并行处理及分布式系统
缓存 Cache 相关知识点
由于计算速度存储器访存速度不一致,为了解决这个问题,引入了缓存。
缓存其实是基于:【空间局部性原理】
为了运用局部性原理,系统使用更宽的互连结构来访问数据和指令。也就是:一次内存访问能存取一整块代码和数据,而不只是单条指令和单条数据。
这些块称为高速缓存块或者高速缓存行。一个典型的高速缓存行能存储 8~l6 倍单个内存区域的信息。在我们的例子中,如果一个高 ⒆ 速缓存行可以存放 16 个浮点数,当执行 sum+ =z[0]时,系统可能把数组 z 最开始的 16 个元素:z[0]、z[1]、…、z[15]从主存读到 Cache 中。因此,在后面的 15 次加法运算中,需要使用的数据已经在 Cache 中。
缓存一致性问题
当 CPU 向 Cache 写数据时,会出现 Cache 中的值与主存中的值不一致的情况,为了解决这个问题,有两种方法解决:
- 写直达:当 CPU 向 Cache 写数据时,更新主存中的数据
- 写回:将 Cache 中的数据标记为脏数据,当 Cache line 被主存中的新的 Cache line 替换时,脏的 Cache line 会被写入主存。
监听
- 多个核共享总线
- 在总线上传输的任何信号都可以被连接到总线的所有核“看”到
- 当 core 0 更新存储在其 Cache 中的 x 的副本时,它也会通过总线广播该信息
- 如果 core1 正在“监听”总线,它将知道 x 已被更新,它将自己 Cache 中的 x 副本标记为非法的.
基于目录保证 Cache 一致性
使用一种称为目录的数据结构,该目录存储每个 Cache line 的状态,当一个变量被更新时,就会查询目录,并将所有包含该变量的 cache line 置为非法
伪共享
可以理解为,由于缓存一次性会加载 64 个字节,假设 64 个字节中一部分内容为 A,一部分内容为 B,线程 1 在更新 A 时,也会把 B 一起更新掉,另一个线程想获取 B 时,发现 B 失效,就必须从主存中将更新过后的高速缓存行取出来。这样看起来就像是线程 1,2 共享了 B 元素,但其实根本没有。
这样【伪共享】不会带来错误,只不过会带来很多没必要的访存,降低程序性能。
可以通过在线程或者进程中临时存储数据,再把临时存储的数据更新到共享存储来降低伪共享带来的影响
命中与缺失(hit & miss)
指令级并行
通过让多个处理器或功能单元同时执行指令 来提高处理器性能。
- 【流水线】:流水线是指一条指令的执行被切分成多个阶段,交由不同的有独立功能的逻辑部件去依次执行,每条指令只能串行执行,意思就是等第一条指令执行完,第二条指令才能开始执行
- 【多发射】:多发射就是说你有多条流水线,这样你原来可以交给 CPU 一条指令,现在可以同时交给他两条或是三条指令。多发处理器复制计算单元,同时执行程序 中的不同指令.
并行硬件多线程
将单/多指令与单/多数据,进行搭配,2 × 2 可以获得 4 种并行硬件
SISD
Single instruction ,Single Data - 单指令单数据流系统
冯诺依曼就是这个体系,因为一次执行一条指令,一次存取一个数据项
SIMD
Single instruction ,Multiple Data - 单指令多数据流系统
该系统通过对多个数据执行相同的指令,从而实现在多个数据流上操作。
向量加法 - 与该系统很适配,SIMD 适合处理这种大型数组的简单循环并行化处理。
- 缺点
- 所有 ALU 都需要执行相同的指令,或者保持空闲状态
- 在经典设计中,它们还必须同步运行
- ALU 不能进行指令存储.
- 对于大型数据并行问题有效,但对于其它更复杂的并行问题无效。
MISD
Multiple instruction,Single Data - 多指令单数据流系统
MIMD
Multiple instruction,Multiple Data - 多指令多数据流系统
主要有两种类型
共享内存系统
分布式内存系统
共享内存系统
一组自主处理器通过互连网络连接到存储器系统。
每个处理器都可以访问每个内存位置.
处理器通常通过访问共享数据结构进行隐式通信.
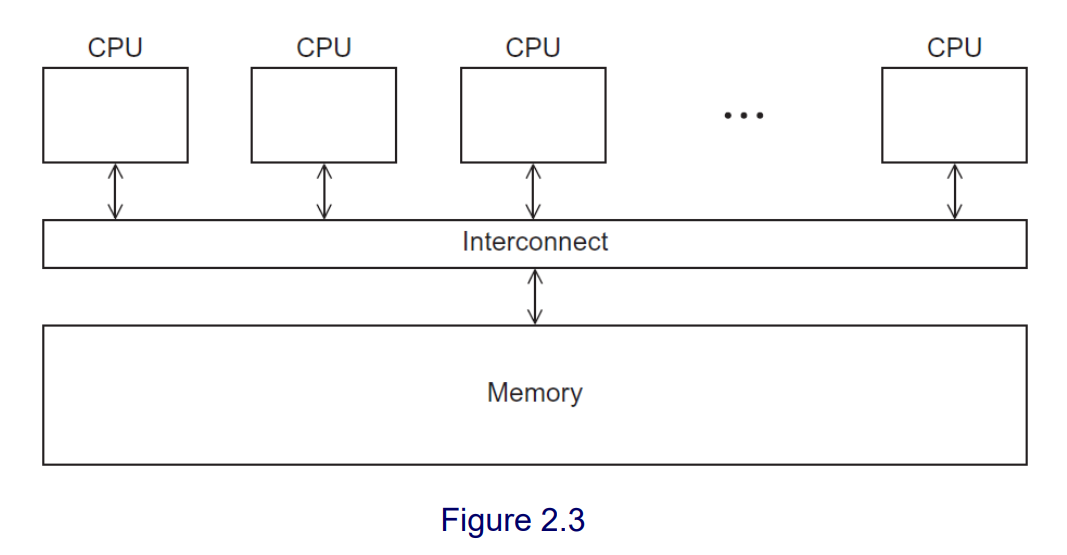
- 【UMA - 一致内存访问】:访问所有内存的时间对于所有的核心都是相同的
- 【NUMA - 非一致内存访问】:与核心直接相连的存储单元访问速度比必须通过另一个芯片访问的存储单元更快.
分布式内存系统
延迟与带宽
传输数据时,我们感兴趣的是数据到达目的地需要多长时间
- 延迟(Latency):从发送源开始发送数据到目的地开始接收第一个字节所经过的时间.
- 带宽(Bandwidth):目的地在开始接收第一个字节后接收数据的速率
消息传输时间 = 1 + n / b, 其中 1 → 延迟, n → 消息总长度(比特),b → 带宽(比特每秒)
性能
并行程序的目的在于:提高性能,那么如何评价一个程序的性能呢?用什么指标呢?
加速比和效率
加速比
如果我们称串行运行时间为 Ta 行,并行运行时间为 Tn 行,那么最佳的预期是:
$$
T并行 = T串行 / p(核数)
$$
此时,我们称并行程序有线性加速比( linear speedup)。
而这基本是不可能的,我们定义并行程序的加速比(speedup):
$$
S = T串行 / T并行
$$
线性加速比 S = p(核数)
效率
$$
E = S/p = (T串行/T并行)/ p = T串行 / p × T并行
$$
阿姆达尔定律 - Amdahl’s law
除非所有的串行程序都能够并行,否则无论可用的核的数量再多,加速将非常有限
线程
使用了多线程,享受其运算速度快带来的便利同时,就需要承担一定的风险:不确定性
什么是不确定性?通俗来讲就是:确定的输入,但是会产生不同的输出,这就是不确定性/非确定性
怎么解决这个问题呢?操作系统,java 中学习了【同步】机制,主要依靠:
- 竞争条件
- 临界区
- 互斥
- 互斥锁
MPI
MPI 编程入门
MPI 编程是用于进行线程通信的,MPI 是个库
MPI 编程的步骤:
1 | // MPI初始化 |
接着调用我们编写的 MPI 函数,执行一定的算法
最后释放资源
1 | // MPI资源释放 |
常用的 MPI-API 接口
int MPI_Send( void *buff, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
–void *buff:你要发送的变量。
–int count:你发送的消息的个数(注意:不是长度,例如你要发送一个 int 整数,这里就填写 1,如要是发送“hello”字符串,这里就填写 6(C 语言中字符串未有一个结束符,需要多一位))。
–MPI_Datatype datatype:你要发送的数据类型,这里需要用 MPI 定义的数据类型,可在网上找到,在此不再罗列。
–int dest:目的地进程号,你要发送给哪个进程,就填写目的进程的进程号。
–int tag:消息标签,接收方需要有相同的消息标签才能接收该消息。
–MPI_Comm comm:通讯域。表示你要向哪个组发送消息。int MPI_Recv( void *buff, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
–void *buff:你接收到的消息要保存到哪个变量里。
–int count:你接收消息的消息的个数(注意:不是长度,例如你要发送一个 int 整数,这里就填写 1,如要是发送“hello”字符串,这里就填写 6(C 语言中字符串未有一个结束符,需要多一位))。它是接收数据长度的上界. 具体接收到的数据长度可通过调用 MPI_Get_count 函数得到。
–MPI_Datatype datatype:你要接收的数据类型,这里需要用 MPI 定义的数据类型,可在网上找到,在此不再罗列。
–int dest:接收端进程号,你要需要哪个进程接收消息就填写接收进程的进程号。
–int tag:消息标签,需要与发送方的 tag 值相同的消息标签才能接收该消息。
–MPI_Comm comm:通讯域。
–MPI_Status *status:消息状态。接收函数返回时,将在这个参数指示的变量中存放实际接收消息的状态信息,包括消息的源进程标识,消息标签,包含的数据项个数等。
入门案例:
1 |
|
开启四线程运行时,1-3 号进程发送消息,0 号进程接收到消息并打印;当笔者开启八线程运行时,1-7 号进程发送消息,0 号进程接收到消息并打印。
集合通信(collective communication)
Pthreads
常用的 Pthreads - API 接口
蒙特卡洛采样
MPI 实现
1 | //#include<stdio.h> |
Pthreads - 实现
1 |
|
openMP - 实现
树形结构进行加法
1 |
|
并行计算程序设计 - CUDA
引入 - 概念阐述
GPU 与 CPU
可移植性与可扩展性
数据并行与任务并行
GPU 拆解
GPU Memory 结构
- 【软件层面】
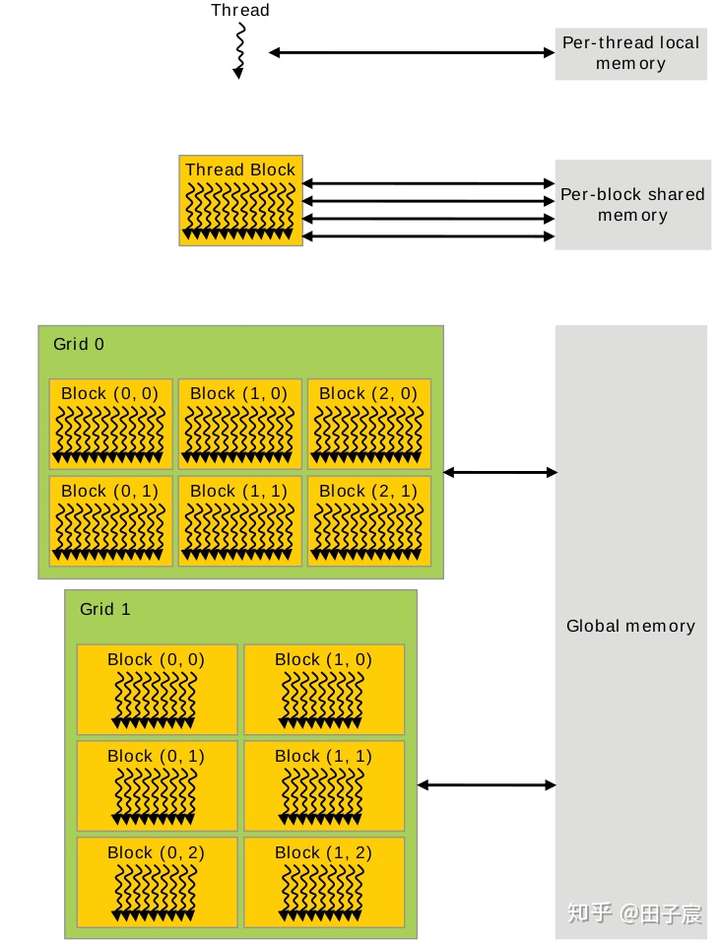
- 寄存器和本地内存绑定到了每个线程,其他线程无法访问。
- 同一个线程块内的线程,可以访问同一块共享内存。注意,即使两个线程块被调度到了同一个 SM 上,他们的共享内存也是隔离开的,不能互相访问。
- 网格中的所有线程都可以自由读写全局内存。
- 常量内存和纹理内存只能被 CPU 端修改,GPU 内的线程只能读取数据。
Cuda Execution Model 执行模型
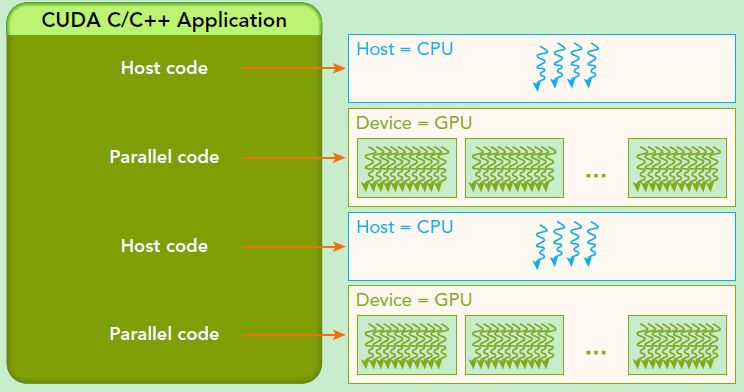
GPU 架构是围绕一个流式多处理器(SM)的可扩展阵列搭建的。从软件上看,SM 更像一个独立的 CPU core。SM(Streaming Multiprocessors)是 GPU 架构中非常重要的部分,GPU 硬件的并行性就是由 SM 决定的。
以 Fermi 架构为例,其包含以下主要组成部分:
- CUDA 核心
- 共享缓存/L1 Cache
- 寄存器文件
- 加载/存储单元
- 特殊功能单元(SFU)
- 线程束调度器。
SM
GPU 中每个 SM 都能支持数百个线程并发执行,每个 GPU 通常有多个 SM,当一个核函数的网格被启动的时候,多个 block 会被同时分配给可用的 SM 上执行。
注意: 当一个 blcok 被分配给一个 SM 后,他就只能在这个 SM 上执行了,不可能重新分配到其他 SM 上了,多个线程块可以被分配到同一个 SM 上。
在 SM 上同一个块内的多个线程进行线程级别并行,而同一线程内,指令利用指令级并行将单个线程处理成流水线。
Warp - 线程束
CUDA 采用单指令多线程(single-instruction-multiple-threads, SIMT)架构来管理和执行线程,每 32 个线程为一组,被称为线程束(warp)。线程束中的所有线程同时执行相同的指令。每个线程都有自己的指令地址计数器和寄存器状态,利用自身的数据执行当前的指令。每个 SM 都将分配给它的线程块划分到包含 32 个线程的线程束中,然后在可用的硬件资源上调度执行。warp 内遵循lockstep规则,即所有线程同步执行。
在 SM 里,warp 是基本的调度、执行和读写 cache/memory 的单元
一个线程块(block)只能在一个 SM 上被调度。一旦线程块在一个 SM 上被调度,就会保存在该 SM 上直到执行完成。在同一时间,一个 SM 可以容纳多个线程块。
当线程束(warp)由于任何理由闲置的时候(如等待从设备内存中读取数值),SM 可以从同一 SM 上的常驻线程块中调度其他可用的线程束。在并发的线程束间切换并没有开销,因为硬件资源已经被分配到了 SM 上的所有线程和块中,所以最新被调度的线程束的状态已经存储在 SM 上。
- 个人理解
GPU 中有多个 SM,SM 是 GPU 程序的基本调度单位,而程序在执行的时候,将 M 个 Block 作为一组分配给一个 SM,其中一个 Block 除了包含共享内存,寄存器等其他部件,还有 N 个线程,当一个 SM 被调度使用时,本质上是将 32 个线程作为一个线程束 Warp 去执行程序,这个 Warp 就作为 SM 中的基本调度单位。
Thread 分配问题
以 Fermi GPU 来说明:每个 SM 能接受 8 个 Blocks
每个 SM 最多分配 1536 个 threads,如何设置 block dimension
1: 8×8 : 1block = 8*8 = 64 threads,
1536/64 = 24 blocks,
24/8 =3, SM 最多有 8 个 blocks,需要 3 个 SM, 8*64 = 512. 所以一个 SM 执行 512 个 threads
2” 16×16: 1block = 16*16 = 256 threads,
1536/256 = 6 blocks,
SM 最多有 8 个 blocks, 6*256 = 1536. 所以一个 SM 执行 1536 个 threads。 完全利用到了 SM
3: 32×32: 1block = 32*32 = 1024 threads,
1536/1024 = 1 blocks,
1*1024 = 1024. 所以一个 SM 执行 1024 个 threads, 只利用到了 2/3 的 SM。
映射问题 - 线程全局 ID 的计算
被除数 = 除数 * 商 + 余数
类比获得:
线程 Id = blockId * blockSize + threadId
- blockId :当前 block 在 grid 中的坐标(可能是 1 维到 3 维)
- blockSize :block 的大小,描述其中含有多少个 thread
- threadId :当前 thread 在 block 中的坐标(同样从 1 维到 3 维)
因此,要求解一个线程的全局 ID,其本质就是求解上述三个参数,最后按照公式,组装在一起就好
- 个人理解
可以脑补一个立方体:
一般来说坐标(x, y, z)分别所在的维度大小是(Dx, Dy, Dz),一般会把 z 看成高纬度,接着是 y ,最后是 x。
高维度坐标转一维坐标公式 id = Dx * Dy * z + Dx * y + x
例子
1D grid, 1D block
- blockSize = blockDim.x
- blockId = blockIdx.x
- threadId = threadIdx.x
Id = blockIdx.x * blockDim.x + threadIdx.x
3D grid, 1D block
blockSize = blockDim.x(一维 block 的大小)
blockId = Dx _ Dy _ z + Dx * y + x (三维 grid 中 block 的 id,用公式)
= gridDim.x _ gridDim.y _ blockIdx.z + gridDim.x * blockIdx.y + blockIdx.x
threadId = threadIdx.x (一维 block 中 thread 的 id)
Id = (gridDim.x _ gridDim.y _ blockIdx.z + gridDim.x _ blockIdx.y + blockIdx.x ) _ blockDim.x + threadIdx.x
1D grid, 2D block
blockSize = blockDim.x * blockDim.y(二维 block 的大小)
blockId = blockIdx.x(一维 grid 中 block id)
threadId = Dx * y + x (二维 block 中 thread 的 id)
= blockDim.x * threadIdx.y + threadIdx.x
Id = blockIdx.x _ (blockDim.x _ blockDim.y) + blockDim.x * threadIdx.y + threadIdx.x
3D grid, 3D block
blockSize = blockDim.x _ blockDim.y _ blockDim.z(三维 block 的大小)
blockId = Dx _ Dy _ z + Dx * y + x(三维 grid 中 block 的 id,用公式)
= gridDim.x _ gridDim.y _ blockIdx.z + gridDim.x * blockIdx.y + blockIdx.x
threadId = Dx _ Dy _ z + Dx * y + x(三维 block 中 thread 的 id,用公式)
= blockDim.x _ blockDim.y _ threadIdx. z + blockDim.x * threadIdx.y + threadIdx.x
Id = (gridDim.x _ gridDim.y _ blockIdx.z + gridDim.x _ blockIdx.y + blockIdx.x) _ (blockDim.x _ blockDim.y _ blockDim.z) + blockDim.x _ blockDim.y _ threadIdx. z + blockDim.x * threadIdx.y + threadIdx.x
索引例题
- 普通索引问题
We need to use each thread to calculate one output element of a vector addition. Assume that variable i should be the index for the element to be processed by a thread. What would be the expression for mapping the thread/block indices to data index?
- (A)i=threadIdx.x + threadIdx.y;
- (B)i=blockIdx.x + threadIdx.x;
- (C)i=blockIdx.x*blockDim.x + threadIdx.x;
- (D)i=blockIdx.x * threadIdx.x;
答案选:C
- 相邻、
我们希望使用每个线程来计算向量加法的两个(相邻)输出元素。 假设变量 i 应该是线程要处理的第一个元素的索引。 将线程/块索引映射到第一个元素的数据索引的表达式是什么?
- (A)i=blockIdx.x * blockDim.x + threadIdx.x +2;
- (B)i=blockIdx.x _ threadIdx.x _ 2
- (C)i=(blockIdx.x _ blockDim.x + threadIdx.x) _ 2
- (D)i=blockIdx.x _ blockDim.x _ 2 + threadIdx.x
答案:C
说明:每个线程都包含 2 个连续的元素。 起始数据索引只是全局线程索引的两倍。 另一种看待它的方式是所有先前的块都覆盖 (blockIdx.xblockDim.x)*2。 在块内,每个线程覆盖 2 个元素,因此线程的开始位置是 2\ threadIdx.x。 超出所有先前块所涵盖的范围。
我们希望使用每个线程来计算向量加法的两个输出元素。 每个
线程块处理形成两个部分的 2 _ blockDim.x 连续元素。 全部
每个块中的线程将首先处理一个部分,每个处理一个元素。 他们会
然后全部移动到下一部分,每个处理一个元素。 假设变量 i
应该是线程要处理的第一个元素的索引。 会是什么
用于将线程/块索引映射到第一个元素的数据索引的表达式?
(A) i=blockIdx.x _ blockDim.x + threadIdx.x +2;
(B) i=blockIdx.x * threadIdx.x*2
(C) i=(blockIdx.x _ blockDim.x + threadIdx.x) _ 2
(D) i=blockIdx.x _ blockDim.x _ 2 + threadIdx.x
答案:D
说明:之前的所有块都覆盖 (blockIdx.x _ blockDim.x) _ 2。 在这种情况下,开始元素是连续的,因此只需向其中添加 threadIdx.x。
CUDA - 函数相关
前缀
- ** global :表示一个内核函数,是一组由 GPU 执行的并行计算任务,以 foo<<>>(a)的形式或者 driver API 的形式调用。目前global**函数必须由 CPU 调用,并将并行计算任务发射到 GPU 的任务调用单元。随着 GPU 可编程能力的进一步提高,未来可能可以由 GPU 调用。
- ** device : 表示一个由 GPU 中一个线程调用的函数。由于 Tesla 架构的 GPU 允许线程调用函数,因此实际上是将device** 函数以__inline 形式展开后直接编译到二进制代码中实现的,并不是真正的函数。
- ** host ** : 是由 CPU 调用,由 CPU 执行的函数
Dim Grid,Dim Block 写法
例题引入:
我们将在 Lecture 幻灯片中使用 PictureKernel 处理 800X600(x 或水平方向 800 像素,它们或垂直方向 600 像素)的图片:
1 | __global__ void PictureKernel(float* d_Pin, float* d_Pout, int n, int m) { |
假设我们决定使用 16X16 块的网格(grid)。
也就是说,每个块 Block 都被组织成一个 2D 16X16 的线程阵列。 以下哪个语句正确设置了内核配置?
假设 int 变量 n 的值为 800,int 变量 m 的值为 600。内核使用语句 PictureKernel<<<DimGrid,DimBlock>>>(d_Pin, d_Pout, n, m); 启动。
(A)dim3 DimGrid(ceil(n/16.0), ceil(m/16.0), 1); dim3 DimBlock(16, 16, 1);
(B)dim3 DimGrid(1, ceil(n/16.0), ceil(m/16.0); dim3 DimBlock(1, 16, 16);
(C)dim3 dimGrid(ceil(m/16.0), ceil(n/16.0), 1); dim3 DimBlock(16,16,1);
(D)dim3 DimGrid(1, ceil(m/16.0), ceil(n/16.0); dim3 DimBlock(1, 16, 16);
答案选 A:
说明:dim3 格式为 (x, y, z)。 由于 n 是图片在 x 方向的尺寸,m 是 y 方向的尺寸,所以我们应该用 n 来设置 x 维度,m 来设置 y 维度。
n/16.0 得到 该有多少列 block,m/16.0 得到该有多少行 block;
16 16 1 → 一个 block 中为 16 行 16 列的线程阵
Control Divergence/控制发散问题
处理一个 600*800 的图片(800 是水平方向,600 是垂直方向),使用 kernel 函数 PictureKernel().m=600, n=800.
1 | __global__ void PictureKernel(float* d_Pin, float* d_Pout, int n, int m){ |
- 假设 grid 是 16 × 16 blocks.block 是 16×16 threads. 问在 kernel 中有多少个 warps 会执行.
A) 37 × 16. B) 38 ×50. C)38 × 8 ×50. D)38×50 × 2
解答: ceil(800/16.0) = 50, ceil(600/16.0)=38. 每个 block 是(16 * 16)/32= 8 warps.所以答案是: 38 ×8 ×50
- 在第一个问题里面,有多少个 warps 有 control divergence?
(A) 37 + 50 ×8
(B) 38×16
(C) 50
(D) 0
解答: 在一个 warp 中同时有线程走 if 和 else,称之为warp control divergence.
X 方向是 800 = 50 _ 16, Y方向是 600 = 16 _ 37.5.warp=32, 每两行是一个 warp.X 轴方向没有 control divergence.Y 方向最后一个 block 是 0.5 ×16 ×16 = 128, 128/32= 4, 全部落在 if 里面.所以结果是0.选 D
- 把第一题改成 800*600(600 是 x 方向,800 是 y 方向),有多少个 warps 存在 control divergence?
(A) 37+50 ×8
(B) 38 ×16
(C) 50 × 8
(D) 0
解答: x = 600/16=37.5. x 方向需要补齐 0.5*16=8, y=800/16=50.所以每一行右边都会补齐 0.5 个 block_zize,即 8 列.所以在两行的最右边是一个 block,一个 block 里面每两行是一个 warp,而这个 warp 就存在一半在 if,一半在 els,存在 control divergence, 既然每两行的最后一个 warp 存在 control divergence,那么一共就是 800/2 =400
也可以这么算:因为最右边是一直存在 congtol divergence 的.y 方向是 50 个 block,每个 block 有个 warp,50*8 = 400, 所以选C
- 如果把图片改成是 799*600(600 是 x 方向,799 是 y 方向),有多少个 warps 存在 control divergence?
(A) 37+50 × 8
(B) (37+50) ×8
(C) 50×8
(D) 0
解答: Y 方向补齐 1 行,X 方向补齐结合第三题我们可以算出y 方向一共是有 50 × 8,当然有一个重合的情况我们后面在减去.
现在看 X 方向,一共是 799 行,每2行才能组成一个 warp,而且最后补齐的 800 行处在条件 else,799 行处在条件 if 里面,这最后两行的 warp 是存在 control divergence.一共是有 608/16=38. X 和 Y 方向重合一个,所以结果是 50 × 8+38-1 = 37 + 50 × 8, 选 A
- If we launch the kernel with a block size of 16X16 on a 1000X1000 matrix, how many warps will have control divergence?
(A) 1000
(B) 500
(C) 1008
(D) 508
答案 B500,1000/16 = 62.5,向上取整=63,那么每一行中,x 维度上,就有 8 个线程是无效的。又由于 32 个线程组成一个 Warp,32 / 16 = 2,即每 2 行组成一个 Warp。1000 / 2 = 500 个 warps 会存在 control divergence 问题。
矩阵相乘相关
Tiling 技术
https://zhuanlan.zhihu.com/p/342103911 Tiling 技术文章
CUDA - 代码实现
C(i,j) = sum { A(i,k) * B(k,j) } 0<=k < _wa;耦合程度很小,所以我们可以通过划分区域的方法,让每个线程负责一个区域。
怎么划分呢?首先最初的想法是让每一个线程计算一个 C(i,j),那么估算一下,应该需要 height_cwidthc,也就是 hawb 个线程。进一步,我们将矩阵按一个大方格 Block 划分,如果一个方格 Block 大小是 16 * 16,那么矩阵 80 * 48 的可以表示为 5(16) * 3(16),即 5 * 3 个大格子(Grid),所以 grid 的划分自然就是(heightc/16) *(width_c/16)个线程了。
好了,划分完后,内核代码如下
1 | __global__ void matrix_kernel_0(float* _C,const float* _A,const float *_B,int _wa,int _wb) |
共享存储特点与 bank 冲突
https://blog.csdn.net/Bruce_0712/article/details/65447608 Shared Memory & Bank Conflict
共享存储
因为 shared mempory 是片上的(Cache 级别),所以比局部内存(local memory)和全局内存(global memory)快很多,实际上,shared memory 的延迟要比没有缓存的全局内存延迟小 100 倍(如果线程之间没有 bank conflicts 的话)。在同一个 block 的线程共享一块 shared memory。线程可以访问同一个 block 内的其他线程让 shared memory 从全局内存加载的数据。这个功能(结合线程同步,thread synchronization)有很多作用,比如实现用户管理的数据 cache,高性能的并行协作算法(比如并行规约,parallel reduction)等。
bank
bank 是一种划分方式。在 cpu 中,访存是访问某个地址,获得地址上的数据,但是在这里,是一次性访问 banks 数量的地址,获得这些地址上的所有数据,并逻辑映射到不同的 bank 上。类似内存读取的控制
bank conflict
为了实现内存高带宽的同时访问,shared memory 被划分成了可以同时访问的等大小内存块(banks)。因此,内存读写 n 个地址的行为则可以以 b 个独立的 bank 同时操作的方式进行,这样有效带宽就提高到了一个 bank 的 b 倍。
然而,如果多个线程请求的内存地址被映射到了同一个 bank 上,就会发生【bank conflict】,这些请求就变成了串行的(serialized)。
硬件将把这些请求分成 x 个没有冲突的请求序列,带宽就降成了原来的 x 分之一。但是如果一个 warp 内的所有线程都访问同一个内存地址的话,会产生一次广播(boardcast),这些请求会一次完成。
- 总结
简单的说,矩阵中的数据是按照 bank 存储的,第 i 个数据存储在第 i 个 bank 中。一个 block 要访问 shared memory,只要能够保证以其中相邻的 16 个线程一组访问 thread,每个线程与 bank 是一一对应就不会产生 bank conflict。否则会产生 bankconflict,访存时间成倍增加,增加的倍数由一个 bank 最多被多少个 thread 同时访问决定。有一种极端情况,就是所有的 16 个 thread 同时访问同一 bank 时反而只需要一个访问周期,此时产生了一次广播。
DRAM burst & 合并内存访问
DRAM - 全局存储带宽
为了降低访问的次数,当处理器访问一段数据时,实际上传递给处理器的是围绕这一段数据的一个更大的数据.这个就是 dram burst 设计
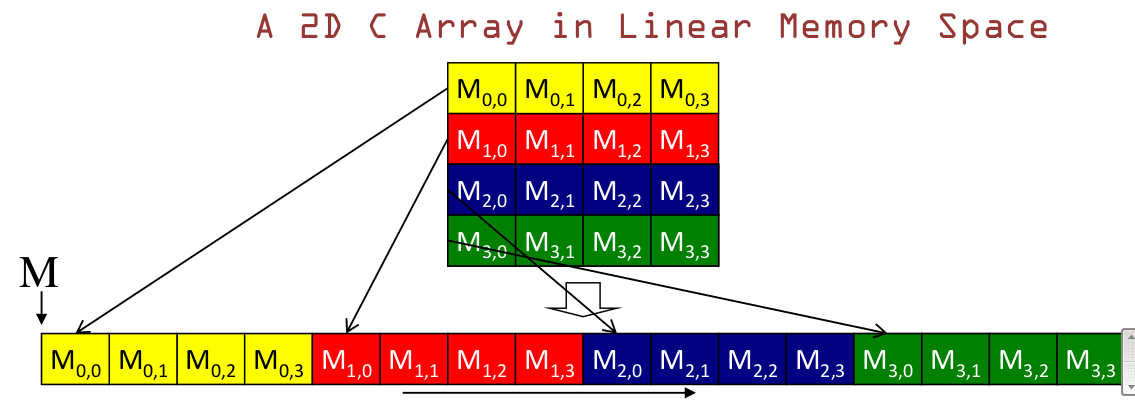
合并内存访问
首先需要明白:GPU 存储是【row - major】形式存储,是以行来组织数据的,如下图所示
对于 GPU 来说,由于 thread 是异步执行的.下面这两种访问模式一种是合并访问的,利用到 DRAM。另一种就是非合并访问。
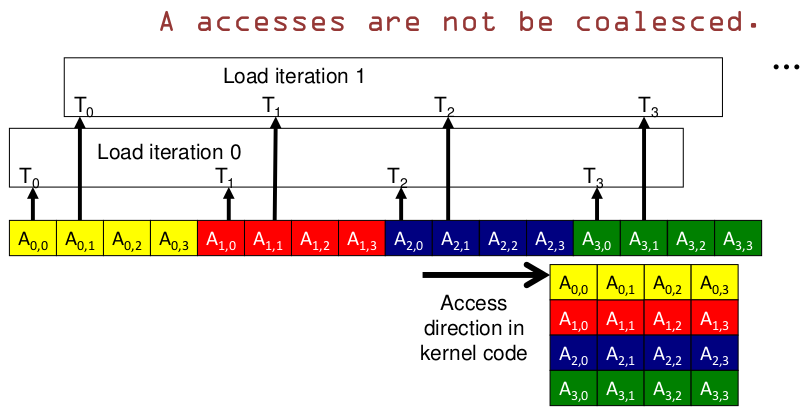
下图中,A 是横向的访问方向,是非合并访问,B 是纵向的访问方式,是合并访问
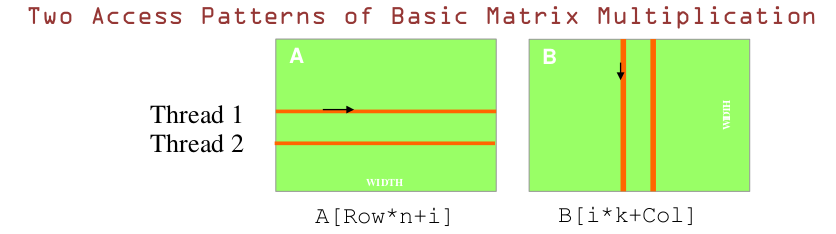
详细来看:
- A
- B
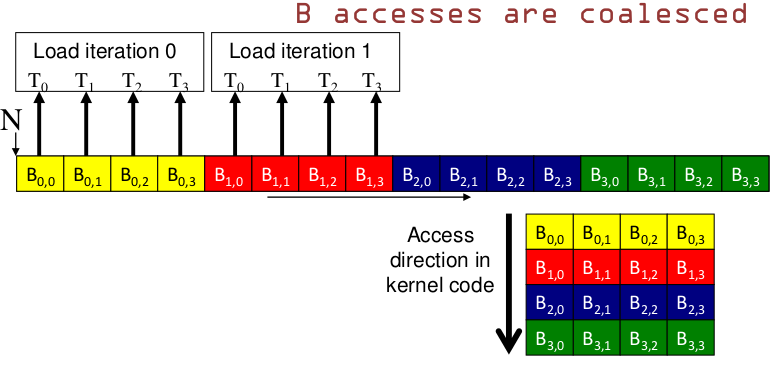
即:GPU 纵向访问内存可以实现合并访问的效果.
CUDA - 例题
- 函数问题 - cudaMemcpy
如果我们想从主机数组(host array )h_A 复制 3000 字节的数据(h_A 是指向元素 0 的指针)
源数组)到设备数组(device array ) d_A(d_A 是指向目标数组元素 0 的指针),
在 CUDA 中,什么是合适的 API 调用?
(A) cudaMemcpy(3000, h_A, d_A, cudaMemcpyHostToDevice);
(B) cudaMemcpy(h_A, d_A, 3000, cudaMemcpyDeviceTHost);
(C) cudaMemcpy(d_A, h_A, 3000, cudaMemcpyHostToDevice);
(D) cudaMemcpy(3000, d_A, h_A, cudaMemcpyHostToDevice);
答案:C




