwd节点,协助扩容,扩容结束后,再循环回来添加元素 |
1 | final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { |
集合长度累计方式
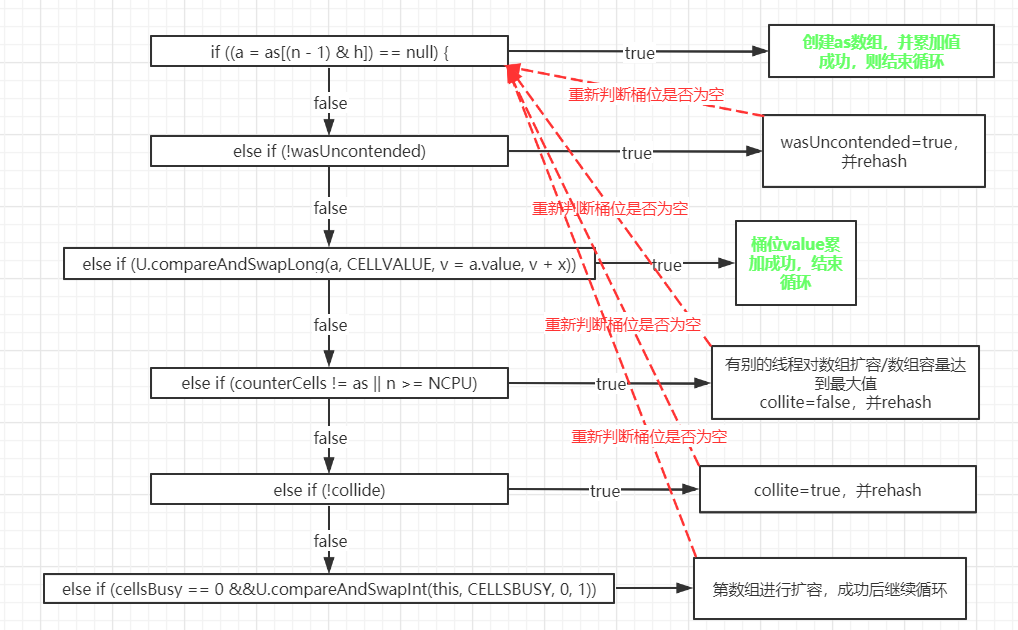
addCount 方法
① CounterCell 数组不为空,优先利用数组中的 CounterCell 记录数量
② 如果数组为空,尝试对 baseCount 进行累加,失败后,会执行 fullAddCount 逻辑
③ 如果是添加元素操作,会继续判断是否需要扩容
1 | private final void addCount(long x, int check) { |
fullAddCount 方法
① 当 CounterCell 数组不为空,优先对 CounterCell 数组中的 CounterCell 的 value 累加
② 当 CounterCell 数组为空,会去创建 CounterCell 数组,默认长度为 2,并对数组中的 CounterCell 的 value 累加
③ 当数组为空,并且此时有别的线程正在创建数组,那么尝试对 baseCount 做累加,成功即返回,否则自旋
1 | private final void fullAddCount(long x, boolean wasUncontended) { |
- 图解流程
集合长度获取方式
size 方法
1 | public int size() { |
sumCount 方法
1 | final long sumCount() { |
注意:这个方法并不是线程安全的
ThreadLocal
ThreadLocal - 一个 Map 的 key
概述
在多线程编程中通常解决线程安全的问题我们会利用 synchronzed 或者 lock 控制线程对临界区资源的同步顺序从而解决线程安全的问题,但是这种加锁的方式会让未获取到锁的线程进行阻塞等待,很显然这种方式的时间效率并不是很好。
线程安全问题的核心在于多个线程会对同一个临界区共享资源进行操作,那么,如果每个线程都使用自己的“共享资源”,各自使用各自的,又互相不影响到彼此即让多个线程间达到隔离的状态,这样就不会出现线程安全的问题。
ThreadLocal 是 JDK 包提供的,它提供线程本地变量,如果创建一个 ThreadLocal 变量,那么访问这个变量的每个线程都会有这个变量的一个副本,在实际多线程操作的时候,操作的是自己本地内存中的变量,从而规避了线程安全问题,如下图所示
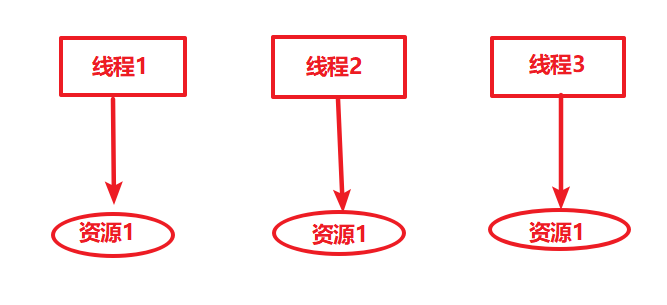
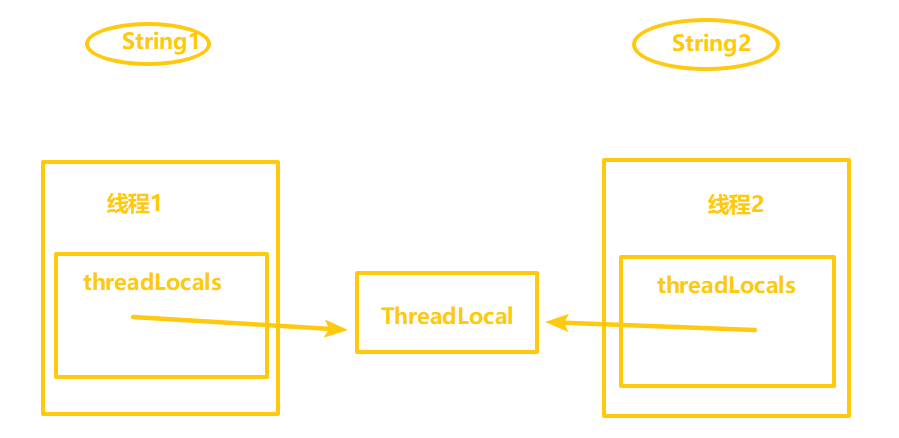
从ThreadLocal 这个类名可以顾名思义的进行理解,表示线程的“本地变量”,即每个线程都拥有该变量副本,达到人手一份的效果,各用各的这样就可以避免共享资源的竞争。
- 注意点
一个 Thread 包含一个 ThreadLocalMap,但可以有多个 ThreadLocal
因为 ThreadLocal 是 Map 的 key,而我们存进去的数据是 Map 的 value
如果感觉有些模糊,不知道什么意思,我们通过学习原理就可以明白了
实现原理
学习实现原理主要根据:set get remove 三个方法入手
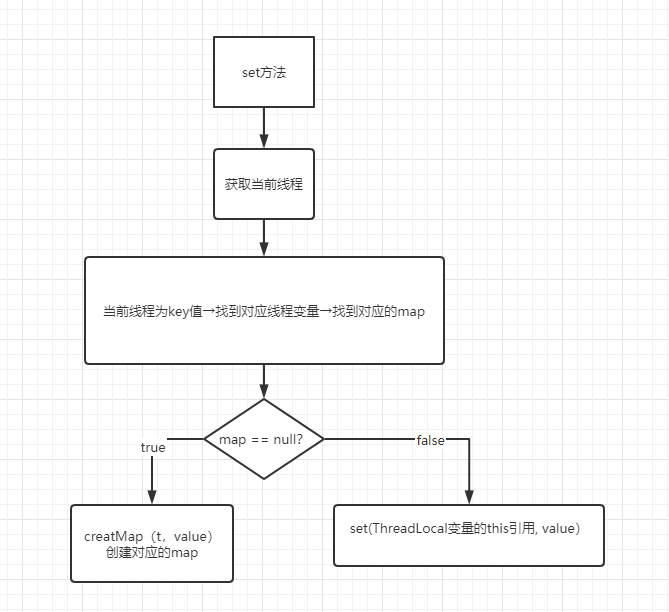
set 方法
set 方法设置在当前线程中 threadLocal 变量的值
源码
1 | public void set(T value) { |
代码流程/细节
方法的逻辑很清晰,具体请看上面的注释。通过源码我们知道 value 是存放在了 ThreadLocalMap 里了,当前先把它理解为一个普普通通的 map 即可,也就是说,数据 value 是真正的存放在了 ThreadLocalMap 这个容器中了,并且是以当前 threadLocal 实例为 key。
先简单的看下 ThreadLocalMap 是什么,有个简单的认识就好,下面会具体说的。
首先 ThreadLocalMap 是怎样来的?源码很清楚,是通过getMap(t)进行获取:
1 | ThreadLocalMap getMap(Thread t) { |
该方法直接返回的就是当前线程对象 t 的一个成员变量 threadLocals:
1 | /* ThreadLocal values pertaining to this thread. This map is maintained |
也就是说ThreadLocalMap 的引用是作为 Thread 的一个成员变量,被 Thread 进行维护的。
回过头再来看看 set 方法,当 map 为 Null 的时候会通过createMap(t,value)方法:
1 | void createMap(Thread t, T firstValue) { |
该方法就是new 一个 ThreadLocalMap 实例对象,然后同样以当前 threadLocal 实例作为 key,值为 value 存放到 threadLocalMap 中,然后将当前线程对象的 threadLocals 赋值为 threadLocalMap。
图解流程
get 方法
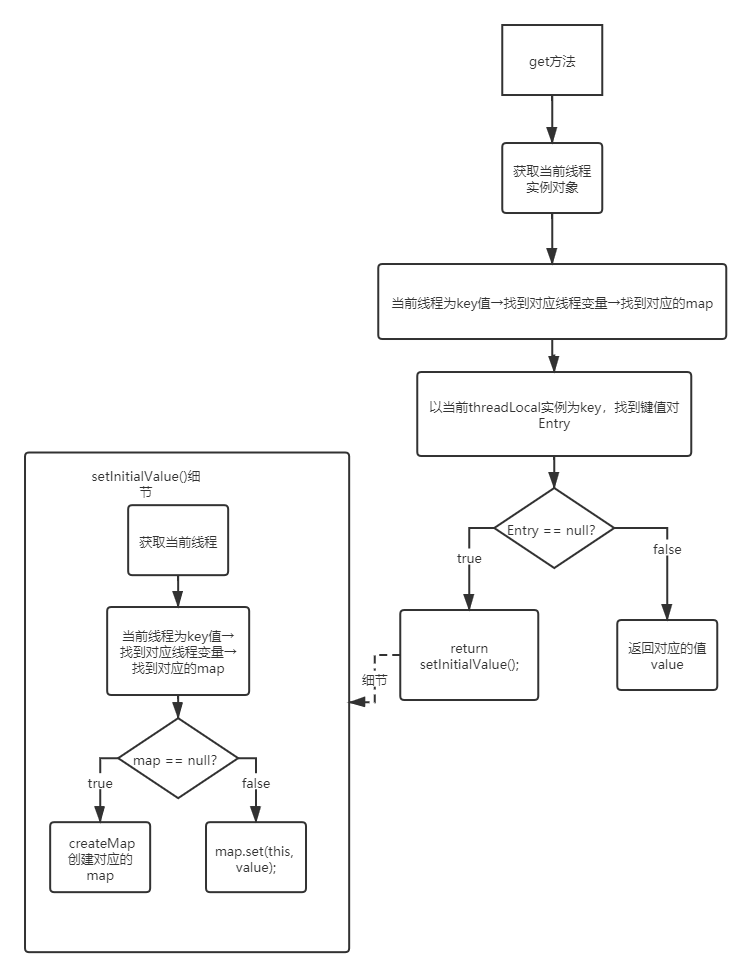
源码
get 方法是获取当前线程中 threadLocal 变量的值
- get 方法源码
1 | public T get() { |
通过代码,我们可以知道 get 其实是一个根据 key 查找 value 的方法,只是存储的 Map,隐藏在当前 Thread 里面
- setInitialValue 方法源码
1 | private T setInitialValue() { |
代码流程/细节
通过当前线程 thread 实例获取到它所维护的 threadLocalMap,然后以当前 threadLocal 实例为 key 获取该 map 中的键值对(Entry),若 Entry 不为 null 则返回 Entry 的 value。如果获取 threadLocalMap 为 null 或者 Entry 为 null 的话,就以当前 threadLocal 为 Key,value 为 null 存入 map 后,并返回null。
图解流程
remove 方法
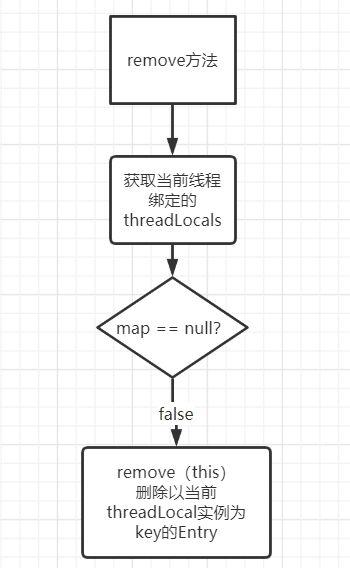
remove 方法判断该当前线程对应的 threadLocals 变量是否为 null,不为 null 就直接删除当前线程中指定的 threadLocals 变量
源码
1 | public void remove() { |
代码流程/细节
删除数据是从 map 中删除数据,先获取与当前线程相关联的 threadLocalMap 然后从 map 中删除该 threadLocal 实例为 key 的键值对即可。
如下图所示:每个线程内部有一个名为 threadLocals 的成员变量,该变量的类型为 ThreadLocal.ThreadLocalMap 类型(类似于一个 HashMap),其中的 key 为当前定义的 ThreadLocal 变量的 this 引用,value 为我们使用 set 方法设置的值。每个线程的本地变量存放在自己的本地内存变量 threadLocals 中,如果当前线程一直不消亡,那么这些本地变量就会一直存在(所以可能会导致内存溢出),因此使用完毕需要将其 remove 掉。
图解流程
ThreadLoacl 底层细节
Entry 数据结构
ThreadLocalMap 是 threadLocal 一个静态内部类,和大多数容器一样内部维护了一个数组,同样的 threadLocalMap 内部维护了一个 Entry 类型的 table 数组。
1 | /** |
- 内部源码
1 | /** |
- 细节
在上面的代码中,我们可以看出,当前 ThreadLocal 的引用 k 被传递给 WeakReference 的构造函数,所以 ThreadLocalMap 中的 key 为 ThreadLocal 的弱引用
弱引用的相关知识在这
每个线程实例中可以通过 threadLocals 获取到 threadLocalMap,而 threadLocalMap 实际上就是一个以 threadLocal 实例为 key,任意对象为 value 的 Entry 数组。
因此:当我们为 threadLocal 变量赋值,实际上就是以当前 threadLocal 实例为 key,值为 value 的 Entry 往这个 threadLocalMap 中存放
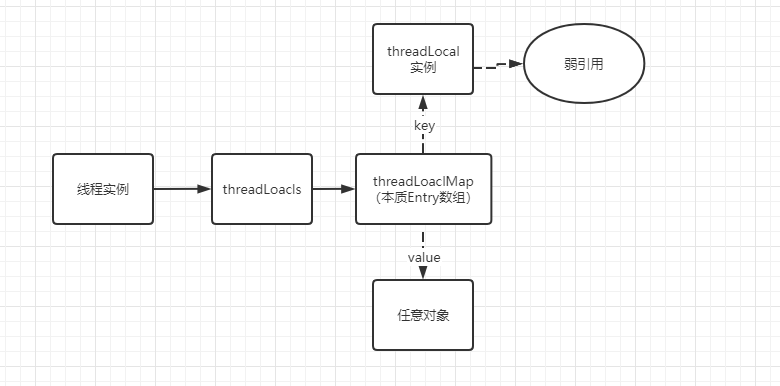
这就可能会导致一个问题:内存泄漏(这里是初步涉及一下,后面再重点学习)
考虑这个 ThreadLocal 变量没有其他强依赖,如果当前线程还存在(比如说线程池,线程执行完一个任务之后不会被销毁,而是会回到线程池中),由于线程的 ThreadLocalMap 里面的 key 是弱引用,所以当前线程的 ThreadLocalMap 里面的 ThreadLocal 变量的弱引用在 gc 的时候就被回收,但是对应的 value 还是存在,即存在一条这样的链路:
Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value
而这个 value 是无法被回收的,这就可能造成内存泄漏(因为这个时候 ThreadLocalMap 会存在 key 为 null 但是 value 不为 null 的 entry 项)
解决办法:使用线程池去维护线程的创建和复用,或及时使用 remove 方法
set 方法细节
散列表
理想状态下,散列表就是一个包含关键字的固定大小的数组,通过使用散列函数,将关键字映射到数组的不同位置。下面是理想散列表的一个示意图:

在理想状态下,哈希函数可以将关键字均匀的分散到数组的不同位置,不会出现两个关键字散列值相同(假设关键字数量小于数组的大小)的情况。但是在实际使用中,经常会出现多个关键字散列值相同的情况(被映射到数组的同一个位置),我们将这种情况称为散列冲突。
为了解决散列冲突,主要采用下面两种方式:
- 分离链表法(separate chaining)
- 开放定址法(open addressing)
分离链表法 与 开放定址法
- 分离链表法
分散链表法使用链表解决冲突,将散列值相同的元素都保存到一个链表中。当查询的时候,首先找到元素所在的链表,然后遍历链表查找对应的元素,典型实现为 hashMap,concurrentHashMap 的拉链法。下面是一个示意图:
- 开放定址法
开放定址法不会创建链表,当关键字散列到的数组单元已经被另外一个关键字占用的时候,就会尝试在数组中寻找其他的单元,直到找到一个空的单元。探测数组空单元的方式有很多,这里介绍一种最简单的 —— 线性探测法。
线性探测法就是从冲突的数组单元开始,依次往后搜索空单元,如果到数组尾部,再从头开始搜索(环形查找)。如下图所示:

ThreadLocalMap 中使用开放地址法来处理散列冲突
HashMap 中使用的分离链表法
究其原因在于:在 ThreadLocalMap 中的散列值分散的十分均匀,很少会出现冲突。并且 ThreadLocalMap 经常需要清除无用的对象,使用纯数组更加方便。
源码
1 | private void set(ThreadLocal<?> key, Object value) { |
一些问题
ThreadLoacl 的 HashCode 如何确定?
1 | private final int threadLocalHashCode = nextHashCode(); |
从源码中我们可以清楚的看到 threadLocal 实例的 hashCode 是通过 nextHashCode()方法实现的,该方法实际上总是用一个 AtomicInteger 加上 0x61c88647 来实现的;那么这个0x61c88647是什么呢?他其实是:Fibonacci Hashing,能够保证 hash 表的每个散列桶能够均匀的分布
怎样确定新值插入到哈希表中的位置?
1 | //根据threadLocal的hashCode确定Entry应该存放的位置 |
本质方法:利用当前 key(即 threadLocal 实例)的 hashcode 与哈希表大小相与;
因为哈希表大小总是为 2 的幂次方,所以相与等同于一个取模的过程,这样就可以通过 Key 分配到具体的哈希桶中去。
采取相与而非与运算,因为位运算效率更高
怎样解决 hash 冲突?
1 | /** |
通过不断向后线性探测,到达末尾时再回到 0 重新开始,呈一个环形。
怎样解决“脏”Entry?
在分析 threadLocal,threadLocalMap 以及 Entry 的关系的时候,我们已经知道使用 threadLocal 有可能存在内存泄漏(对象创建出来后,在之后的逻辑一直没有使用该对象,但是垃圾回收器无法回收这个部分的内存),在源码中针对这种 key 为 null 的 Entry 称之为“stale entry”,直译为不新鲜的 entry,我把它理解为“脏 entry”,
针对这种情况,在 set 方法的 for 循环中寻找和当前 Key 相同的可覆盖 entry 的过程中通过replaceStaleEntry方法解决脏 entry 的问题。如果当前 table[i]为 null 的话,直接插入新 entry 后也会通过cleanSomeSlots来解决脏 entry 的问题
如何进行扩容?
- 扩容阈值 threshold
1 | private int threshold; // Default to 0 |
- 代码流程
根据源码可知,在第一次为 threadLocal 进行赋值的时候会创建初始大小为 16 的 threadLocalMap,并且通过 setThreshold 方法设置 threshold,其值为当前哈希数组长度乘以(2/3),可以理解为加载因子为 2/3
加载因子是衡量哈希表密集程度的一个参数,如果加载因子越大的话,说明哈希表被装载的越多,出现 hash 冲突的可能性越大,反之,则被装载的越少,出现 hash 冲突的可能性越小。同时如果过小,很显然内存使用率不高,该值取值应该考虑到内存使用率和 hash 冲突概率的一个平衡,如 hashMap,concurrentHashMap 的加载因子都为 0.75
这里threadLocalMap 初始大小为 16,加载因子为 2/3,所以哈希表可用大小为:16*2/3=10,即哈希表可用容量为 10。
- 扩容 resize
当我们的 hash 表 size 值大于阈值 threshold,将触发 resize 方法,进行扩容
1 | /** |
- 新建一个大小为原来数组长度的两倍的数组
- 遍历旧数组中的 entry 并将其插入到新的 hash 数组中
注意点:在扩容的过程中针对脏 entry 的话会令 value 为 null,以便能够被垃圾回收器能够回收,解决隐藏的内存泄漏的问题
getEntry 方法
源码
1 | private Entry getEntry(ThreadLocal<?> key) { |
方法逻辑
若能当前定位的 entry 的 key 和查找的 key 相同的话就直接返回这个 entry,否则的话就是在 set 的时候存在 hash 冲突的情况,需要通过 getEntryAfterMiss 做进一步处理
- getEntryAfterMiss 源码
1 | private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) { |
这个方法同样很好理解,通过 nextIndex 往后环形查找,如果找到和查询的 key 相同的 entry 的话就直接返回,如果在查找过程中遇到脏 entry 的话使用 expungeStaleEntry 方法进行处理
图解流程
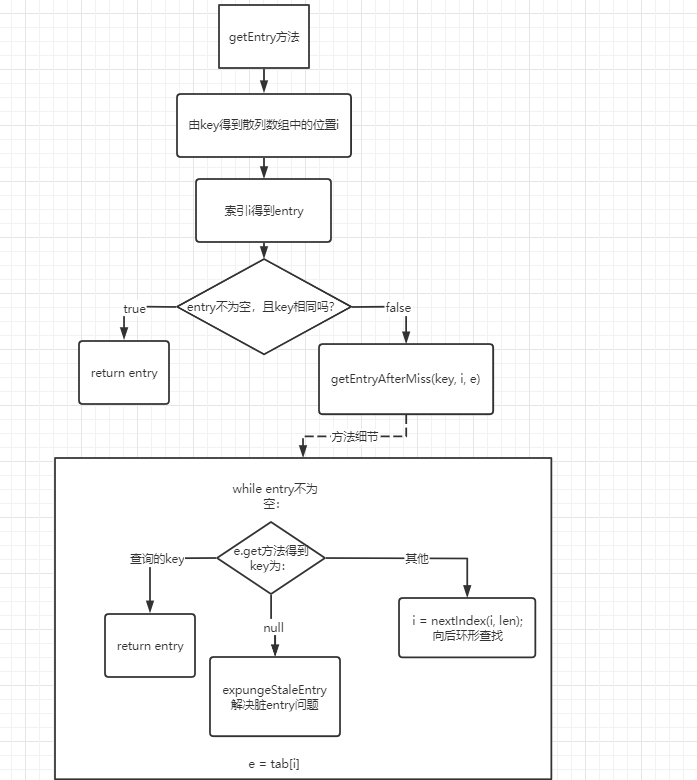
remove 方法
源码
1 | /** |
代码逻辑
通过传入的 key 获取索引 i,环形遍历表中的 entry,如果找到与指定 key 相同的 entry,先通过 clear 方法将 key 置为 null 后,使其转换为一个脏 entry,然后调用 expungeStaleEntry 方法将其 value 置为 null,以便垃圾回收时能够清理,同时将 table[i]置为 null。
图解流程
内存泄漏问题
- 引入
在[内存泄漏初认识](# Entry 数据结构)处,我们已经初步知道了什么是内存泄漏;接下来就学习下如何去解决这个问题
问题解决
在上面的 set 方法中,我们遇到了两个方法:
1 | replaceStaleEntry(key, value, i); |
这两个方法用于处理【脏 Entry】 —— key 为 null 的 Entry
- 出现 hash 冲突的时候,或是遇到脏数据的时候,使用
replaceStaleEntry进行处理 - 在插入了新的 Entry 后,会调用
cleanSomeSlots去检测并清除脏数据
cleanSomeSlots 方法
cleanSomeSlots 方法用于检测,清除【脏 Entry】
源码
1 | /* @param i a position known NOT to hold a stale entry. The |
expungeStaleEntry 方法
- 源码
1 | /** |
- 方法逻辑
- 清理当前脏 entry,即将其 value 引用置为 null,并且将 table[staleSlot]也置为 null。value 置为 null 后该 value 域变为不可达,在下一次 gc 的时候就会被回收掉,同时 table[staleSlot]为 null 后以便于存放新的 entry;
- 从当前 staleSlot 位置向后环形(nextIndex)继续搜索,直到遇到哈希桶(tab[i])为 null 的时候退出;
- 若在搜索过程再次遇到脏 entry,继续将其清除。
也就是说该方法,清理掉当前脏 entry 后,并没有闲下来继续向后搜索,若再次遇到脏 entry 继续将其清理,直到哈希桶(table[i])为 null 时退出
方法执行后结果: 从当前脏 entry(staleSlot)位到返回的 i 位,这中间所有的 entry 不是脏 entry
为什么是遇到 null 时退出?原因是存在脏 entry 的前提条件是 当前哈希桶(table[i])不为 null,只是该 entry 的 key 域为 null。如果遇到哈希桶为 null,代表着其根本就不是一个键值对 Entry,那更不可能是一个脏的 Entry
总结
- 运行流程
- 从当前位置 i 处(位于 i 处的 entry 一定不是脏 entry)为起点在初始小范围(log2(n),n 为哈希表已插入 entry 的个数 size)开始向后搜索脏 entry,若在整个搜索过程没有脏 entry,方法结束退出
- 如果在搜索过程中遇到脏 entryt 通过 expungeStaleEntry 方法清理掉当前脏 entry,并且该方法会返回下一个哈希桶(table[i])为 null 的索引位置为 i。这时重新令搜索起点为索引位置 i,n 为哈希表的长度 len,再次扩大搜索范围为 log2(n’)继续搜索。
- 例子
如图当前 n 等于 hash 表的 size 即 n=10,i=1,在第一趟搜索过程中通过 nextIndex,i 指向了索引为 2 的位置,此时 table[2]为 null,说明第一趟未发现脏 entry,则第一趟结束进行第二趟的搜索。
第二趟所搜先通过 nextIndex 方法,索引由 2 的位置变成了 i=3,当前 table[3]!=null 但是该 entry 的 key 为 null,说明找到了一个脏 entry,先将 n 置为哈希表的长度 len,然后继续调用 expungeStaleEntry 方法,该方法会将当前索引为 3 的脏 entry 给清除掉(令 value 为 null,并且 table[3]也为 null),但是该方法可不想偷懒,它会继续往后环形搜索,往后会发现索引为 4,5 的位置的 entry 同样为脏 entry,索引为 6 的位置的 entry 不是脏 entry 保持不变,直至 i=7 的时候此处 table[7]位 null,该方法就以 i=7 返回。至此,第二趟搜索结束;
由于在第二趟搜索中发现脏 entry,n 增大为数组的长度 len,因此扩大搜索范围(增大循环次数)继续向后环形搜索;
直到在整个搜索范围里都未发现脏 entry,cleanSomeSlot 方法执行结束退出。
replaceStaleEntry
- 源码
1 | /* |
BlockingQueue - 阻塞队列
概述
最常用的”生产者-消费者“问题中,队列通常被视作线程间操作的数据容器,这样,可以对各个模块的业务功能进行解耦,生产者将“生产”出来的数据放置在数据容器中,而消费者仅仅只需要在“数据容器”中进行获取数据即可,这样生产者线程和消费者线程就能够进行解耦,只专注于自己的业务功能即可。
阻塞队列(BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是 BlockingQueue 提供了可阻塞的插入和移除的方法。
当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
基本操作 - 接口
BlockingQueue 基本操作总结如下(此图来源于 JAVA API 文档):

- BlockingQueue 继承于 Queue 接口,因此,对数据元素的基本操作有:
插入元素
- add(E e) :往队列插入数据,当队列满时,插入元素时会抛出 IllegalStateException 异常;
- offer(E e):当往队列插入数据时,插入成功返回
true,否则则返回false。当队列满时不会抛出异常;
删除元素
- remove(Object o):从队列中删除数据,成功则返回
true,否则为false - poll:删除数据,当队列为空时,返回 null;
查看元素
- element:获取队头元素,如果队列为空时则抛出 NoSuchElementException 异常;
- peek:获取队头元素(不会删除头结点),如果队列为空则抛出 NoSuchElementException 异常
- BlockingQueue 具有的特殊操作:
插入数据:
- put:当阻塞队列容量已经满时,往阻塞队列插入数据的线程会被阻塞,直至阻塞队列已经有空余的容量可供使用;
- offer(E e, long timeout, TimeUnit unit):若阻塞队列已经满时,同样会阻塞插入数据的线程,直至阻塞队列已经有空余的地方,与 put 方法不同的是,该方法会有一个超时时间,若超过当前给定的超时时间,插入数据的线程会退出;
删除数据
- take():当阻塞队列为空时,获取队头数据的线程会被阻塞;
- poll(long timeout, TimeUnit unit):当阻塞队列为空时,获取数据的线程会被阻塞,另外,如果被阻塞的线程超过了给定的时长,该线程会退出(该方法可以获取队列的头结点,且会删除此结点)
阻塞队列
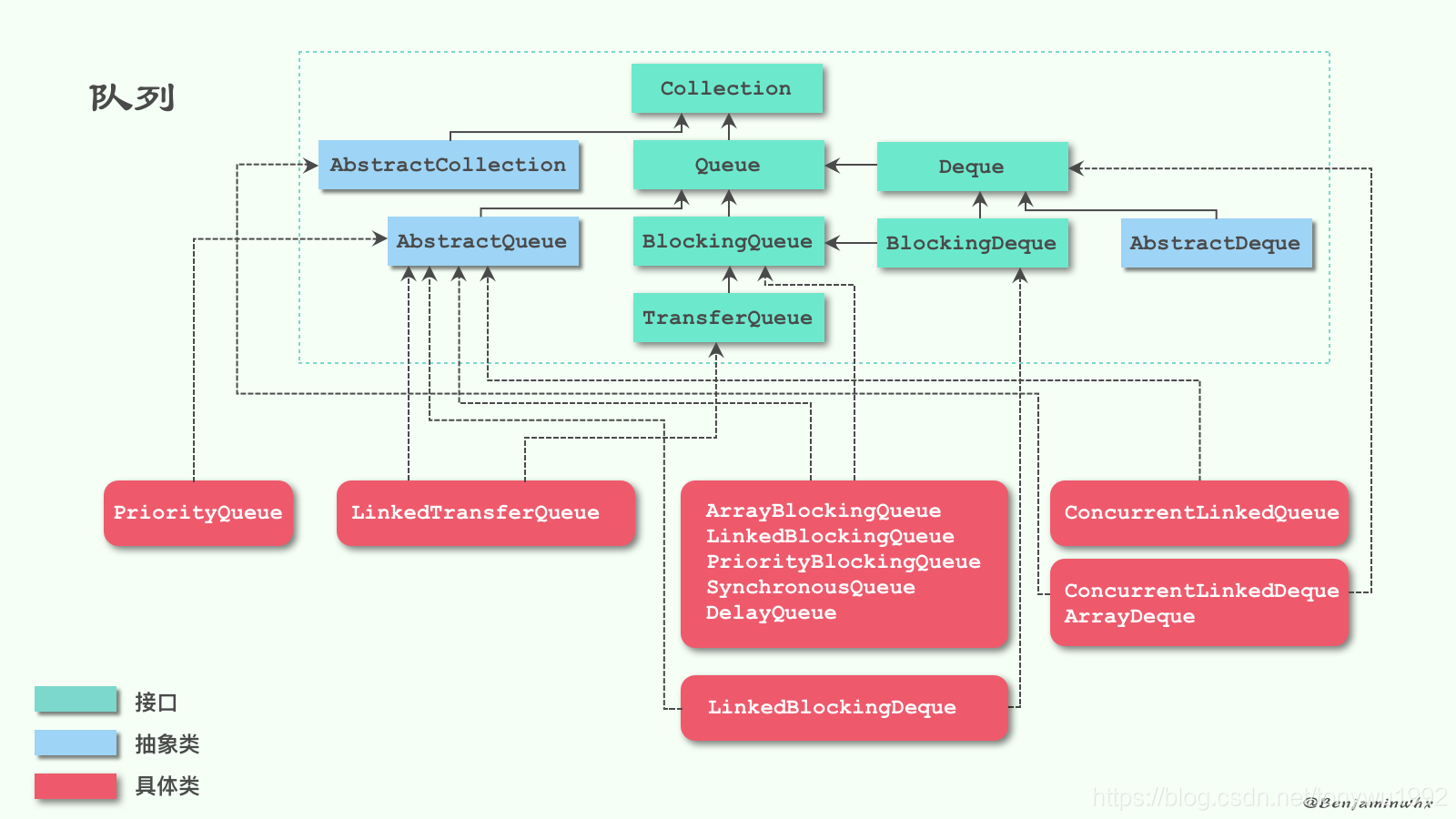
- 阻塞队列分别为:
- ArrayBlockingQueue - 有界队列(数组)
- *LinkedBlockingQueue - 有界队列(链表) *
- PriorityBlockingQueue - 无界(优先)阻塞队列(数组)
- SynchronousQueue - 同步队列
- LinkedTransferQueue - 无界阻塞队列(链表)
- LinkedBlockingDeque - 有界阻塞双端队列(链表)
- DelayQueue - 延时无界阻塞队列(数组)
ArrayBlockingQueue
ArrayBlockingQueue
ArrayBlockingQueue是由数组实现的有界阻塞队列。该队列命令元素 FIFO(先进先出)。因此,对头元素时队列中存在时间最长的数据元素,而对尾数据则是当前队列最新的数据元素。ArrayBlockingQueue 可作为“有界数据缓冲区”,生产者插入数据到队列容器中,并由消费者提取。ArrayBlockingQueue 一旦创建,容量不能改变。
当队列容量满时,尝试将元素放入队列将导致操作阻塞;尝试从一个空队列中取一个元素也会同样阻塞。
ArrayBlockingQueue 默认情况下不能保证线程访问队列的公平性,所谓公平性是指严格按照线程等待的绝对时间顺序,即最先等待的线程能够最先访问到 ArrayBlockingQueue。而非公平性则是指访问 ArrayBlockingQueue 的顺序不是遵守严格的时间顺序,有可能存在,一旦 ArrayBlockingQueue 可以被访问时,长时间阻塞的线程依然无法访问到 ArrayBlockingQueue。
如果保证公平性,通常会降低吞吐量。如果需要获得公平性的 ArrayBlockingQueue,可采用如下代码:
1 | private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true); |
主要属性
1 | private static final long serialVersionUID = -817911632652898426L; |
入队方法
| 序号 | 方法名 | 队列满时处理方式 | 方法返回值 |
|---|---|---|---|
| 1 | add(E e) | 抛出“Queue full”异常 | boolean |
| 2 | offer(E e) | 返回 false | boolean |
| 3 | put(E e) | 线程阻塞,直到中断或被唤醒 | void |
| 4 | offer(E e, long timeout, TimeUnit unit) | 在规定时间内重试,超过规定时间返回 false | boolean |
- add 方法、offer 方法与 enqueue 方法
1 | // 调用AbstractQueue父类中的方法。 |
add 方法 → offer 方法 → enqueue 方法,因此本质是调用enqueue
1 | private void enqueue(E x) { |
图解流程的话:
- put 方法
1 | public void put(E e) throws InterruptedException { |
从源码中可以看出来,区别于add 方法的地方在于:如果队列满时,是使用notFull.await();进行等待,而add 方法会抛出异常
出队方法
| 序号 | 方法名 | 队列空时处理方式 | 方法返回值 |
|---|---|---|---|
| 1 | remove() | 抛出异常 | E |
| 2 | poll() | 返回 null | E |
| 3 | take() | 线程阻塞,指定中断或被唤醒 | E |
| 4 | poll(long timeout, TimeUnit unit) | 在规定时间内重试,超过规定时间返回 null | E |
- remove 方法、poll 方法与 dequeue()方法
1 | public E remove() { |
remove 方法 → poll 方法 → dequeue 方法,因此本质是调用dequeue
1 | // 删除队列头的元素,返回它 |
关于 itrs.elementDequeued():ArrayBlockingQueue 中,实现了迭代器的功能,也就是可以通过迭代器来遍历阻塞队列中的元素
所以 itrs.elementDequeued() 是用来更新迭代器中的元素数据的
同样,图解流程:
- take 方法
1 | public E take() throws InterruptedException { |
从源码中可以看出来,区别于remove 方法的地方在于:如果队列空时,是使用notEmpty.await();进行等待,而remove 方法会抛出异常
查看方法
1 | // 调用AbstractQueue父类中的方法。 |
LinkedBlockingQueue
主要属性
1 | // 容量 |
内部类
1 | static class Node<E> { |
入队方法
void put(E e); 如果队列满了,一直阻塞,直到队列不满了或者线程被中断–>阻塞
boolean offer(E e);如果队列没满,立即返回 true; 如果队列满了,立即返回 false–>不阻塞
boolean offer(E e, long timeout, TimeUnit unit); 在队尾插入一个元素,,如果队列已满,则进入等待,直到出现以下三种情况:–>阻塞
- 被唤醒
- 等待时间超时
- 当前线程被中断
- put(E e)
1 | public void put(E e) throws InterruptedException { |
方法逻辑:
- 队列已满,阻塞等待。
- 队列未满,创建一个 node 节点放入队列中,如果放完以后队列还有剩余空间,继续唤醒下一个添加线程进行添加。如果放之前队列中没有元素,放完以后要唤醒消费线程进行消费。
- offer(E e)
1 | public boolean offer(E e) { |
大体逻辑与 put 方法相同,区别在于:当队列没有可用元素的时候,不同于 put 方法的阻塞等待,offer 方法直接方法 false
- signalNotEmpty 方法
1 | private void signalNotEmpty() { |
逻辑:获取了 take 锁,先上锁,然后唤醒消费者线程,最后释放锁;
- enqueue 方法
1 | /** |
出队方法
- E take(); 如果队列空了,一直阻塞,直到队列不为空或者线程被中断–>阻塞
- E poll(); 如果没有元素,直接返回 null;如果有元素,出队
- E poll(long timeout, TimeUnit unit); 如果队列不空,出队;如果队列已空且已经超时,返回 null;如果队列已空且时间未超时,则进入等待,直到出现以下三种情况:
- 被唤醒
- 等待时间超时
- 当前线程被中断
- take 方法
1 | public E take() throws InterruptedException { |
方法逻辑:
- 队列为空,阻塞等待。
- 队列不为空,从队首获取并移除一个元素,如果消费后还有元素在队列中,继续唤醒下一个消费线程进行元素移除。如果放之前队列是满元素的情况,移除完后要唤醒生产线程进行添加元素。
- poll 方法
1 | public E poll() { |
大体逻辑与 take 方法相同,只是在队列满的时候,take 方法进行阻塞等待,poll 方法会 return null;
- signalNotFull 方法
1 | /** |
逻辑:获取了 put 锁,先上锁,然后唤醒生产者线程,最后释放锁;
- dequeue 方法
1 | private E dequeue() { |
ArrayBlockingQueue 与 LinkedBlockingQueue 对比
- ArrayBlockingQueue:
- 一个对象数组+一把锁+两个条件
- 入队与出队都用同一把锁
- 在只有入队高并发或出队高并发的情况下,因为操作数组,且不需要扩容,性能很高
- 采用了数组,必须指定大小,即容量有限
- LinkedBlockingQueue:
- 一个单向链表+两把锁+两个条件
- 两把锁,一把用于入队,一把用于出队,有效的避免了入队与出队时使用一把锁带来的竞争。
- 在入队与出队都高并发的情况下,性能比 ArrayBlockingQueue 高很多
- 采用了链表,最大容量为整数最大值,可看做容量无限
线程池
概述
- 为什么要使用线程池?
在实际使用中,线程是很占用系统资源的,如果对线程管理不善很容易导致系统问题。因此,在大多数并发框架中都会使用线程池来管理线程,使用线程池管理
假设一个服务器完成一项任务所需时间为:T1 创建线程时间,T2 在线程中执行任务的时间,T3 销毁线程时间。如果:T1+T3 远大于 T2,则可以采用线程池,实现对线程的复用,以提高服务器性能。
线程主要有如下好处:
- 降低资源消耗。通过复用已存在的线程和降低线程关闭的次数来尽可能降低系统性能损耗;
- 提升系统响应速度。通过复用线程,省去创建线程的过程,因此整体上提升了系统的响应速度;
- 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,因此,需要使用线程池来管理线程。
- 线程池继承关系

- 线程池的组成部分
- 线程池管理器:创建并管理线程池。例如创建线程池、销毁线程池、添加新任务等等。
- 工作线程:线程池中的工作线程。空闲时处于空闲状态,可以循环的执行任务。
- 任务接口:每个任务必须实现任务接口,以供工作线程调度任务的执行。
- 任务队列:存放待处理任务的队列。
工作原理
从图可以看出,线程池执行所提交的任务过程主要有这样几个阶段:
- 先判断线程池中核心线程池所有的线程是否都在执行任务。如果不是,则新创建一个线程执行刚提交的任务,否则,核心线程池中所有的线程都在执行任务,则进入第 2 步;
- 判断当前阻塞队列是否已满,如果未满,则将提交的任务放置在阻塞队列中;否则,则进入第 3 步;
- 判断线程池中所有的线程是否都在执行任务,如果没有,则创建一个新的线程来执行任务,否则,则交给饱和策略进行处理
线程池 - 创建
线程池参数说明
- 线程池构造方法
1 | /** |
对于各个参数的说明:
| 字段名称 | 描述 |
|---|---|
| corePoolSize | 线程池核心线程数(平时保留的线程数),创建后不会关闭的线程数量,如果设置了allowCoreThreadTimeout后,空闲时间超时后还是会关闭。执行任务时,没有达到核心线程数的话,是会直接创建新的线程。 |
| maximumPoolSize | 规定线程池最多只能有多少个线程(worker)在执行。当核心线程数和任务队列也都满了,不能添加任务的时候,这个参数才会生效。如果当前有效工作线程数量小于最大线程数量,会再创建新的线程。 |
| keepAliveTime | 超出 corePoolSize 数量的线程的保留时间。 |
| unit | keepAliveTime 的时间单位。 |
| workQueue | 任务队列,为阻塞队列BlockingQueue的实现。线程池会先满足corePoolSize的限制,在核心线程数满了后,将任务加入队列。但队列也满了后,线程数小于maximumPoolSize,线程池继续创建线程。 |
| threadFactory | 线程创建工厂,可以用来配置线程的命名、是否是守护线程、优先级等等。 |
| handler | 拒绝处理器,为RejectedExecutionHandler的实现类。当任务队列满负荷,已经达到最大线程数,把新加入的任务交给这个 handler 进行处理。线程池默认使用AbortPolicy(直接抛弃)策略,直接抛出异常。 |
| allowCoreThreadTimeout | 核心线程的空闲时间也要进行超时限制,也就是keepAliveTime的限制。如果配置为 true 后,所有的线程空闲时间超时后,都会进行线程退出操作。 |
- 关于四种拒绝处理器饱和策略:
AbortPolicy(中止策略):直接抛弃。
CallerRunsPolicy(调用者运行策略):用调用者的线程执行任务。
DiscardPolicy(丢弃策略):抛弃当前任务。
DiscardOldestPolicy(弃老策略):抛弃队列中最久的任务。
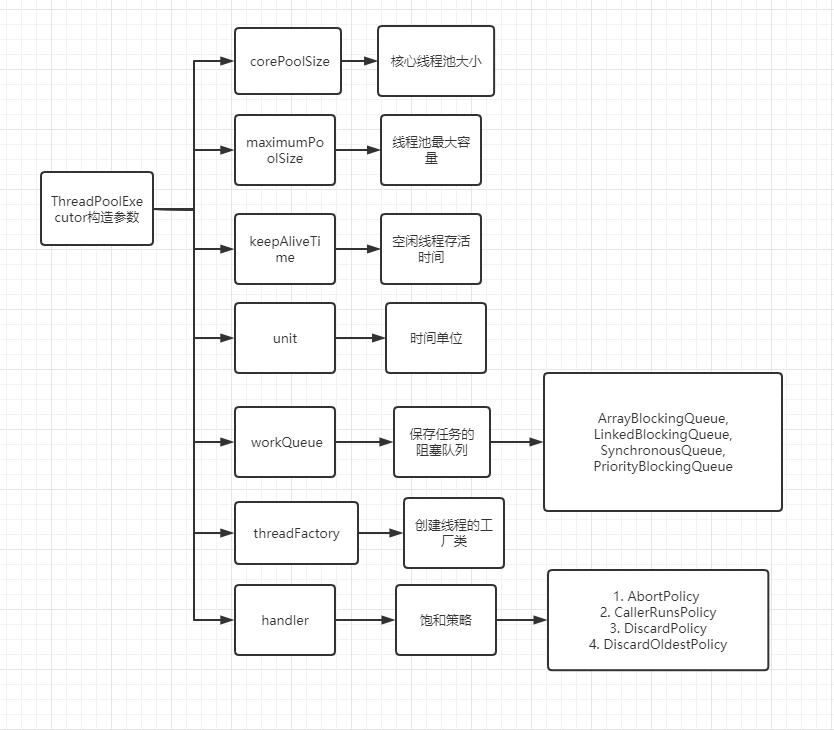
线程池 - 提交
线程池创建之后,后面就是要提交任务执行了,通常是使用使用线程池自带的submit 或者 excute 方法,然后用 lambda 表达式传入函数体后,就可以执行任务了
而submit的方法本质上也是调用的execute方法,因此只需要学习execute方法即可
- 使用 Thread 创建启动线程
1 | Thread t = new Thread(); |
- 使用 Executor 启动线程执行任务
1 | Thread t = new Thread(); |
对于不同的 Executor 实现,execute()方法可能是创建一个新线程并立即启动,也有可能是使用已有的工作线程来运行传入的任务,也可能是根据设置线程池的容量或者阻塞队列的容量来决定是否要将传入的线程放入阻塞队列中或者拒绝接收传入的线程。
execute 源码
execute 方法主要含义:通过调用这个方法可以向线程池提交一个任务,交由线程池去执行
1 | public void execute(Runnable command) { |
execute 执行流程
- 执行流程
- 如果
workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务; - 如果
workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中; - 如果
workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务; - 如果
workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。
这里要注意一下addWorker(null, false);,也就是创建一个线程,但并没有传入任务,因为任务已经被添加到 workQueue 中了,所以 worker 在执行的时候,会直接从 workQueue 中获取任务。所以,在workerCountOf(recheck) == 0时执行addWorker(null, false);也是为了保证线程池在 RUNNING 状态下必须要有一个线程来执行任务。
- 图解方法流程
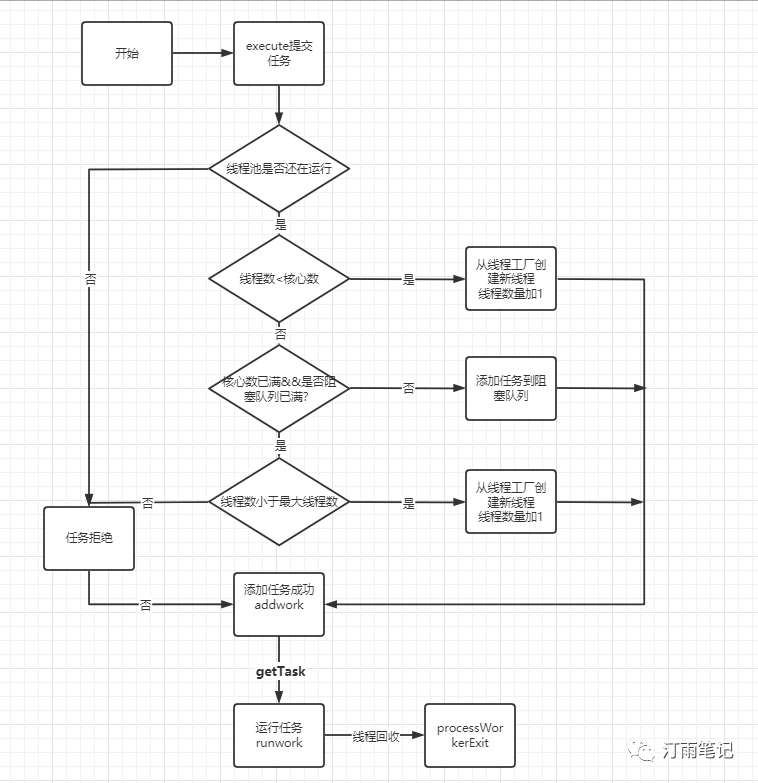
addWorker
- 作用:addWorker 方法的主要工作是在线程池中创建一个新的线程并执行=
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
addWorker 方法的主要工作是在线程池中创建一个新的线程并执行,其中firstTask 参数指定的是新线程需要执行的第一个任务,core 参数决定于活动线程数的比较对象是 corePoolSize 还是 maximumPoolSize。
根据传进来的参数首先对线程池和队列的状态进行判断,满足条件就新建一个 Worker 对象,并实例化该对象的线程,最后启动线程。
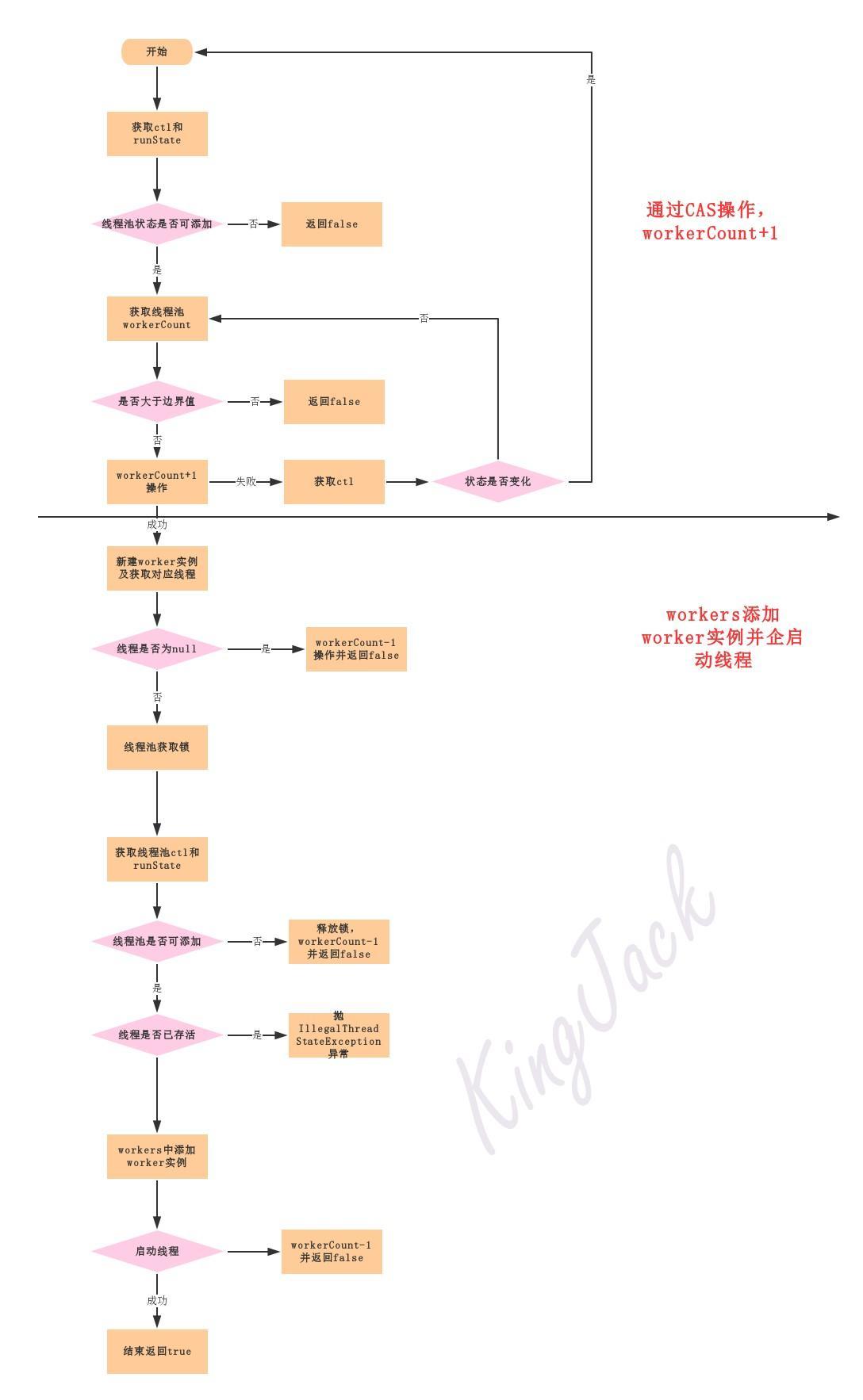
runworker
- 源码
1 | final void runWorker(Worker w) { |
- 流程
- 首先在方法一进来,就执行了 w.unlock(),这是为了将 AQS 的状态改为 0,因为只有 getState() >= 0 的时候,线程才可以被中断;
- 判断 firstTask 是否为空,为空则通过 getTask()获取任务,不为空接着往下执行
- 判断是否符合中断状态,符合的话设置中断标记
- 执行 beforeExecute(),task.run(),afterExecute()方法
- 任何一个出异常都会导致任务执行的终止;进入 processWorkerExit 来退出任务
- 正常执行的话会接着回到步骤 2
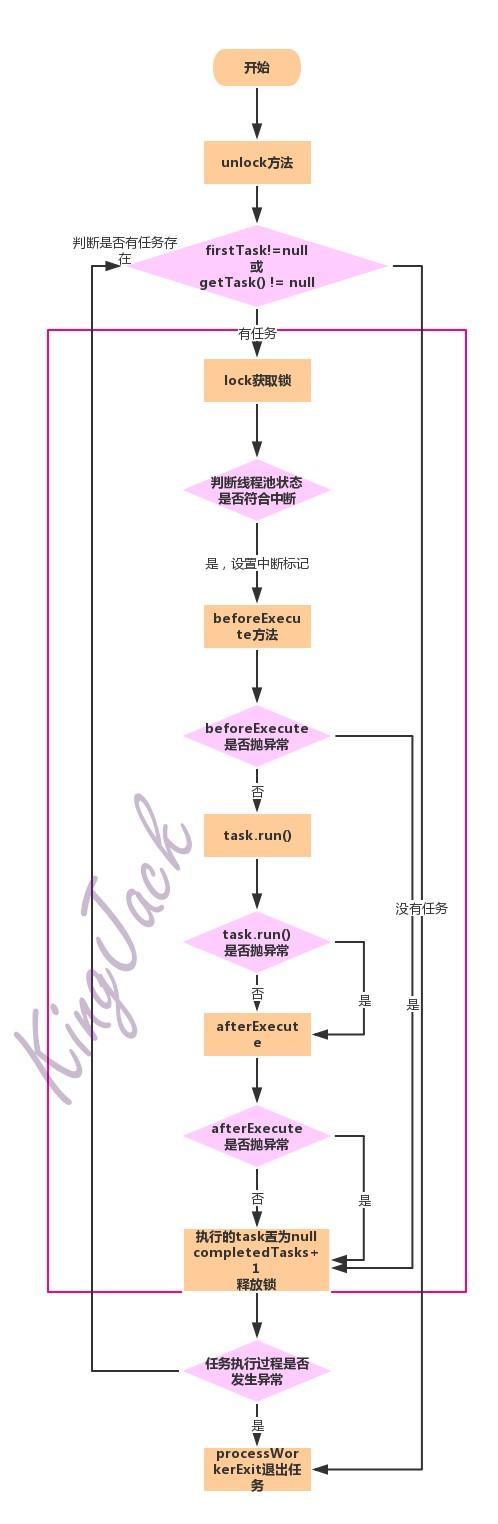
getTask
- 源码
1 | private Runnable getTask() { |
- 流程
- 获取线程池控制状态和 runState,判断线程池是否已经关闭或者正在关闭,是的话则 workerCount-1 操作返回 null
- 获取 workerCount 判断是否大于核心线程池
- 判断 workerCount 是否大于最大线程池数目或者已经超时,是的话 workerCount-1,-1 成功则返回 null,不成功则回到步骤 1 重新继续
- 判断 workerCount 是否大于核心线程池,大于则用 poll 方法从队列获取任务,否则用 take 方法从队列获取任务
- 判断任务是否为空,不为空则返回获取的任务,否则回到步骤 1 重新继续
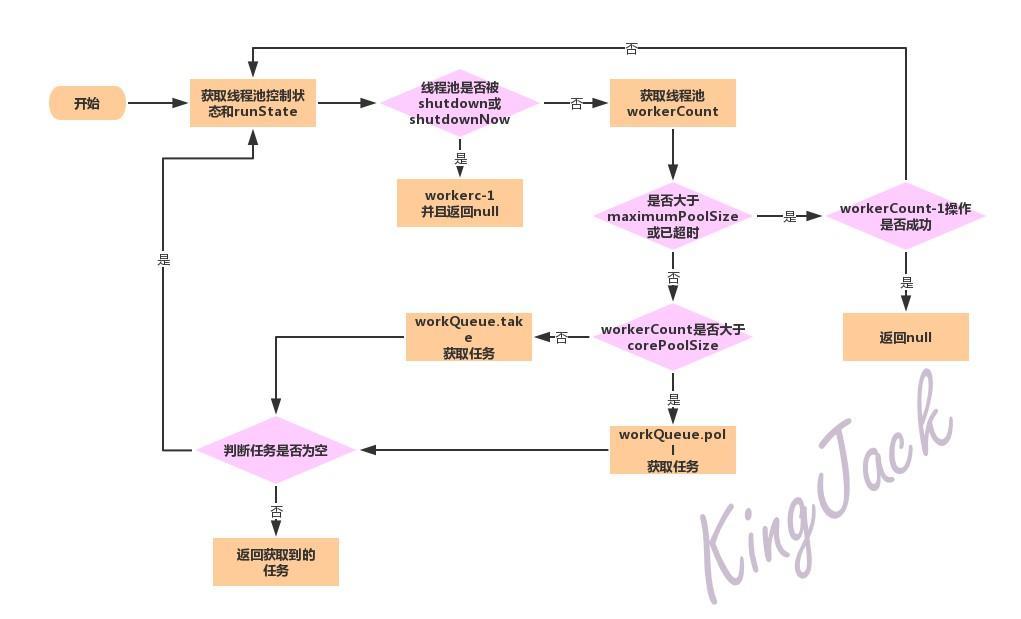
processWorkerExit
从名称来看 Process Worker Exit:任务过程 退出,当任务执行完或者出现异常中断执行,强制被退出的时候,会有相应的操作,这个方法就是这个【相应的操作】
- 源码
1 | private void processWorkerExit(Worker w, boolean completedAbruptly) { |
线程池 - 关闭
ThreadPoolExecutor 提供了两个方法,用于线程池的关闭,分别是shutdown()和shutdownNow():
- shutdown 方法
1 | public void shutdown() { |
- shutdownNow 方法
1 | public List<Runnable> shutdownNow() { |
线程池 - 监控
通过线程池提供的参数进行监控。线程池里有一些属性在监控线程池的时候可以使用
- getTaskCount:线程池已经执行的和未执行的任务总数;
- getCompletedTaskCount:线程池已完成的任务数量,该值小于等于 taskCount;
- getLargestPoolSize:线程池曾经创建过的最大线程数量。通过这个数据可以知道线程池是否满过,也就是达到了 maximumPoolSize;
- getPoolSize:线程池当前的线程数量;
- getActiveCount:当前线程池中正在执行任务的线程数量。
通过这些方法,可以对线程池进行监控,在 ThreadPoolExecutor 类中提供了几个空方法,如 beforeExecute 方法,afterExecute 方法和 terminated 方法,可以扩展这些方法在执行前或执行后增加一些新的操作,例如统计线程池的执行任务的时间等,可以继承自 ThreadPoolExecutor 来进行扩展。
线程协作
技术参考
博客
(java 并发理解)https://blog.csdn.net/jackfrued/article/details/44499227
(Java 内存模型)https://www.cnblogs.com/yuanfy008/p/9252555.html
https://www.cnblogs.com/konck/p/9292584.html
(Java 内存模型和 JVM 内存管理)https://www.cnblogs.com/yjd_hycf_space/p/7505372.html
(happens-before) http://cmsblogs.com/?p=2102
(volatile 关键字的应用)https://www.cnblogs.com/daxin/p/3364014.html
(volatile 解决了什么问题?)https://blog.csdn.net/duqi_2009/article/details/94939145
(线程同步 - synchronized 与锁) https://www.cnblogs.com/uodut/p/6775419.html
(深入分析 Synchronized 实现原理) https://blog.csdn.net/chenssy/article/details/54883355
(Java 并发 -对象头)https://blog.csdn.net/cold___play/article/details/104494045
(Synchronized 实现原理与应用) https://blog.csdn.net/u012465296/article/details/53022317
(深入理解 Java 并发之 synchronized 实现原理)https://blog.csdn.net/javazejian/article/details/72828483
(synchronized 的三种应用方式) https://blog.csdn.net/Kurry4ever_/article/details/109560858
(简单描述一下 synchronized 三种应用方法) https://blog.csdn.net/weixin_44040505/article/details/102731061
(Synchronized 底层实现 - 概论、偏向锁、轻量级锁和重量级锁) https://github.com/farmerjohngit/myblog/issues/12
(锁膨胀原理分析 基于 JDK6 后) https://blog.csdn.net/qq_33762302/article/details/114297801
(synchronized 关键字深度解析 - 批量重定向/撤销) https://www.cnblogs.com/zzq6032010/p/11967179.html
(锁粗化与锁消除技术演示分析) https://www.cnblogs.com/webor2006/p/11448673.html
(volatile 可见性 有序性 - 内存层面上实现)https://segmentfault.com/a/1190000014830955
(内存屏障 - 分类)https://blog.csdn.net/z55887/article/details/80836313
(写缓存 Store Buffer 与 无效化队列)https://blog.csdn.net/weixin_44936828/article/details/89430358
(可见性与有序性问题 volatile 底层细节)https://www.freesion.com/article/9021645644/
(可见性与有序性问题)https://bbs.huaweicloud.com/blogs/239766
(synchronized 学习 - 实现原理 - 优化 -例子)https://juejin.cn/post/6844903600334831629
(深入理解 AQS)https://www.jianshu.com/p/cc308d82cc71
(ReentanLock 底层理解)https://blog.csdn.net/fuyuwei2015/article/details/83719444
(从底层深入解析读写锁)https://blog.csdn.net/chongshizhuo8736/article/details/101042514
(死磕 Java 并发 读写锁源码分析)https://zhuanlan.zhihu.com/p/137797509
(例子讲解锁降级)https://www.cnblogs.com/takemybreathaway/articles/9399914.html
(详解等待队列和同步队列的关系)https://www.freesion.com/article/6246850783/
(LockSupport)https://blog.csdn.net/a1036645146/article/details/105635421
(ThreadLoacl)https://www.cnblogs.com/fsmly/p/11020641.html#_label0
(关于 Hash)http://faculty.cs.niu.edu/~freedman/340/340notes/340hash.htm
(详解 ThreadLoacl)https://www.cnblogs.com/zhangjk1993/archive/2017/03/29/6641745.html
(ArrayBlockingQueue 实现原理 1)https://www.cnblogs.com/teach/p/10665199.html
(LinkedBlockingQueue)https://blog.csdn.net/tonywu1992/article/details/83419448
(详细分析 Java 并发集合 ArrayBlockingQueue 用法 - 这个确实讲的可以)https://www.jb51.net/article/137750.htm
(LinkedBlockingQueue 源码解析)https://www.cnblogs.com/java-zhao/p/5135958.html
书籍文献
- 《java 并发编程的艺术》
- 《疯狂 java 讲义》
视频




