索引篇
说说 Mysql 索引类型?
可以从以下几个角度去回答:
- 数据结构角度
- 物理存储角度
- 逻辑角度
- 数据结构角度
- B+树索引
- Hash 索引:底层数据结构是哈希表,绝大部分需求为单条记录的查询(select xx … id = yy),这种查询可以使用哈希索引
- 空间数据索引(R - Tree)
- 全文索引(FULLTEXT)
- 物理存储角度
- 聚集索引(clustered index)
- 非聚集索引(non-clustered index)
- 逻辑角度
- 主键索引:主键索引是一种特殊的唯一索引,不允许有空值
- 普通索引或者单列索引
- 多列索引(复合/联合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
- 唯一索引或者非唯一索引
- 空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL 中的空间数据类型有 4 种,分别是 GEOMETRY、POINT、LINESTRING、POLYGON。
索引的优点有哪些?
索引可以快速定位到表的指定位置
- 索引大大减少了服务器需要扫描的数据量。
- 索引可以帮助服务器避免排序和临时表。
- 索引可以将随机 I/O 变为顺序 I/O 。
B 树和 B+树区别?
- 首先回答平衡二叉树:假如一个二叉搜索树比较极端,变成链表了,那性能就会变得很差了,因此需要旋转编程平衡二叉树
- 接着回答 B-树:因为数据库中大部分数据都存在于磁盘,但是 IO 一次磁盘的代价相对来说比较大,我们需要尽可能的减少 AVL 树的深度,即增加每个节点的数据量。每一个节点称为页,也就是一个磁盘块。 B 树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,同时所有节点的关键字按照递增顺序排列,所有的叶子结点都在同一层。
- 最后回答 B+树:B+树是由 B-树变形而来,主要不同之处在于:其非叶子节点上是不存储数据的,数据全在叶子节点存储,由于这个特性,导致数据都存储在了叶子结点,且按照顺序排列,使得 B+树的范围查找,排序查找,分组查找,去重查找变得简单了。而 B 树因为数据分散在各个节点,要实现这一点是很不容易的
InnoDB 为什么要使用 B+树作为索引而不用 B 树呢
B+树更适合外部存储。由于内结点不存放真正的数据(只是存放其子树的最大或最小的关键字,作为索引),一个结点可以存储更多的关键字,每个结点能索引的范围更大更精确,也意味着 B+树单次磁盘 IO 的信息量大于 B 树,I/O 的次数相对减少。
MySQL 是一种关系型数据库,区间访问是常见的一种情况,B+树叶结点增加的链指针,加强了区间访问性,可使用在区间查询的场景;而使用 B 树则无法进行区间查找。
应该怎么建立合适的索引?或者说什么时候适合用索引 什么时候不适合用索引呢?
- 适合用索引情况:
- 在经常查询、排序、分组的列使用索引
- 数据分布相对均匀、连续的字段,适合使用索引
- 查询操作较多的表上,适合创建索引
- 不适合用索引情况:
- 如果表的数据量很少,不建议使用索引
- 经常更新(新增数据)的表不宜使用过多索引
- 避免在取值范围很少的列上使用索引(例如性别,账户状态)
- 二进制字段不适合建索引
- 适合用索引情况:
Mysql 索引最左倾原则 - 哪种组合会用上索引呢?
例子:下面有【a b c】分别为三个字段,我们将这三个字段建立成了一个联合索引。要使用这个索引,sql 必须提供 a 字段。
1
INDEX(a, b, c)
查询方式 能否用上索引 ---------------------------------------------------+---------------------------- select * from users where a=1 and b=2 能用上a、b select * from users where b=2 and a=1 能用上a、b(有MySQL查询优化器) select * from users where a=2 and c=1 select * from users where b=2 and c=1 一个索引都没用上 <!--code1-->此时我们进行一次查询(查询时间超过 1s)
1
2
3
4
5
6
7mysql> select * from emp where empno=413345;
+--------+--------+----------+-----+------------+---------+--------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+----------+-----+------------+---------+--------+--------+
| 413345 | vvOHUB | SALESMAN | 1 | 2014-10-26 | 2000.00 | 400.00 | 11 |
+--------+--------+----------+-----+------------+---------+--------+--------+
1 row in set (6.55 sec)查看 mysql 安装目录下的 data 目录,有一个文件mysql_slow.log
1
2
3
4
5
6
7
8
9/usr/local/mysql/bin/mysqld, Version: 5.1.73-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /tmp/mysql.sock
Time Id Command Argument
# Time: 141026 23:24:08
# User@Host: root[root] @ localhost []
# Query_time: 6.547536 Lock_time: 0.002936 Rows_sent: 1 Rows_examined: 10000000
use temp;
SET timestamp=1414337048;
select * from emp where empno=413345;慢查询语句就查询出来了。
如何进行慢查询优化?
- 检查一下有没有用索引,没有的话就用上
- 如果用了索引,判断是不是最优的索引
- 如果上述都解决了,检查下查询字段是不是都是必须的,有没有查询多余字段
- 接着检查表数据会不会太多了,是不是应该进行分表
- 最后检查数据库实例所在的性能环境配置,CPU、磁盘等会不会出问题了。
Redis 篇
Redis 的基本数据类型有哪些?分别都是怎么实现的?
String,List,Hash,Set,Zset/Sorted Set
String:
- string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如 jpg 图片或者序列化的对象 。同时也是 Redis 最基本的数据类型
- 底层依靠的是动态字符串 String
List:
- 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),
- 底层依靠双向链表
Hash:
- hash 是一个键值(key=>value)对集合,是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
- 底层依靠 HashTable 或是 ZipList,其中 Value 为一个 HashMap,当 Hash 成员比较少的时候,Value 实际上为一个一维数组,底层实现是ZipLIst 压缩列表,当成员数量增多了,转换为 HashTable
Set:
- Redis 的 Set 是 string 类型的无序集合。集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
- 底层实现是依靠 HashMap(Key 为对象名,value 为 null) + IntSet,元素不多的时候为 IntSet,元素多的时候转为 HashMap(Redis 使用的是字典,但其实本质就是 HashMap)
Zset:
- Redis zset 和 set 一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。zset 的成员是唯一的,但分数(score)却可以重复。
- 底层使用了 HashMap 和 SkipList 去保证数据的存储和有序
- HashMap:存放成员到 Score 的映射
- SkipList:存放所有成员
排序:靠的是 HashMap 中的 score,如果想要查找数据,由于跳跃表的数据结构特性,查询效率比较高;
Redis 的基本数据结构有哪些?简单介绍一下吧?
- 简单动态字符串 String:
- 列表 List:
- 字典 Hash:
- 跳跃表 SkipList
- 整数集合 Set:
- 压缩列表 ZipList
Zset/Sorted Set 是怎么实现的?
- Zset 其内部是通过 HashMap 和 SkipList 跳表进行实现的,其中前者存放成员到 Score 的映射(Zset 根据 Score 进行排序),而 SkipList 用于存放所有成员。
你上面说到跳表 SkipList,那么跳表是怎么实现的呢?
- 通过在链表增加了多个索引实现,什么意思呢?原来的链表只能指向后面一个节点,而跳表中每个节点可以去持有多个指向其他节点的指针,这样做可以衍生出多条路径,可以做到快速的访问某个节点。
Redis 的分布式事务有没有了解?
Redis 缓存淘汰策略是什么?
| 策略 | 描述 |
|---|---|
| volatile-lru | 从已设置过期时间的数据集中挑选最近最少使用的数据淘汰 |
| volatile-ttl | 从已设置过期时间的数据集中挑选将要过期的数据淘汰 |
| volatile-random | 从已设置过期时间的数据集中任意选择数据淘汰 |
| allkeys-lru | 从所有数据集中挑选最近最少使用的数据淘汰 |
| allkeys-random | 从所有数据集中任意选择数据进行淘汰 |
| noeviction | 禁止驱逐数据 |
redis 的持久化策略是什么?
Redis 的缓存穿透是什么?怎么解决?
- 缓存穿透:即黑客故意去请求缓存中不存在的数据,导致所有的请求都怼到数据库上,从而数据库连接异常。
- 解决方案
- 利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试
- 采用异步更新策略,无论 key 是否取到值,都直接返回。value 值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
- 提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的 key。迅速判断出,请求所携带的 Key 是否合法有效。如果不合法,则直接返回。
Redis 的缓存雪崩是什么?怎么解决?
- 缓存雪崩:即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
- 解决方案
- 给缓存的失效时间,加上一个随机值,避免集体失效。
- 使用互斥锁,但是该方案吞吐量明显下降了。
- 双缓存。我们有两个缓存,缓存 A 和缓存 B。缓存 A 的失效时间为 20 分钟,缓存 B 不设失效时间。自己做缓存预热操作。然后细分以下几个小点
- 从缓存 A 读数据库,有则直接返回
- A 没有数据,直接从 B 读数据,直接返回,并且异步启动一个更新线程。
- 更新线程同时更新缓存 A 和缓存 B。
Redis 的 AOF 和 RDB 有什么区别?
为了能够重用 Redis 数据,或者防止系统故障,我们需要将 Redis 中的数据写入到磁盘空间中,即持久化。
Redis 提供了两种不同的持久化方法可以将数据存储在磁盘中,一种叫快照 RDB,另一种叫只追加文件 AOF。
RDB:Redis Database Backup file,可以手动执行也可以根据配置定期执行,它的作用是将某个时间点上的数据库状态保存到 RDB 文件中,RDB 文件是一个压缩的二进制文件,通过它可以还原某个时刻数据库的状态。由于 RDB 文件是保存在硬盘上的,所以即使 redis 崩溃或者退出,只要 RDB 文件存在,就可以用它来恢复还原数据库的状态。
它恢复时是将快照文件直接读到内存里。
AOF:Append Only File,通过保存 redis 服务器所执行的写命令来记录数据库状态的。
在服务器启动时,通过重新执行这些命令来还原数据集。
参考来源:https://blog.csdn.net/ll594317566/article/details/109215575
Redis 的 rdb 写入底层逻辑是怎样的?
布隆过滤器说一下原理,为什么效率高?
- 布隆过滤器的基本原理是依靠【位图 bitmap】,它含有许多个 bit 位,当有一个数据需要存储时,会经由多个 Hash 函数算出多个 Hash 值将位图上对应的 bit 位赋值为 1(一开始默认为 0)。当我们要查询一个元素(key)在不在位图中,则回通过 Hsah 函数算出对应 Hash 值,去判断 Hash 值对应的位置上的 bit 是不是为 1,只要有一个值不为 1,就能说明该数据不在 bit 图中;而如果都为 1,也只能说明该数据【可能】在 bit 图中(因为可能是别的 key 将这几个位置赋为 1)
- 增加和查询元素的时间复杂度为$O(n)$,n 为 Hash 函数的个数,与数据量大小无关,因此效率高
Mysql 操作篇
- Mysql 主从复制是如何复制的?/ mysql 的主从同步原理?

说明一下 SQL 语句执行过程
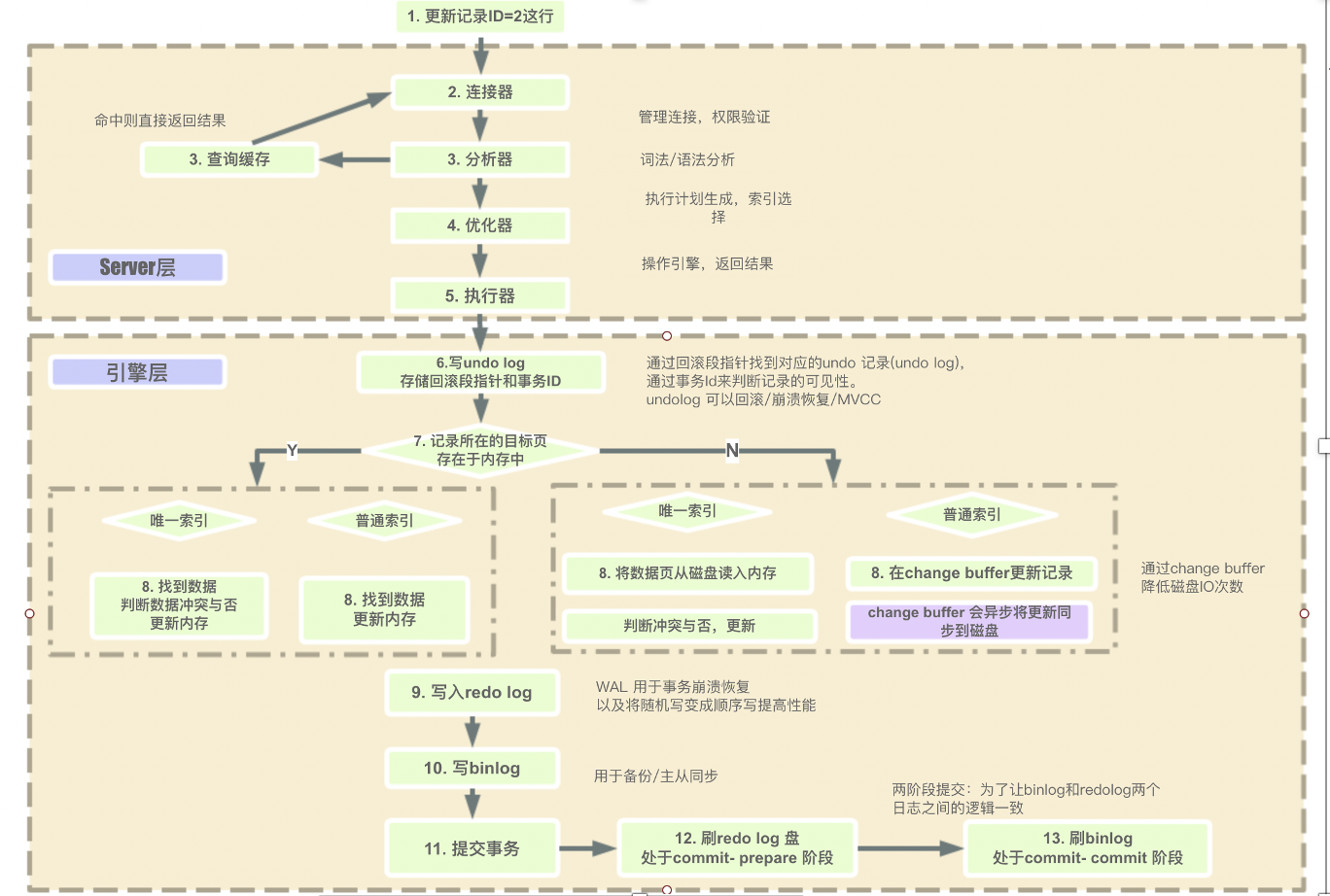
(1)首先客户端连接 Mysql,发布查询,
(2)在缓存中找结果集,如果有则直接返回;
(3)如果没有,Mysql 通过分析器解析查询
(4)通过优化器生成了执行计划,选择索引
(5)运行执行计划从引擎中获取数据,在引擎中具体运行过程如下:
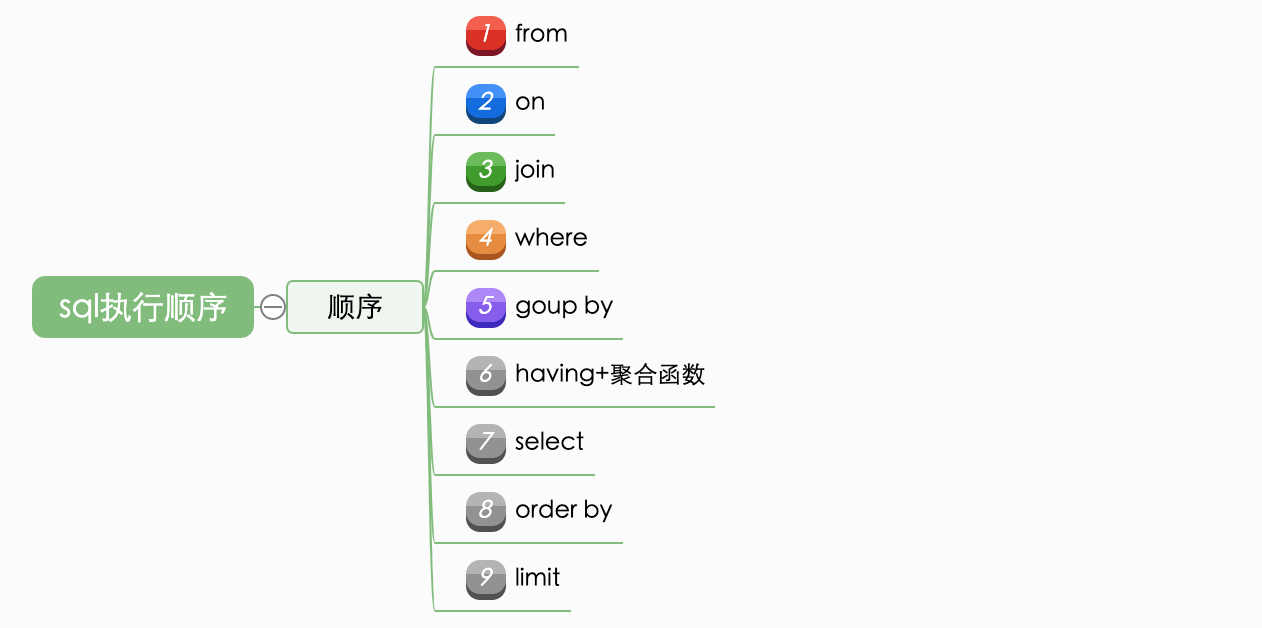
首先执行
from子句,选出数据库中查找哪张表接着执行
join on,join表示要关联的哪张表,on则是连接的条件通过前两部,就可以锁定执行的数据库表,就可以产生笛卡尔积,产生一个合成的临时表
再执行
where,根据这个关键字后跟着的条件进行筛选过滤跟着执行
group by,对上面产生的表进行固定字段的分组,该过程将数据的顺序进行整理,而不会对数据总量产生影响执行
having + 聚合函数,进行进一步的数据筛选执行开头的
select,对分组聚合完后的数据进行挑选,得出需要查询的数据如果有
dinstinct,则进行数据的去重执行
order by,进行数据的顺序/逆序排列limit,进行表的分页
总结:
首先找出要在哪个表进行操作,然后用 where 进行条件筛选;
然后是表的“美化”,进行分组整理。
由于 having 的搜索条件要在分组后应用,因此再进行 having 条件的进一步筛选得到个更精确的表。
既然该找的数据都找出来了,就执行 select 语句进行结果显示。
但结果也有可能有重复的,于是进行去重。
虽然结果是分组了的,但是可能没有按顺序排列,于是进行数据的顺序/逆序排列。
最后是怕数据太多看不过来,或者数据太少不够看,进行表的分页。
写 SQL 篇
- 给一张表,有 id,name 两个列,查第二大的 id 的列,写 sql 语句




