1、基本概念
1.1、web 开发
什么是 web?web 就是网页 比如百度
静态资源和动态资源区别:
静态资源/静态 web:
- html,css
- 所有人看到的东西都一样
动态资源/动态 web:
servlet、jsp、ASP
看到的东西有可能是不一样的
1.2、web 应用程序
web 应用程序是什么?是我们用可以用浏览器所访问的程序 不同于之前的用编译器然后控制台运行的程序
- 网页:xxx.html 类似于此类后缀文件
- web 应用程序的组成部分:
- html,css,js(静态资源)
- jsp,servlet(动态资源)
- jar 包
- 配置文件 properties
- java 程序
web 程序写完后,外界想访问 需要一个服务器进行管理
1.3、静态 web(服务器)
- 后缀为:.html 此类的 只要一直保存在服务器端 那就能直接被读取
- 此处的 webserver 为:apache/iis 等
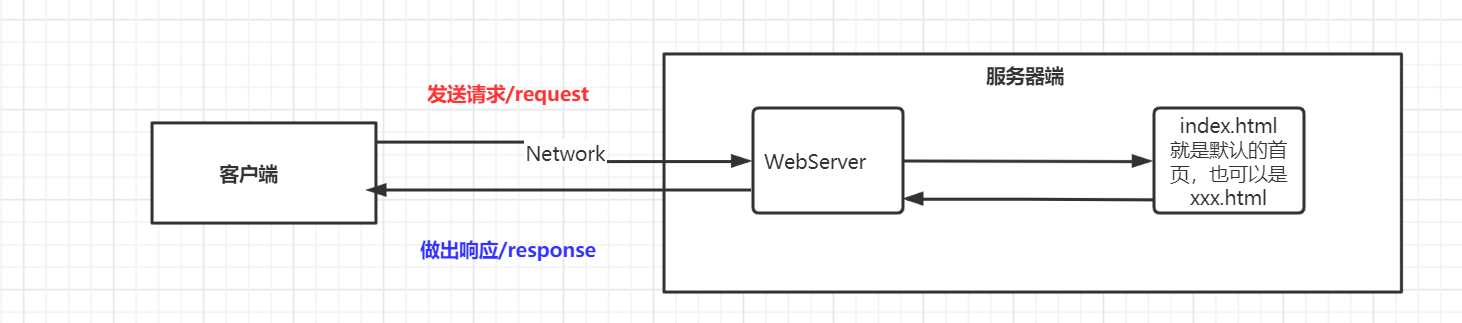
- 客户端通过发送请求到服务器端,其中 webservice 访问 xxx.html 得到数据,通过 web service 这个服务再做出响应给客户端。常用的 WebServer 为 Apache,tomcat 等。
- 静态 web 特点:
- 无法更新,很僵硬
- 轮播图
- JavaScript
- 无法与数据库交互,数据无法持久化,用户无法交互
- 无法更新,很僵硬
1.4、动态 web(服务器)
- 此处的 webserver 为:apache/iis 等
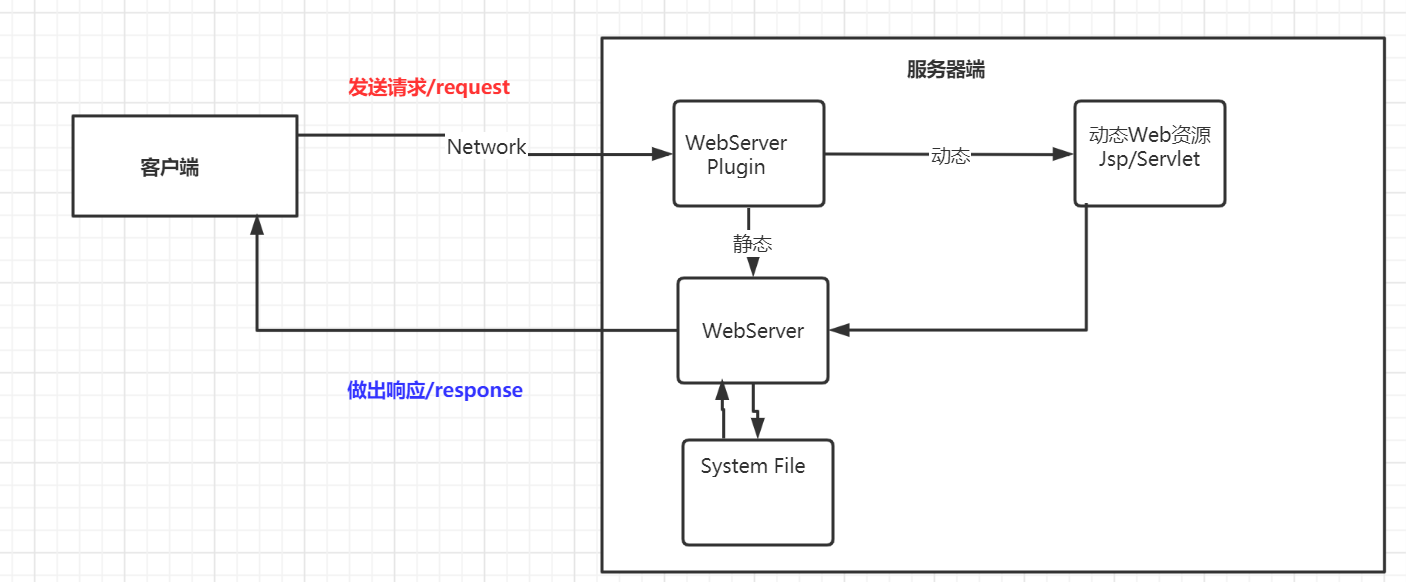
- 动态 web 特点:
- 若动态 web 资源出现错误,后台程序需要重新写 → 停机维护
- web 页面可以更新
- 可以与数据库交互,把数据持久化(注册账号,修改信息等)
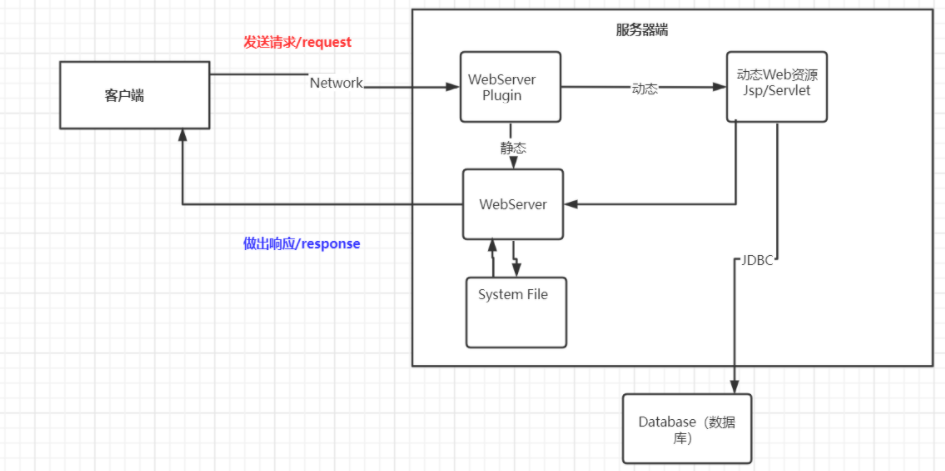
或是这么理解:浏览器 ≈ 客户端
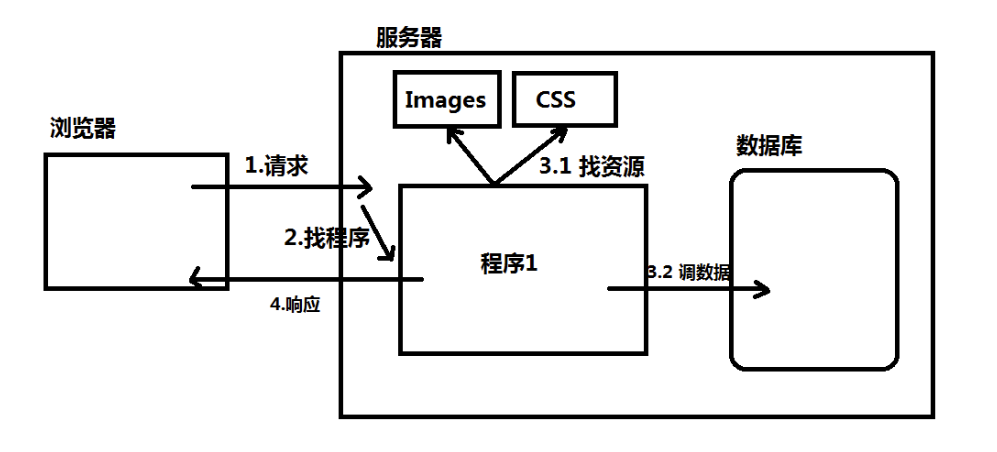
2、web 服务器
2.1、技术讲解
ASP:
微软,运用的就是 ASP
是 HTML 语言中夹杂着 VB 脚本,即 ASP+COM:ASP 做前台页面,后台使用 VB COM+组件对数据进行操作
1
2
3
4
5
6
7<h1>
<h1>
<%>
System.out.println("hello");
</%>
</h1>
</h1>
PHP
- 开发速度快,跨平台,代码简单
- 无法承担大的访问量
Jsp/Servlet
- 是基于 Java 语言的
- 可以承载三高问题:高并发,高性能,高可用
- 语法与 ASP 相似
2.2、web 服务器与 web 应用服务器
web 服务器干嘛的?由上述流程图可以看到,是用来处理用户的一些请求,给用户响应信息的。
web 服务器分为 2 类:
- web 服务器,如:
Apache 服务器
Nginx
IIS
- web 应用服务器,如
Tomcat
resin
jetty
区分:web 服务器不能解析 jsp 等页面,只能处理 js、css、html 等静态资源
并发:web 服务器的并发能力远高于 web 应用服务器
3、Tomcat
引言/介绍

Tomcat 是 Apache 软件基金会(Apache Software Foundation)的 Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。由于有了 Sun 的参与和支持,最新的 Servlet 和 JSP 规范总是能在 Tomcat 中得到体现,Tomcat 5 支持最新的 Servlet 2.4 和 JSP 2.0 规范。因为 Tomcat 技术先进、性能稳定,而且免费,因而深受 Java 爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的 Web 应用服务器。
Tomcat 服务器是一个免费的开放源代码的 Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试 JSP 程序的首选。对于一个初学者来说,可以这样认为,当在一台机器上配置好 Apache 服务器,可利用它响应HTML(标准通用标记语言下的一个应用)页面的访问请求。实际上 Tomcat 是 Apache 服务器的扩展,但运行时它是独立运行的,所以当你运行 tomcat 时,它实际上作为一个与 Apache 独立的进程单独运行的。
Tomcat 实际上运行 JSP 页面和 Servlet。目前 Tomcat 最新版本为 9.0.37
3、1 安装 Tomcat
ps:要配置 tomcat 首先要配置好 java 的 jdk
配置 java 的方法:https://blog.csdn.net/weixin_39691535/article/details/95005254
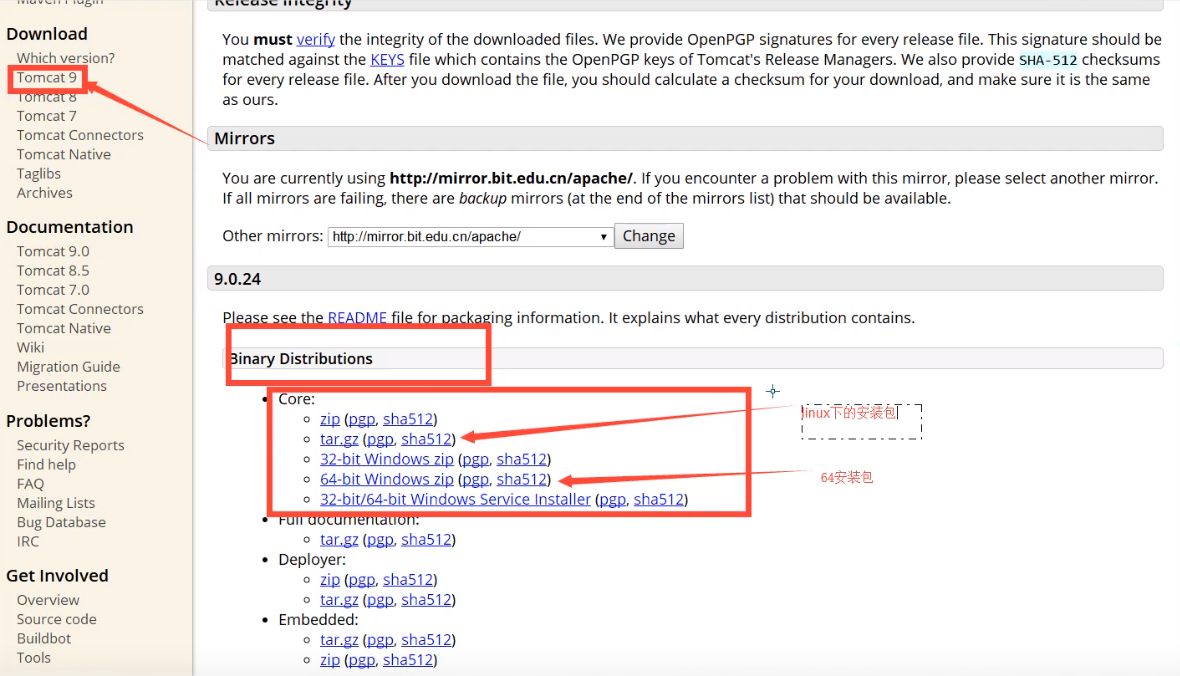

3、2 启动 Tomcat
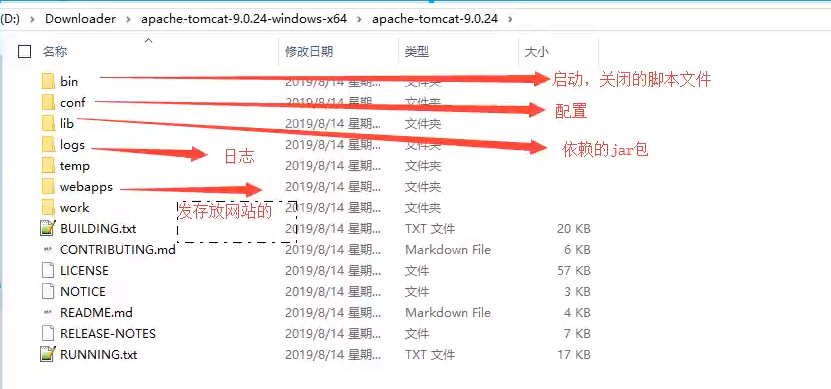
- 文件夹信息作用:
启动,关闭:
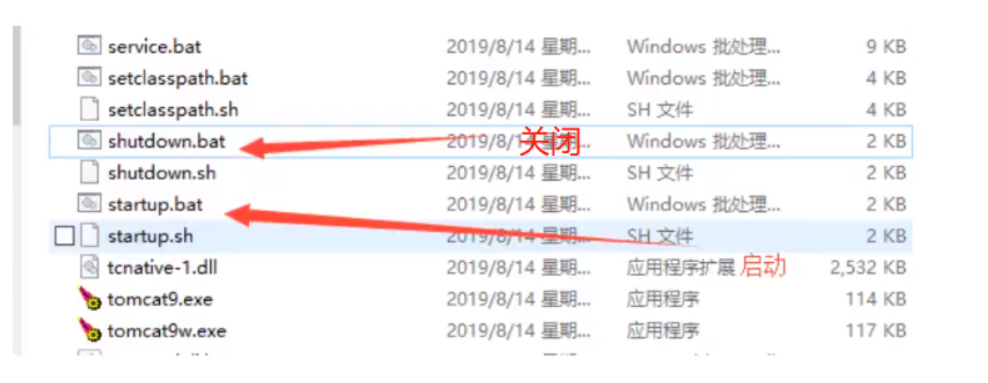
启动 startup.bath 后,浏览器搜索 “localhost:8080” 出现以下页面说明访问成功了:
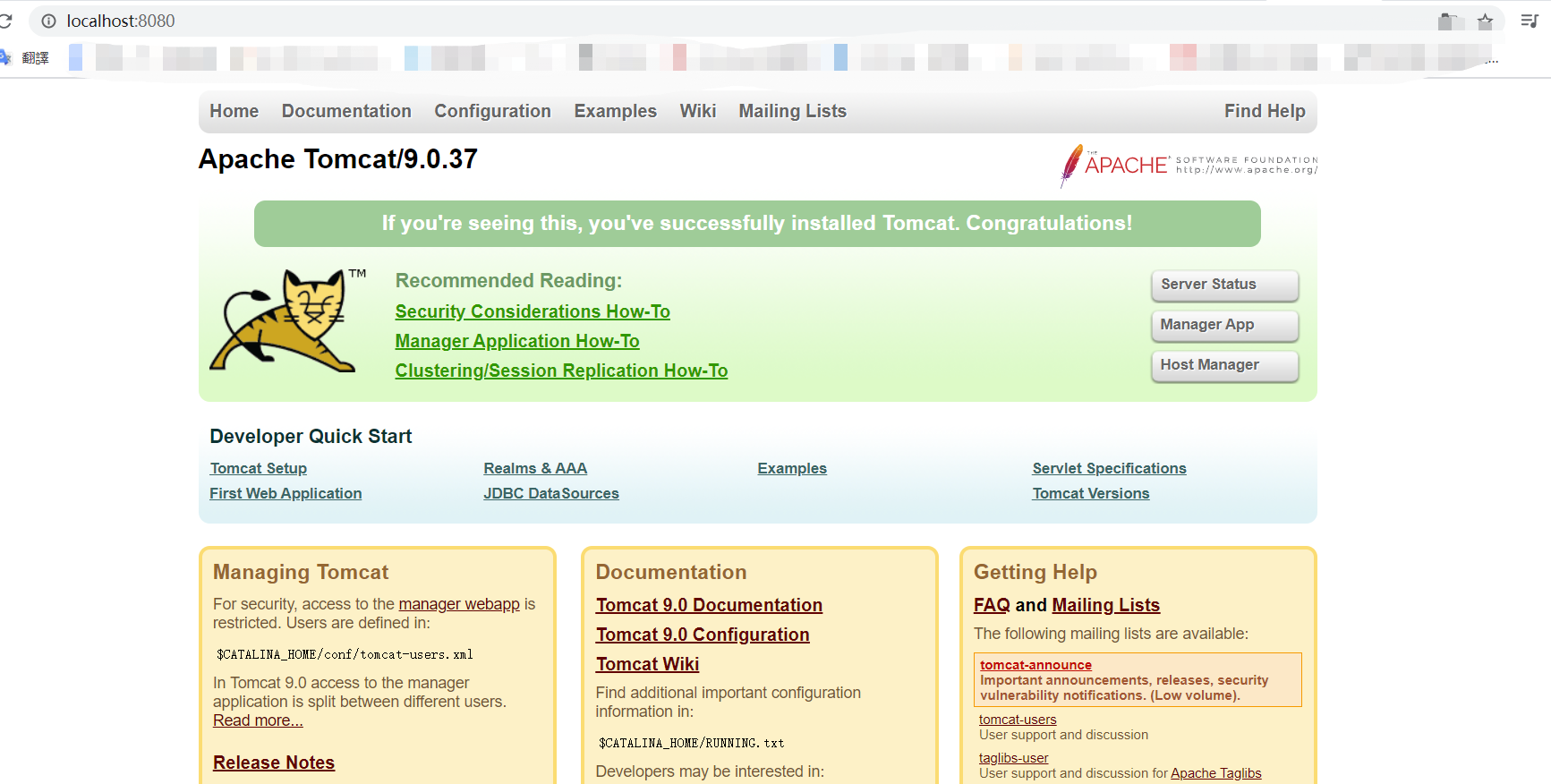
3、3 配置 Tomcat
!(JavaWeb.assets/image-20200731215434250.png)
这个 Server.xml 文件是服务器核心配置文件 下面是其中文件内一部分
作用:
- 配置启动的端口号
 - ps:tomcat 默认端口号:8080 - mysql 默认端口号:3306 - http 默认端口号:80 - https 默认端口号:443
- ps:tomcat 默认端口号:8080 - mysql 默认端口号:3306 - http 默认端口号:80 - https 默认端口号:443 - 配置主机的名字
 - 默认的主机名字:localhost == 127.0.0.1 (可以在 hosts 文件中找到) - 默认网站应用存放位置为:webapps
- 默认的主机名字:localhost == 127.0.0.1 (可以在 hosts 文件中找到) - 默认网站应用存放位置为:webapps - IP 地址和端口的关系:
- 简单理解:IP 就是一个电脑节点的网络物理地址,就像你的家住的那个地址;端口是该计算机逻辑通讯接口,不同的应用程序用不同的端口,就像你家里的各个不同的房间,卧室用来睡觉,餐厅用来吃饭。
- 配置启动的端口号
由此 我们可以解答一个疑问了:究竟网站是如何被访问的呢?
第一步:输入一个域名,enter;
第二步:检查本机中 hosts 配置文件 中是否含有这个域名映射;
- 有:直接返回对应的ip地址 前者为ip地址 后者是域名,而我们ip地址中含有webapps 因此可以访问- 没有:去DNS服务器中找 DNS服务器≠本机 ,DNS通过解析把域名解析成ip 然后返回给客户端 让我们可以访问了。(其中还有交换机一类的进行处理,省略了)
简而言之:
1、输入域名,域名解析(域名解析器 DNS) 2、向服务器发送http请求 3、传输层TCP协议,经过网络传输和路由解析 4、WEB服务器接收HTTP请求 5、服务器处理请求内容,并进行必要的数据交换 6、将相应的内容发回给客户端(响应) 7、浏览器解析HTML 8、显示解析好的内容
3、4 引申-发布一个 web 网站
- 把自己写的网站放在服务器(此处为 Tomcat)中指定的 web 应用文件夹(此处为 webapps)下即可
网站结构:
1 | --webapps:Tomcat服务器的web目录 - ROOT - XXXX,网站目录名 也就是我们所写的网站 - |
4、HTTP
4、1 什么是 HTTP
HTTP (超文本传输协议)是一个简单的请求-响应协议,它通常运行在 TCP 之上。
- 文本:字符串, xxx.html
- 超文本:有链接文本
- 端口号:80
HTTPs (其中的 s 表示 security 安全)
- 是以安全为目标的 HTTP 通道,在 HTTP 的基础上通过传输加密和身份认证保证了传输过程的安全性
- 端口号:443
4、2 HTTP 的两个时代
- http1.0:
- http1.1:
4、3 HTTP 请求
ps:用 Chrome 浏览器如果 F12 发现看不到数据的话需要再按一下 F5 刷新
请求:客户端 → 发送请求 → 服务器
请求报文由三部分组成:请求行+请求头+请求体
以百度为例:
1
2
3
4
5
6General:
Request URL: https://www.baidu.com/ 请求地址
Request Method: GET 请求方法:GET方法/POST方法
Status Code: 200 OK 状态码:200
Remote(远程) Address: 182.61.200.6:443 服务器及其端口号
Referrer Policy: no-referrer-when-downgrade 协议

1、 请求行
请求行由 ①②③ 组成
请求行方式:Get Post(PUT\DELETE\HEAD\TRANSE..)后面是 Rest 风格的
- Get:可携带参数少,大小受限,浏览器 URL 栏内显示提交数据,不安全,但高效
- Post:可携带参数多,大小不受限,浏览器 URL 栏内不显示提交数据,安全,但不高效
2、 HTTP Request headers - 消息头(请求头)
- 请求头由 ④ 组成
1 | Resquest Headers(请求头/消息头): |
*常用的请求头 *
- 格式为 属性名:属性值
| 协议头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Accept | 可接受的响应内容类型(Content-Types)。 |
Accept: text/plain | 固定 |
| Accept-Charset | 可接受的字符集 | Accept-Charset: utf-8 | 固定 |
| Accept-Encoding | 可接受的响应内容的编码方式。 | Accept-Encoding: gzip, deflate | 固定 |
| Accept-Language | 可接受的响应内容语言列表。 | Accept-Language: en-US | 固定 |
| Accept-Datetime | 可接受的按照时间来表示的响应内容版本 | Accept-Datetime: Sat, 26 Dec 2015 17:30:00 GMT | 临时 |
| Authorization | 用于表示 HTTP 协议中需要认证资源的认证信息 | Authorization: Basic OSdjJGRpbjpvcGVuIANlc2SdDE== | 固定 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制。 | Cache-Control: no-cache | 固定 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive Connection: Upgrade | 固定 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个 HTTP 协议 Cookie |
Cookie: $Version=1; Skin=new; | 固定:标准 |
| Content-Length | 以 8 进制表示的请求体的长度 | Content-Length: 348 | 固定 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 | Content-MD5: oD8dH2sgSW50ZWdyaIEd9D== | 废弃 |
| Content-Type | 请求体的 MIME 类型 (用于 POST 和 PUT 请求中) | Content-Type: application/x-www-form-urlencoded | 固定 |
| Date | 发送该消息的日期和时间(以RFC 7231中定义的”HTTP 日期”格式来发送) | Date: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Expect | 表示客户端要求服务器做出特定的行为 | Expect: 100-continue | 固定 |
| From | 发起此请求的用户的邮件地址 | From: user@itbilu.com | 固定 |
| Host | 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 | Host: www.itbilu.com:80 Host: www.itbilu.com | 固定 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 | If-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Modified-Since | 允许在对应的资源未被修改的情况下返回 304 未修改 | If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| If-None-Match | 允许在对应的内容未被修改的情况下返回 304 未修改( 304 Not Modified ),参考 超文本传输协议 的实体标记 | If-None-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Range | 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 | If-Range: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 | 固定 |
| Origin | 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 |
Origin: http://www.itbilu.com | 固定: 标准 |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 | Pragma: no-cache | 固定 |
| Proxy-Authorization | 用于向代理进行认证的认证信息。 | Proxy-Authorization: Basic IOoDZRgDOi0vcGVuIHNlNidJi2== | 固定 |
| Range | 表示请求某个实体的一部分,字节偏移以 0 开始。 | Range: bytes=500-999 | 固定 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但 RFC 制作标准时给拼错了,后来也就将错就错使用Referer了。 |
Referer: http://itbilu.com/nodejs | 固定 |
| TE | 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用”trailers”表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为 0 的块之后还接收到一些额外的字段。 |
TE: trailers,deflate | 固定 |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/…… | |
| Upgrade | 要求服务器升级到一个高版本协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 | 固定 |
| Via | 告诉服务器,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 itbilu.com.com (Apache/1.1) | 固定 |
| Warning | 一个一般性的警告,表示在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning | 固定 |
3、 请求体
请求体由 ⑤ 组成
这个就是我们要上传的实质数据,比如:name=apple&password=123456
4、4 HTTP 响应
响应:服务器 → 做出回应 → 客户端
响应报文一般由三部分组成:响应行、响应头、响应体
以百度为例:
1
2
3
4
5Response Headers:
Cache-Control: private 缓存控制
Connection: keep-alive 连接
Content-Encoding: gzip 编码
Content-Type: text/html;charset=utf-8 类型

1、 响应行
由 ① 和 ② 组成,其中 ① 是报文协议和版本;② 是状态码及状态描述
状态码:
状态码 定义 说明 1XX 信息 接收到请求,继续处理 2XX 成功 操作成功地收到,理解和接受 3XX 重定向 为了完成请求,必须采取进一步措施 4XX 客户端错误 请求的语法有错误,或者不能完全被满足,请求错误,责任在客户端,比如客户端请求了一个不存在的资源,或者客户端未被授权,禁止访问 5XX 服务端错误 服务器无法完成明显有效地请求,服务端抛出异常,比如路由出错,HTTP 版本不支持等
2、 响应头
由 ③ 组成 格式为 属性名:属性值
响应头 说明 实例 状态 Access-Control-Allow-Origin 指定哪些网站可以 跨域源资源共享Access-Control-Allow-Origin: * 临时 Accept-Patch 指定服务器所支持的文档补丁格式 Accept-Patch: text/example;charset=utf-8 固定 Accept-Ranges 服务器所支持的内容范围 Accept-Ranges: bytes 固定 Age 响应对象在代理缓存中存在的时间,以秒为单位 Age: 12 固定 Allow 对于特定资源的有效动作; Allow: GET, HEAD 固定 Cache-Control 通知从服务器到客户端内的所有缓存机制,表示它们是否可以缓存这个对象及缓存有效时间。其单位为秒 Cache-Control: max-age=3600 固定 Connection 针对该连接所预期的选项 Connection: close 固定 Content-Disposition 对已知 MIME 类型资源的描述,浏览器可以根据这个响应头决定是对返回资源的动作,如:将其下载或是打开。 Content-Disposition: attachment; filename=”fname.ext” 固定 Content-Encoding 响应资源所使用的编码类型。 Content-Encoding: gzip 固定 Content-Language 响就内容所使用的语言 Content-Language: zh-cn 固定 Content-Length 响应消息体的长度,用 8 进制字节表示 Content-Length: 348 固定 Content-Location 所返回的数据的一个候选位置 Content-Location: /index.htm 固定 Content-MD5 响应内容的二进制 MD5 散列值,以 Base64 方式编码 Content-MD5: IDK0iSsgSW50ZWd0DiJUi== 已淘汰 Content-Range 如果是响应部分消息,表示属于完整消息的哪个部分 Content-Range: bytes 21010-47021/47022 固定 Content-Type 当前内容的 MIME类型Content-Type: text/html; charset=utf-8 固定 Date 此条消息被发送时的日期和时间(以RFC 7231中定义的”HTTP 日期”格式来表示) Date: Tue, 15 Nov 1994 08:12:31 GMT 固定 ETag 对于某个资源的某个特定版本的一个标识符,通常是一个 消息散列 ETag: “737060cd8c284d8af7ad3082f209582d” 固定 Expires 指定一个日期/时间,超过该时间则认为此回应已经过期 Expires: Thu, 01 Dec 1994 16:00:00 GMT 固定 Last-Modified 所请求的对象的最后修改日期(按照 RFC 7231 中定义的“超文本传输协议日期”格式来表示) Last-Modified: Dec, 26 Dec 2015 17:30:00 GMT 固定 Link 用来表示与另一个资源之间的类型关系,此类型关系是在RFC 5988中定义 Link:; rel=”alternate”固定 Location 用于在进行重定向,或在创建了某个新资源时使用。 Location: http://www.itbilu.com/nodejs 固定 P3P P3P 策略相关设置 P3P: CP=”This is not a P3P policy! 固定 Pragma 与具体的实现相关,这些响应头可能在请求/回应链中的不同时候产生不同的效果 Pragma: no-cache 固定 Proxy-Authenticate 要求在访问代理时提供身份认证信息。 Proxy-Authenticate: Basic 固定 Public-Key-Pins 用于防止中间攻击,声明网站认证中传输层安全协议的证书散列值 Public-Key-Pins: max-age=2592000; pin-sha256=”……”; 固定 Refresh 用于重定向,或者当一个新的资源被创建时。默认会在 5 秒后刷新重定向。 Refresh: 5; url=http://itbilu.com 固定 Retry-After 如果某个实体临时不可用,那么此协议头用于告知客户端稍后重试。其值可以是一个特定的时间段(以秒为单位)或一个超文本传输协议日期。 示例 1:Retry-After: 120 示例 2: Retry-After: Dec, 26 Dec 2015 17:30:00 GMT 固定 Server 服务器的名称 Server: nginx/1.6.3 固定 Set-Cookie 设置 HTTP cookieSet-Cookie: UserID=itbilu; Max-Age=3600; Version=1 固定: 标准 Status 通用网关接口的响应头字段,用来说明当前 HTTP 连接的响应状态。 Status: 200 OK Trailer Trailer用户说明传输中分块编码的编码信息Trailer: Max-Forwards 固定 Transfer-Encoding 用表示实体传输给用户的编码形式。包括: chunked、compress、deflate、gzip、identity。Transfer-Encoding: chunked 固定 Upgrade 要求客户端升级到另一个高版本协议。 Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 固定 Vary 告知下游的代理服务器,应当如何对以后的请求协议头进行匹配,以决定是否可使用已缓存的响应内容而不是重新从原服务器请求新的内容。 Vary: * 固定 Via 告知代理服务器的客户端,当前响应是通过什么途径发送的。 Via: 1.0 fred, 1.1 itbilu.com (nginx/1.6.3) 固定 Warning 一般性警告,告知在实体内容体中可能存在错误。 Warning: 199 Miscellaneous warning 固定 WWW-Authenticate 表示在请求获取这个实体时应当使用的认证模式。 WWW-Authenticate: Basic 固定
3、 响应体
- 由 ⑥ 组成
- 是服务器返回给客户端的文本信息
5、 Maven
- 由于在 javaweb 开发中我们需要用到 jar 包,但我们每次手动去添加会不会太麻烦了?
- 因此,我们有了 Maven 来帮我们自动导入 jar 包并配置
5、1 Maven 项目架构管理工具
- maven 核心思想:约定大于配置
- maven 规定了如何写 java 代码,不能违反规范
5、2 Maven 下载

5、3 Maven 配置环境变量
在“此电脑”的高级环境变量中配置如下几项内容
- 新建系统变量 MAVEN_HOME 变量值:maven 的目录
- 新建系统变量 M2_HOME 变量值:maven 的 lib 目录
- 编辑系统变量 Path 添加变量值: ;%MAVEN_HOME%\bin
假如在 cmd 中查看 mvn 版本能出现以下情况,则为配置成功:

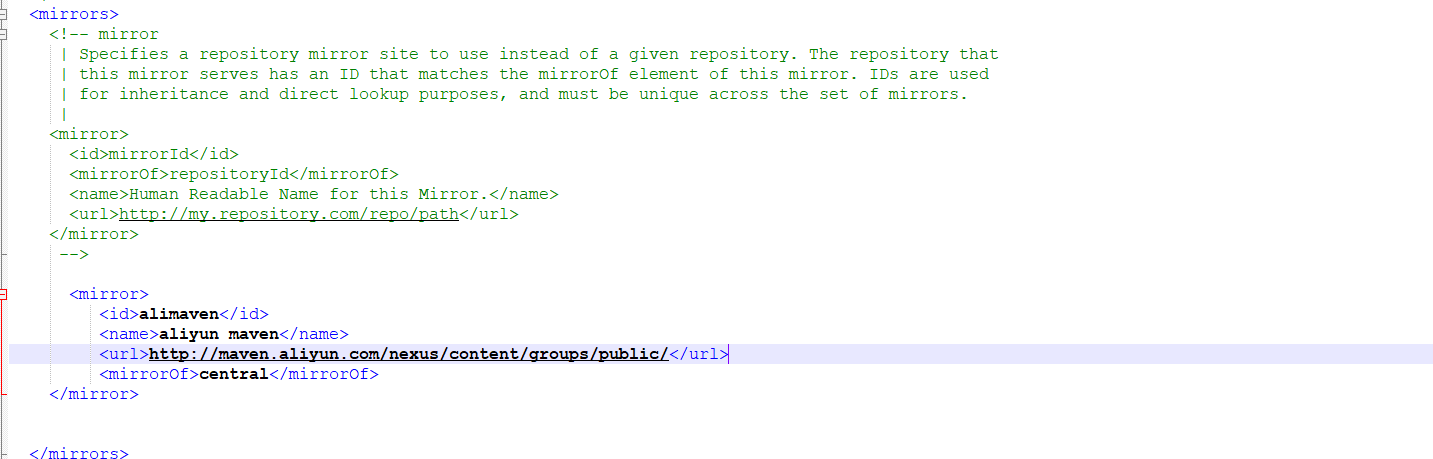
5、4 阿里云镜像
镜像 mirrors 用于加速我们下载
常用 阿里云镜像:
1
2
3
4
5
6<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>放置于:setting.xml 中
5、5 本地仓库
远程仓库:github
本体仓库:localRepository
1 | <localRepository>C:\Users\60446\Desktop\学习文件\environment\apache-maven-3.6.3\maven-repo</localRepository> |
5、6 在 IDEA 中使用 Maven
启动 IDEA
创建一个 Maven Web 项目
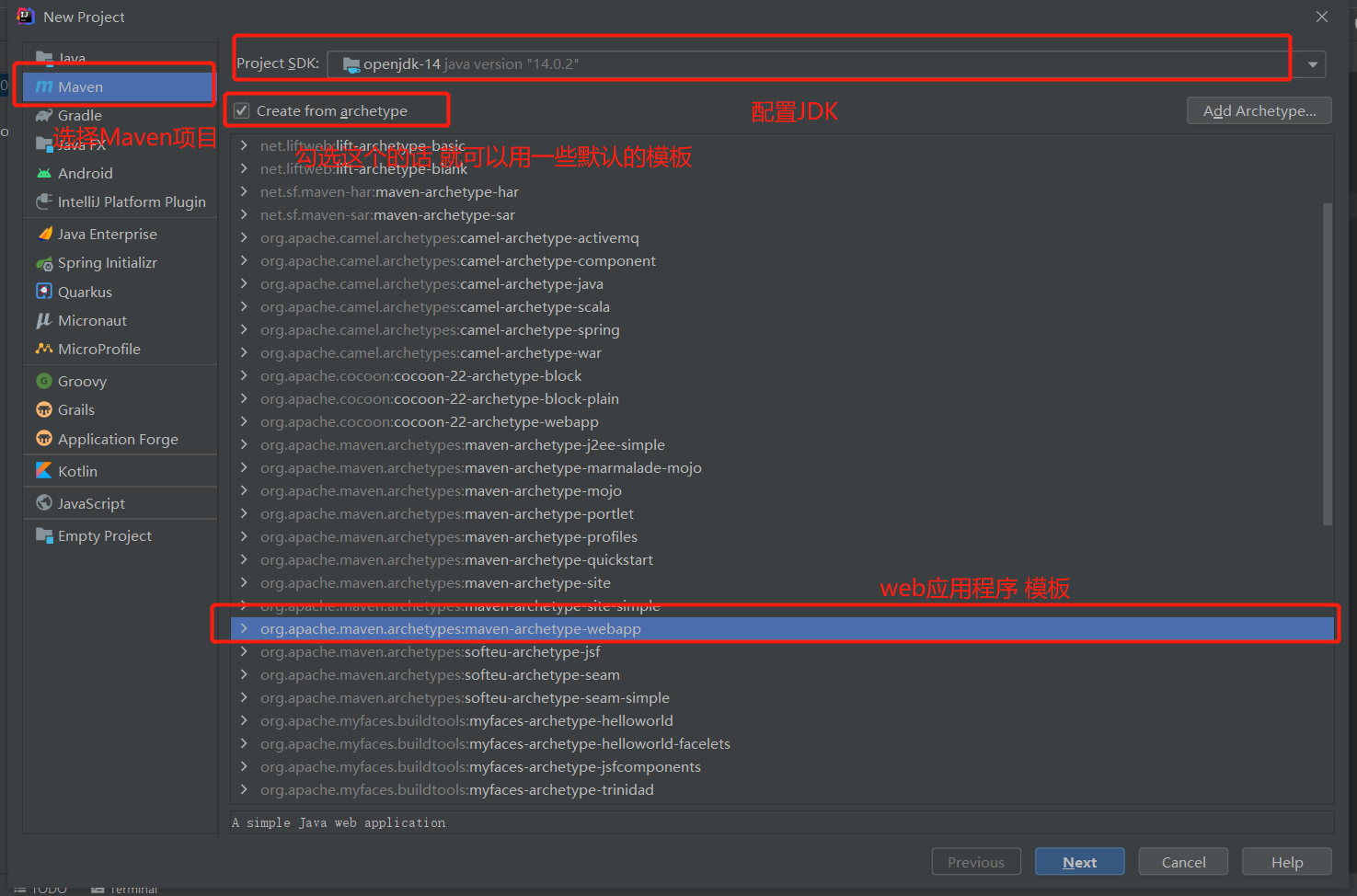 )
)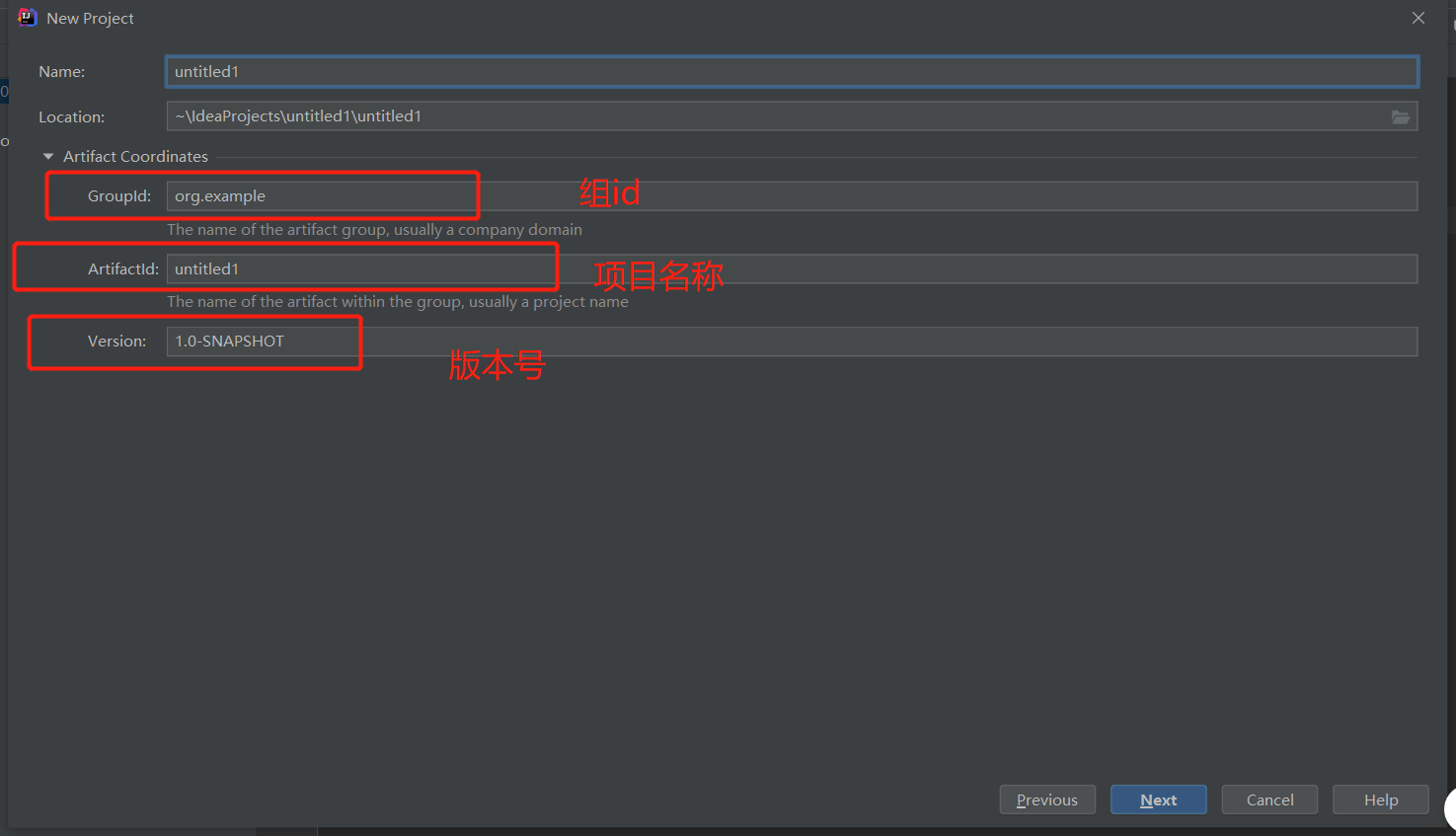 )
)
如果是第一次配置的话 要等待下载响应配置 出现下图则搭建成功

IDEA 中 Maven 配置
ps:IDEA 中配置 Maven 项目,Maven home 会使用 IDEA 自带的两个版本之一,因此需要我们手动去替换,很重要!!!否则在后续创建 maven 项目的时候很有可能会没有 src 目录,这是很深刻的教训!
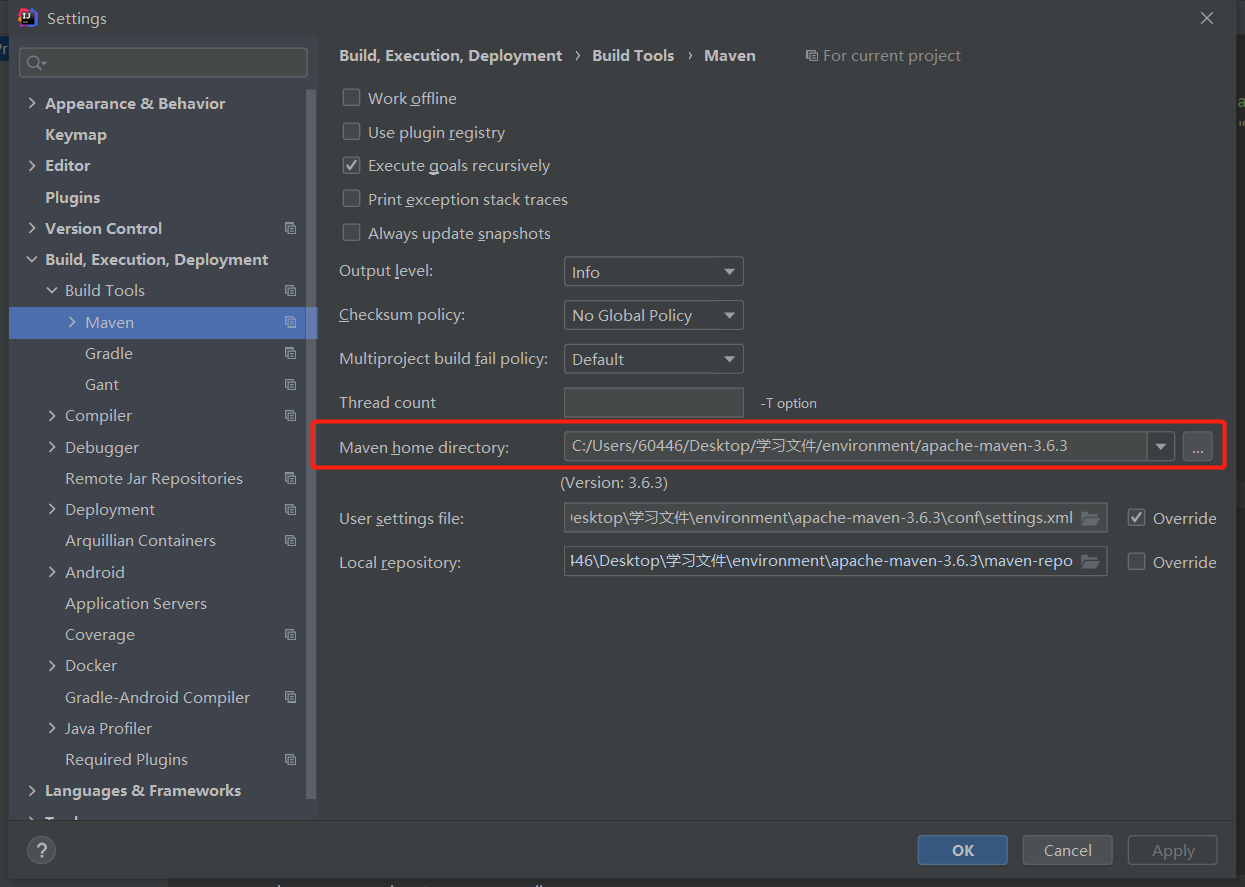
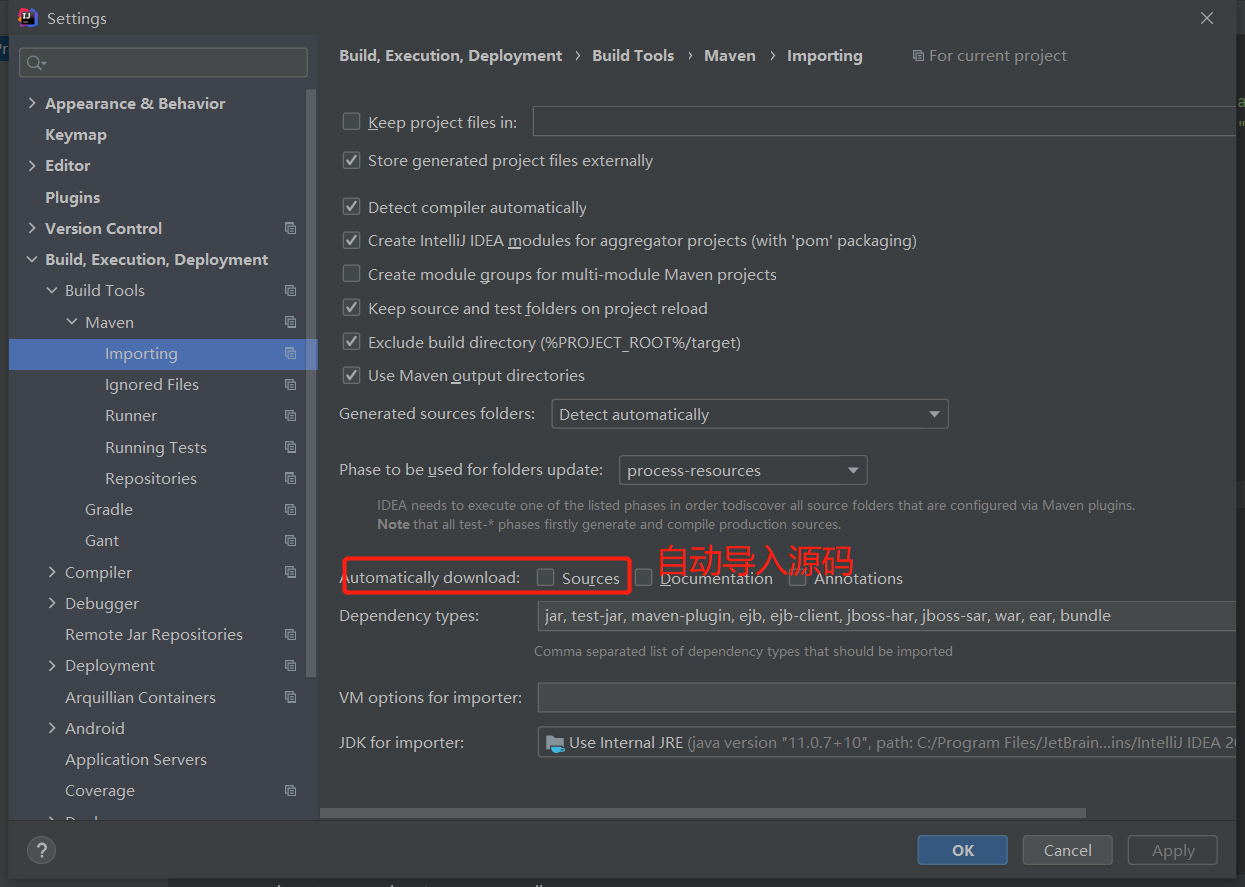
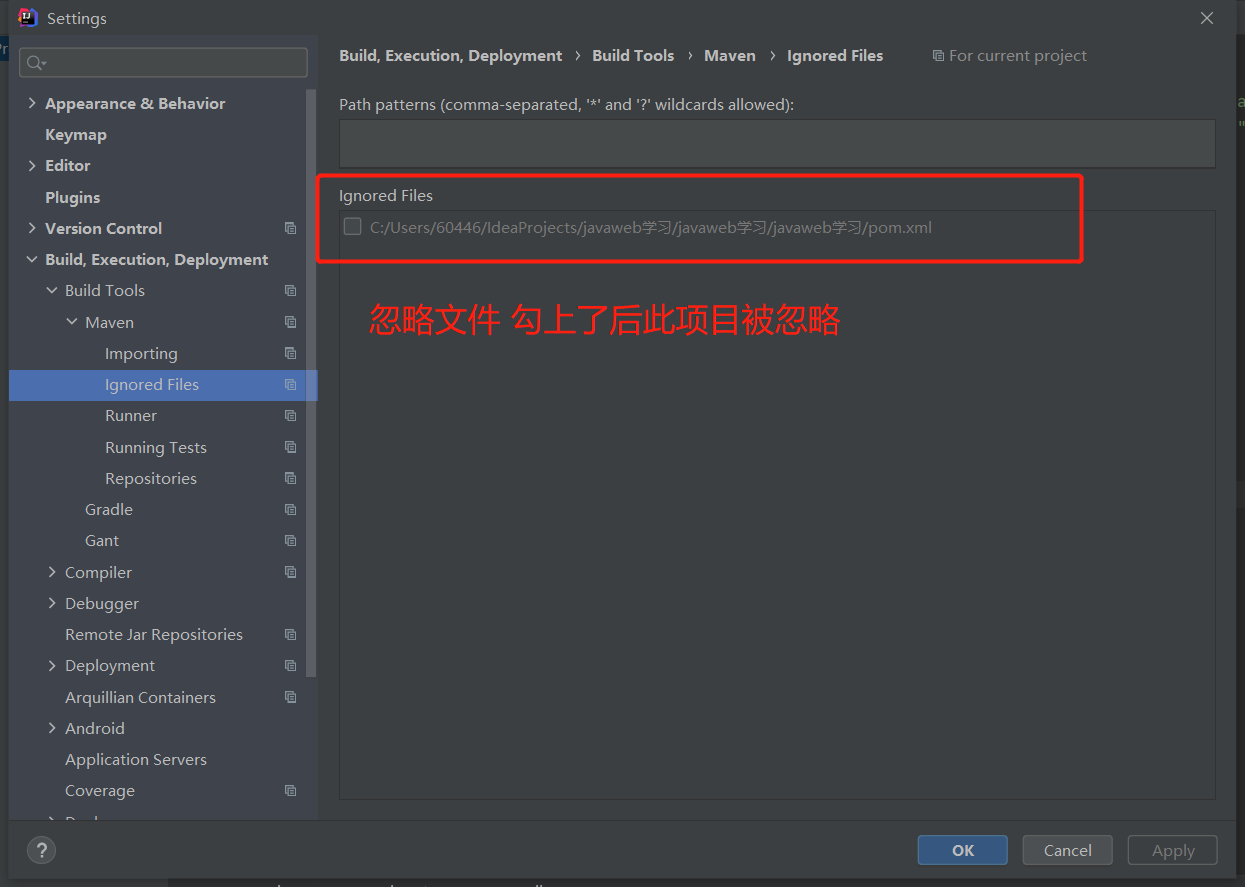
有 webapp 模板的 maven 文件:
WEB-INF+web.xml :Web 的配置
index.jsp 网页
5、7 创建普通的 Maven 项目
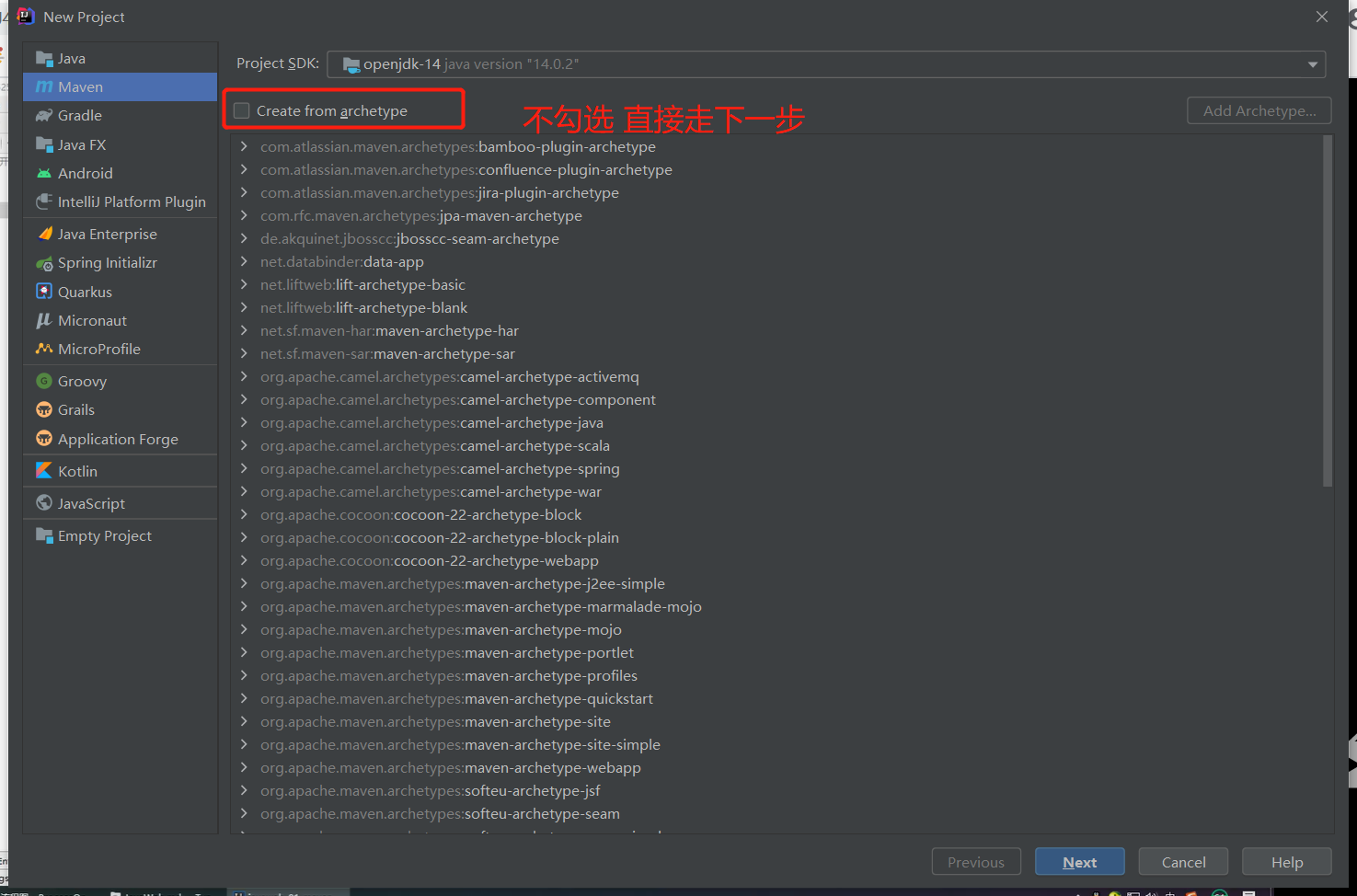

一个干净的 maven 项目:
蓝色 java:放置 java 源代码
resource:放置配置文件
绿色 java:测试使用
5、8 标记文件夹功能
Sources Root:源码目录
Test Sources Root:测试源码目录
Resources Root:资源目录
Test Resources Root:资源测试目录
标记方法 1:
](https://er11.oss-cn-shenzhen.aliyuncs.com/img/image-20200906181630896.png)
标记方法 2:
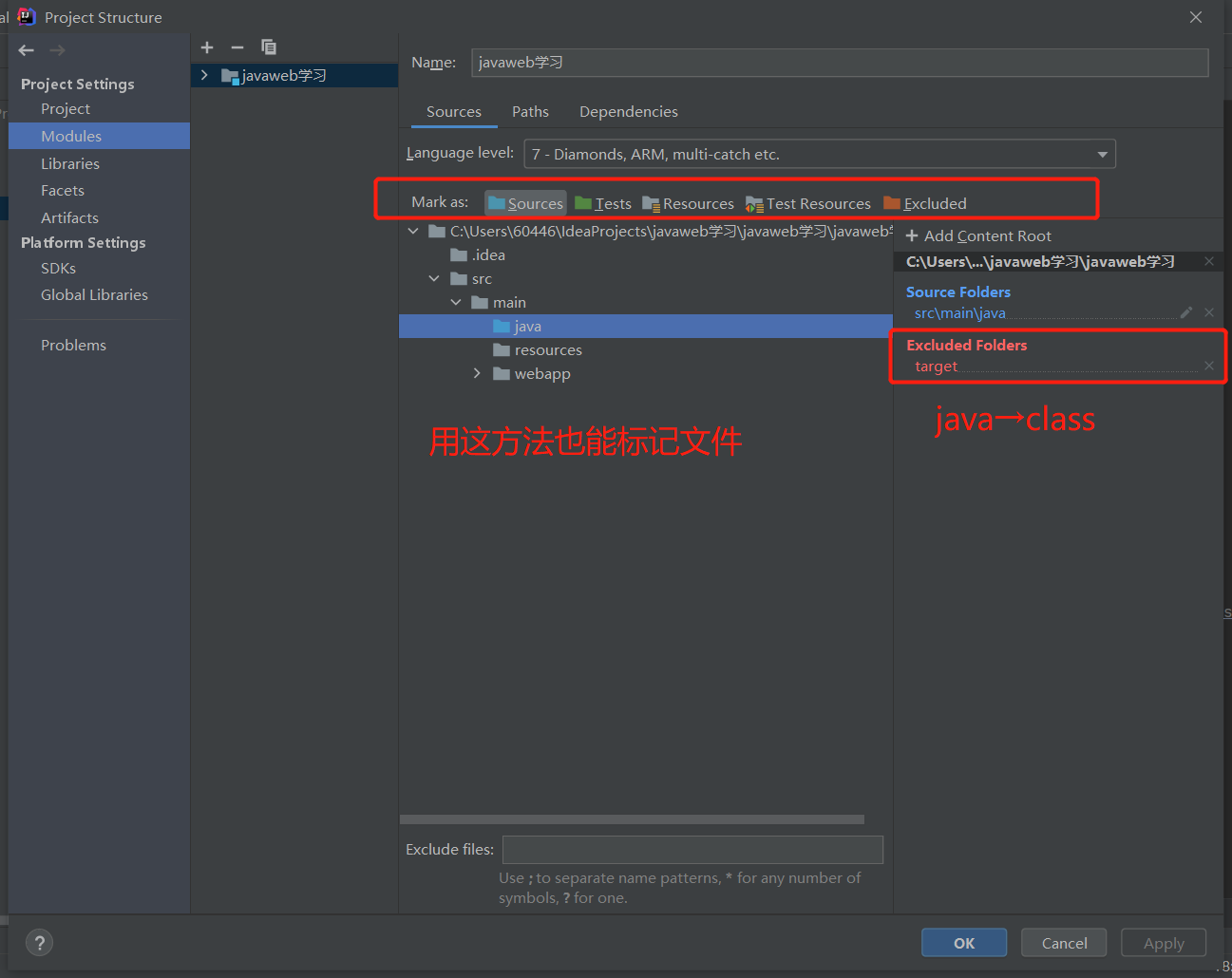
5、9 在 IDEA 中配置 Tomcat
前序工作,选中项目: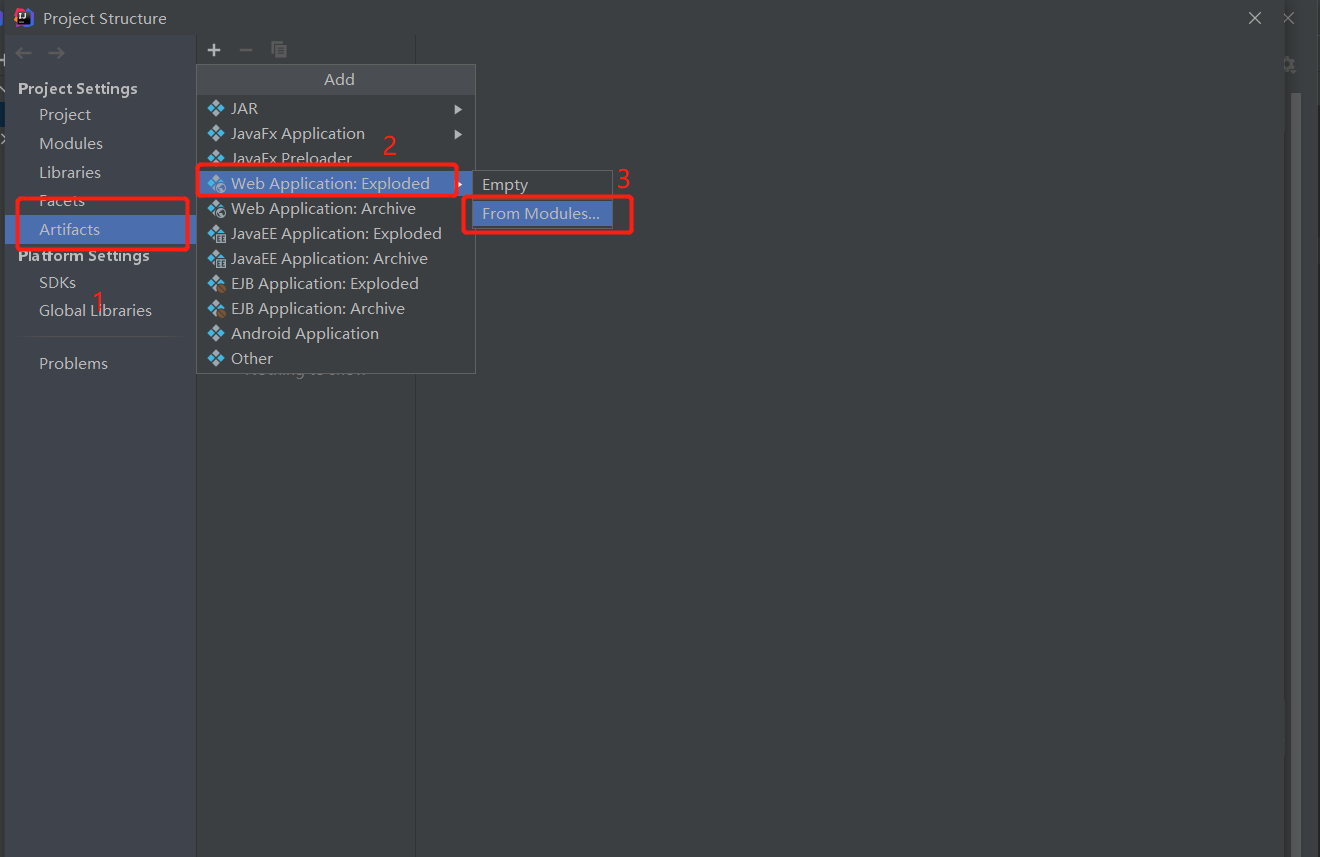

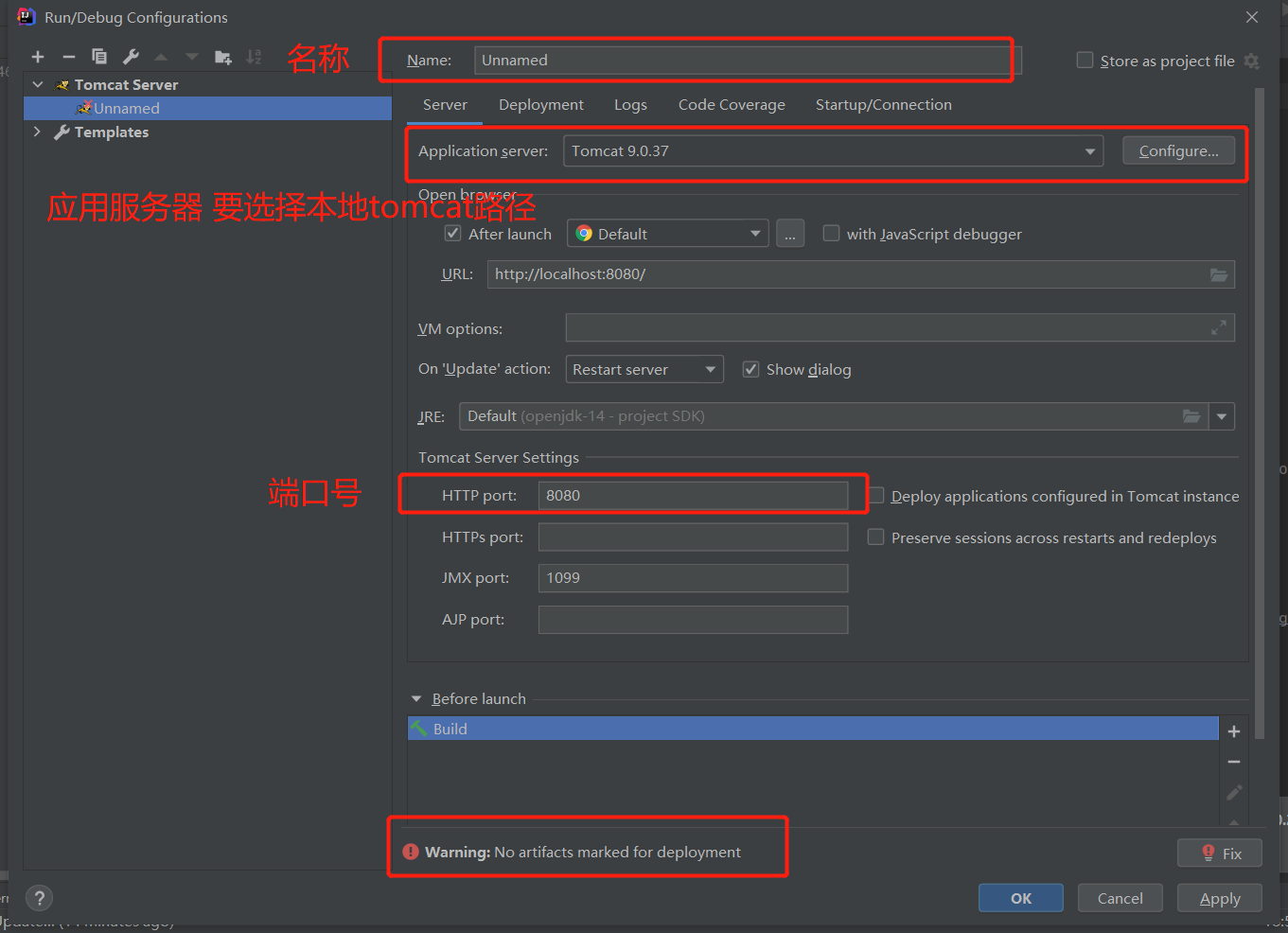
为什么会有这个 Warning 呢?因为我们访问一个网站需要指定一个文件夹的名字
Warning 的解决方案:
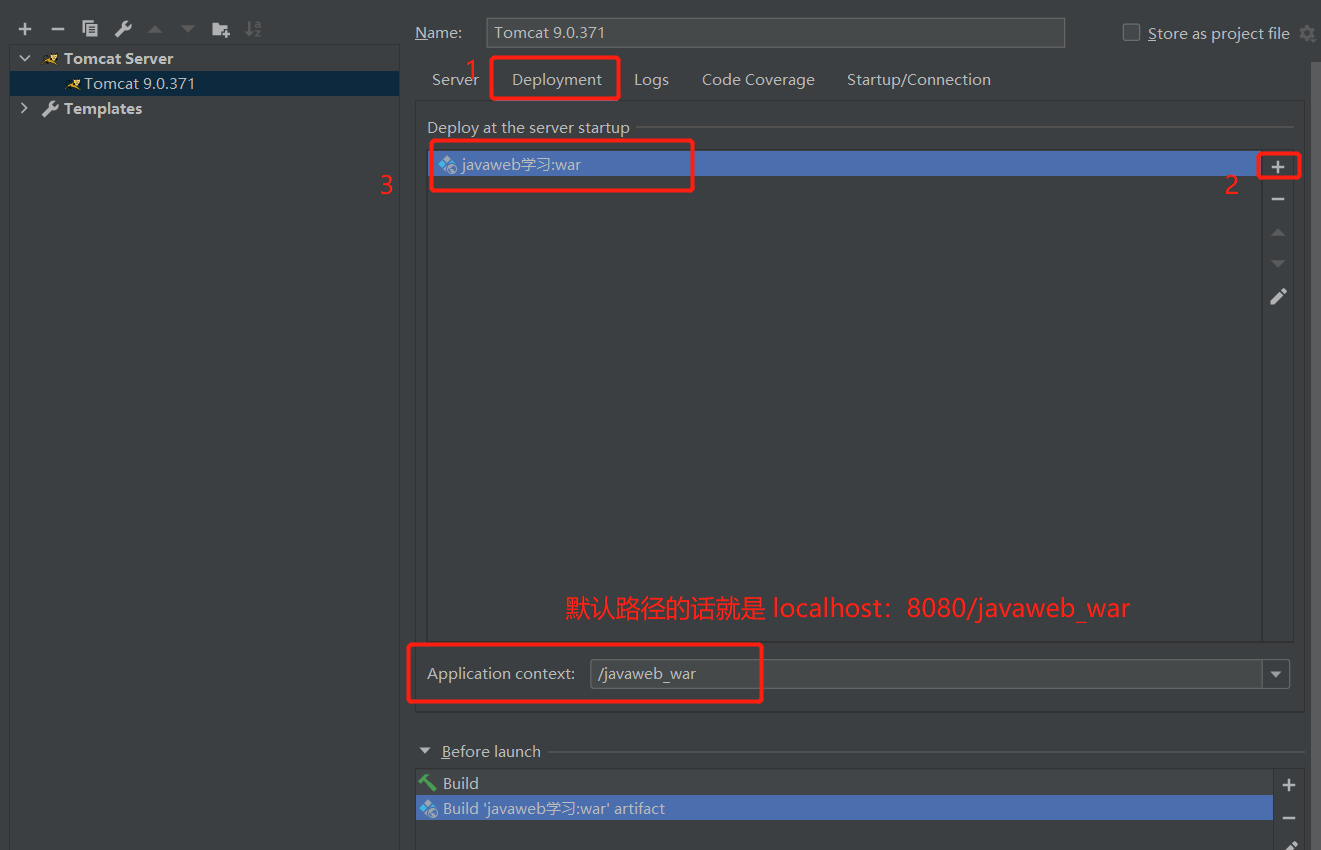
- 测试:启动 Tomact 后出现

5、10 POM 文件
- pom.xml 是 maven 项目核心
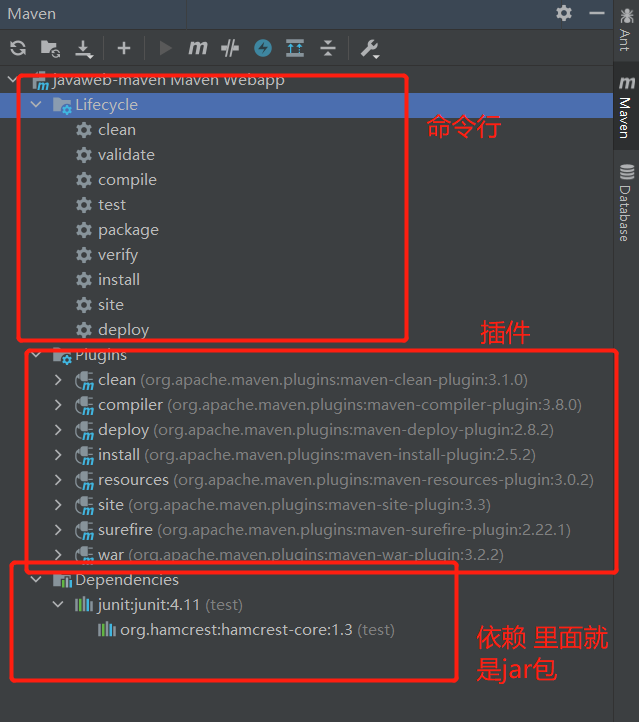
如果是 webapp 的 maven 项目应该有(暂时):

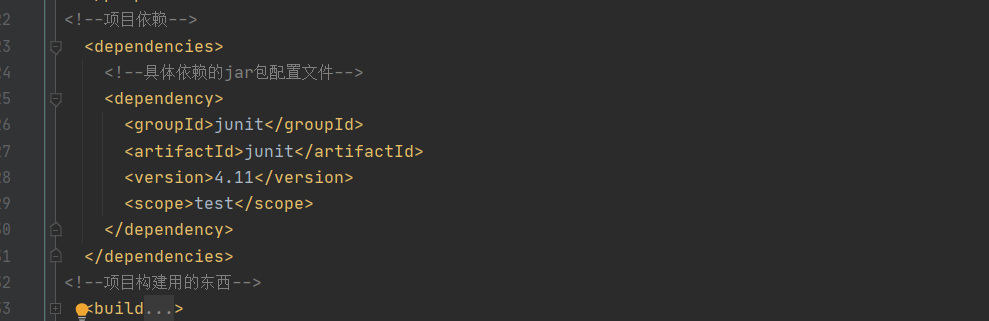
其中 dependencies 中的依赖 我们可以在 maven 仓库:https://mvnrepository.com/中搜索我们需要的依赖 直接复制粘贴过来 maven 会帮我们自动导入jar 包及该 jar 包所依赖的其他 jar 包这就是 maven 的高级之处了。
maven 资源文件导出问题 解决方法
1 | <build> |
6、 Servlet
6、1 Servlet 简介
Servlet 接口有两个默认实现类:HttpServlet 和 GenericServlet
- servlet 是 sun 公司的开发动态 web 的一门技术
- sun 在 API 中提供一个接口叫做 servlet,想使用该接口需要完成两个步骤:
- 编写一个类,去实现 Servlet 接口
- 把开发好的 java 类部署到 web 服务器中
因此:我们把实现了 Servlet 接口的【java 程序】叫做 Servlet 程序
6、2 HelloServlet
创建一个 普通的 Maven 项目,删掉其中的 src 目录,往后在这里建立 Moudle(作为父工程);
关于 Maven 父子工程理解:
在父项目中会有
1
2
3
4<modules>
此处子项目叫Son1
<module>Son1</module>
</modules>在子项目中会有
1
2
3
4
5<parent>
<artifactId>Servlet</artifactId>
<groupId>com.HPG</groupId>
<version>1.0-SNAPSHOT</version>
</parent>父项目中 jar 包子项目可以直接使用
编写一个 Servle 程序
编写一个普通类
实现 Servlet 接口,需要 extends 的是 HttpServlet
逻辑关系图: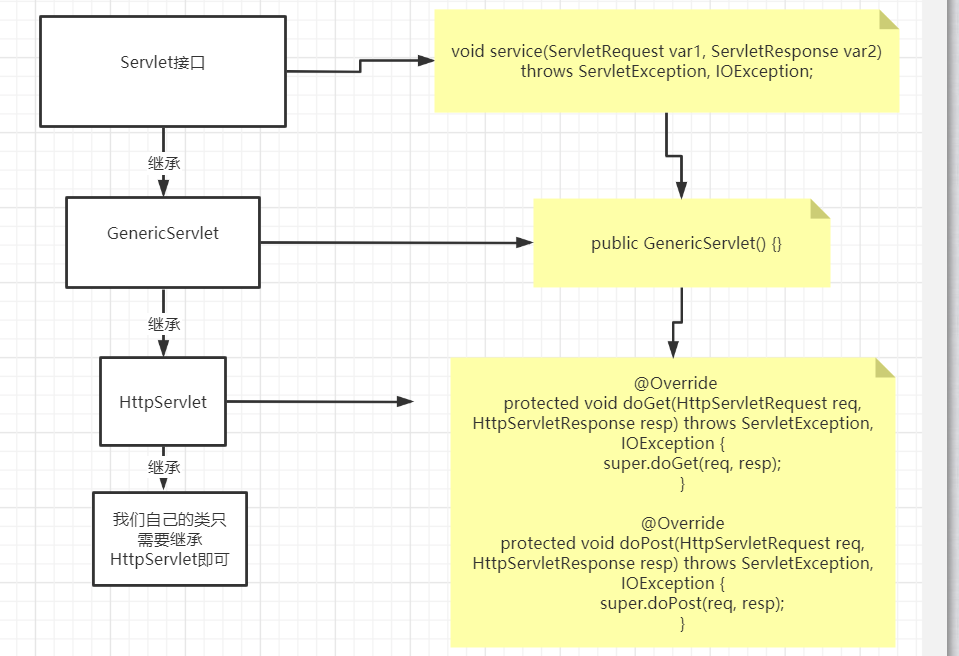
源码分析:
1
2Servlet.class:
void service(ServletRequest var1, ServletResponse var2) throws ServletException, IOException;1
2
3
4
5GenericServlet.class:
public abstract class GenericServlet implements Servlet, ServletConfig, Serializable{
public GenericServlet() {
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20HTTPServlet.class:
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String protocol = req.getProtocol();
String msg = lStrings.getString("http.method_get_not_supported");
if (protocol.endsWith("1.1")) {
resp.sendError(405, msg);
} else {
resp.sendError(400, msg);
}
}
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
String protocol = req.getProtocol();
String msg = lStrings.getString("http.method_post_not_supported");
if (protocol.endsWith("1.1")) {
resp.sendError(405, msg);
} else {
resp.sendError(400, msg);
}
}1
2
3
4
5
6
7
8
9
10
11HelloServlet.java:
public class HelloServlet extends HttpServlet {
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
PrintWriter writer = resp.getWriter();
writer.print("Hello!Servlet");
}
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
}
}编写 Servlet 的映射
为什么需要映射?因为我们写的是 java 程序,但需要通过浏览器访问,浏览器又需要连接 web 服务器,因此我们需要在 web 服务器中注册我们写的 Servlet,并需要给 web 服务器一个浏览器能够访问的路径。这就叫映射。
1
2
3
4
5
6
7
8
9
10<!--注册Servlet-->
<servlet>
<servlet-name>hello</servlet-name>
<servlet-class>com.HPG.Servlet.HelloServlet</servlet-class>
</servlet>
<!--Servlet的请求路径-->
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
配置 Tomcat
ps:注意项目发布路径(/xxxx)
启动测试(注意看网址栏的区别)
不用 servlet:
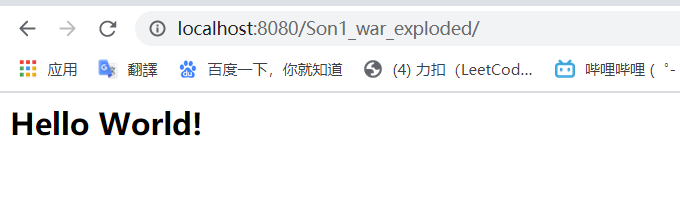
用 servlet:
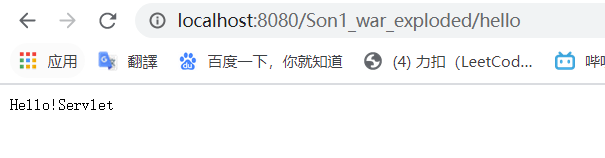
注意事项:假如有多个 Servlet 程序,要记得在 Deployment 处更换包
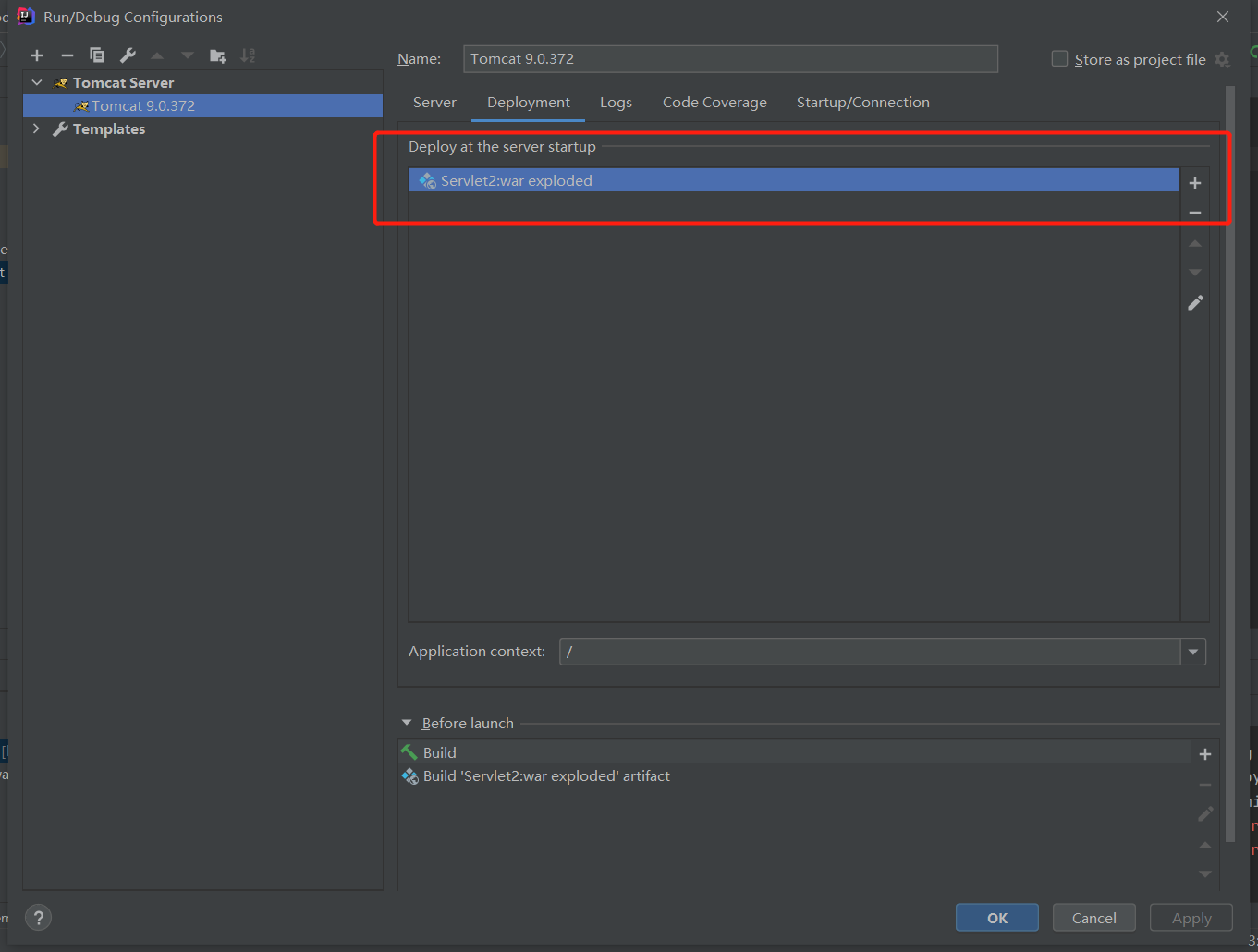
6、3 Servlet 原理
Servlet 只有放在容器中,方可执行,且 Servlet 容器种类较多,如 Tomcat,WebLogic 等。下图为简单的 请求响应 模型: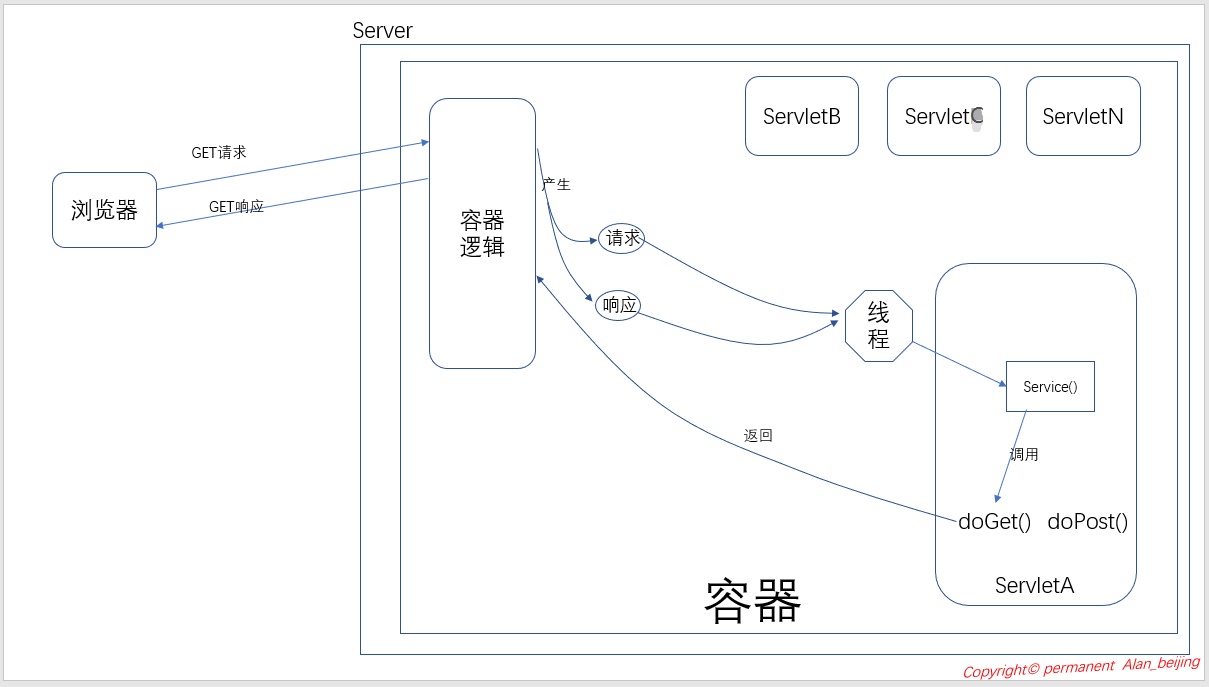
逻辑:
- 浏览器向服务器发出 GET 请求(请求服务器 ServletA)
- 服务器上的容器逻辑接收到该 url,根据该 url 判断为 Servlet 请求,此时容器逻辑将产生两个对象:请求对象(HttpServletRequest)和响应对象(HttpServletResponce)
- 容器逻辑根据 url 找到目标 Servlet(本示例目标 Servlet 为 ServletA),且创建一个线程 A
- 容器逻辑将刚才创建的请求对象和响应对象传递给线程 A
- 容器逻辑调用 Servlet 的 service()方法
- service()方法根据请求类型(本示例为 GET 请求)调用 doGet()(本示例调用 doGet())或 doPost()方法
- doGet()执行完后,将结果返回给容器逻辑
- 线程 A 被销毁或被放在线程池中
6、4 Mapping 问题
一个 Servlet 可以指定一个映射路径
1
2
3
4
5<!--Servlet的请求路径-->
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>一个 Servlet 可以指定多个映射路径
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<!--Servlet的请求路径-->
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/hello</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/hello2</url-pattern>
</servlet-mapping>
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/hello3</url-pattern>
</servlet-mapping>一个 Servlet 可以指定通用映射路径
1
2
3
4
5<!--Servlet的请求路径-->
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/hello/*</url-pattern>
</servlet-mapping>可以指定默认请求路径
1
2
3
4
5<!--Servlet的请求路径-->
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>/*</url-pattern>
</servlet-mapping>可以指定通用前缀/后缀路径
1
2
3
4
5
6<!--Servlet的请求路径-->
<!--此时*前面不能加任何东西-->
<servlet-mapping>
<servlet-name>hello</servlet-name>
<url-pattern>*.abc</url-pattern>
</servlet-mapping>
优先级来说的话:是固有映射路径最高,找不到才走默认的
6、5 ServletContext
web 容器(Tomcat)在启动的时候,他会给每个 web 程序都创建一个对应的 Servlet 对象,他代表当前的 web 应用。
ServletContext 功能
1、共享数据
举例:我把一个数据存在了 ServletContext 中,再用 一个 Servlet 去调用 让我们看看效果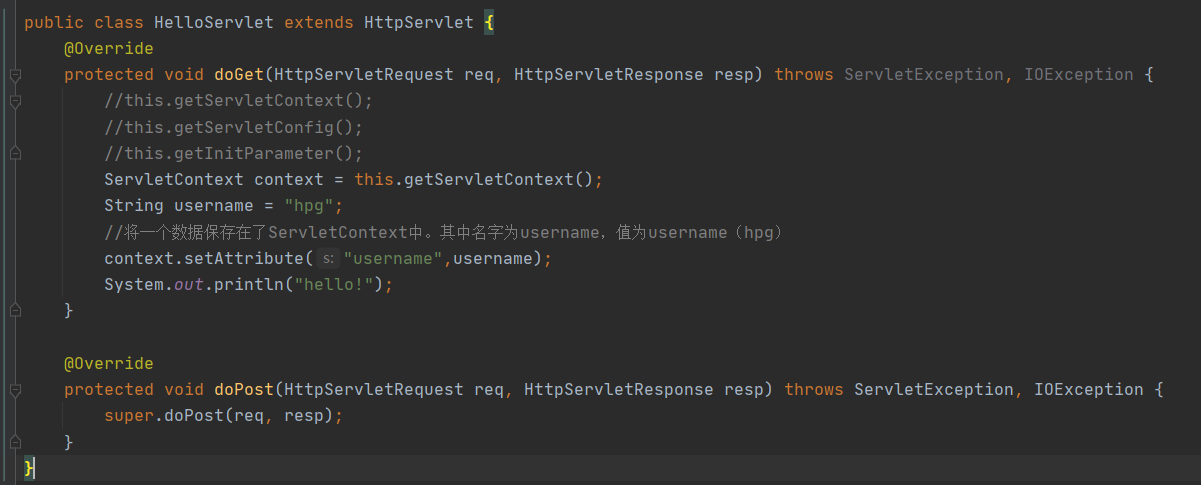
代码:
1 | public class HelloServlet extends HttpServlet { |
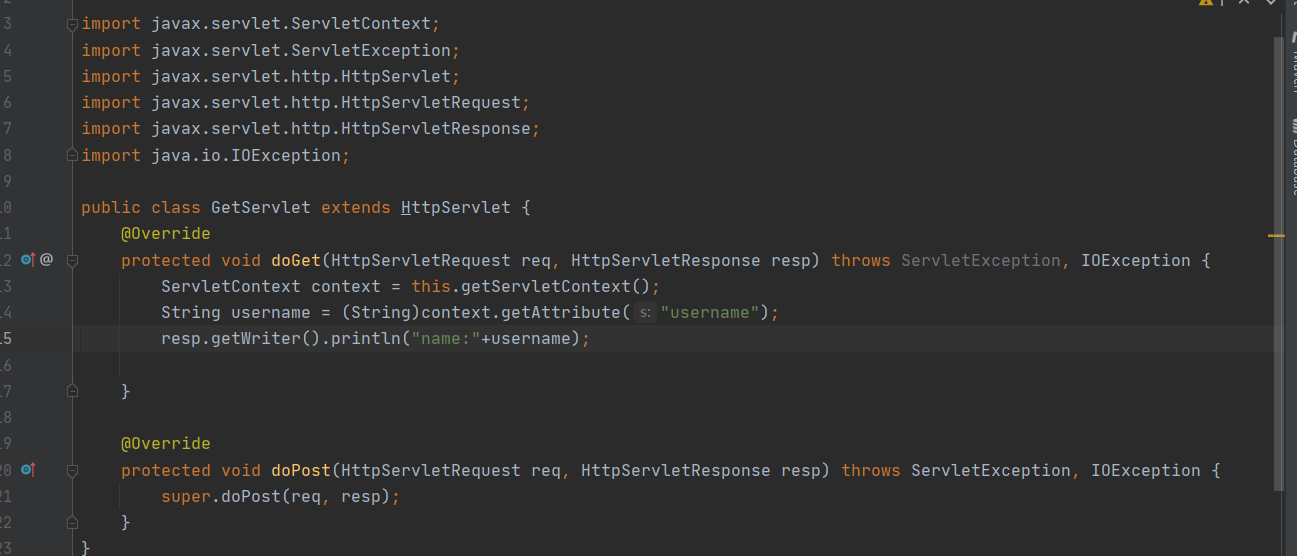
代码:
1 | public class GetServlet extends HttpServlet { |
同样的 在 web.xml 部署路径: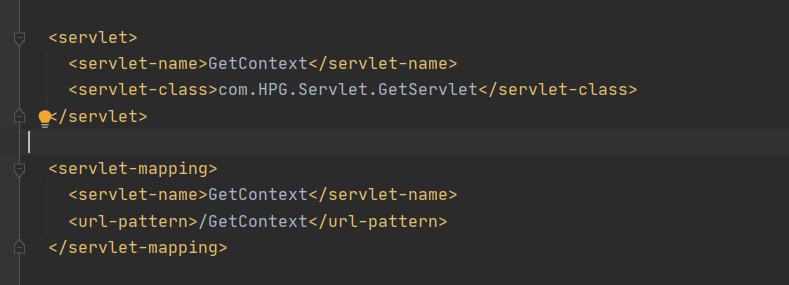
我们先启动 hello,再启动 GetContext: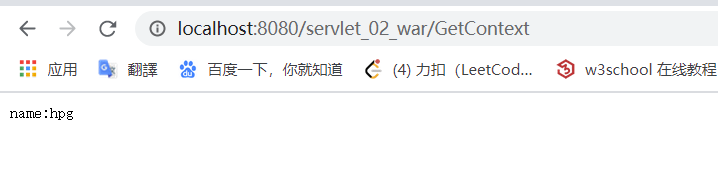
2、获取初始化参数
P1,P2 在 web.xml 中配置

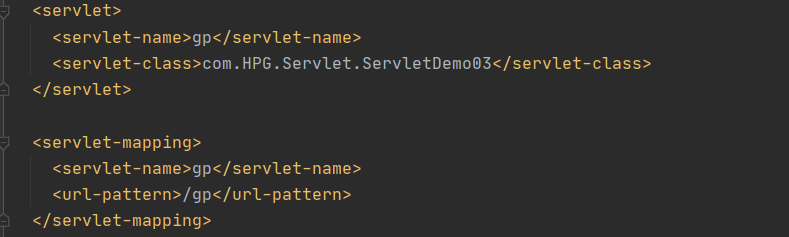
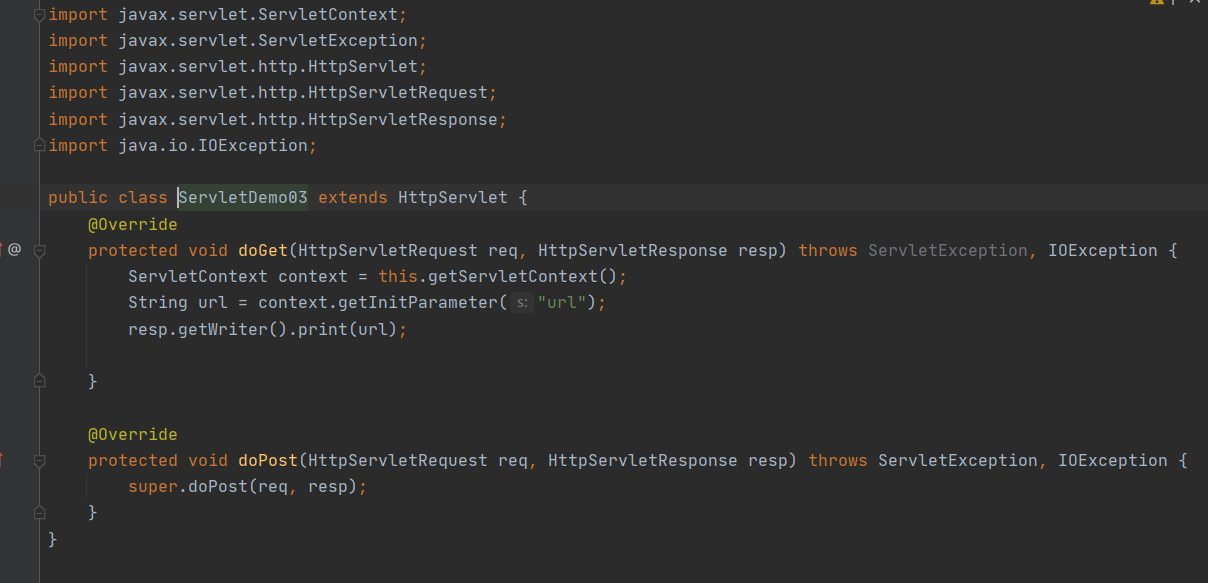
代码:
1 | public class ServletDemo03 extends HttpServlet { |
3、请求转发
在 web.xml 中配置
代码:
转发的页面是 gp 的页面,而转
1 | public class ServletDemo04 extends HttpServlet { |
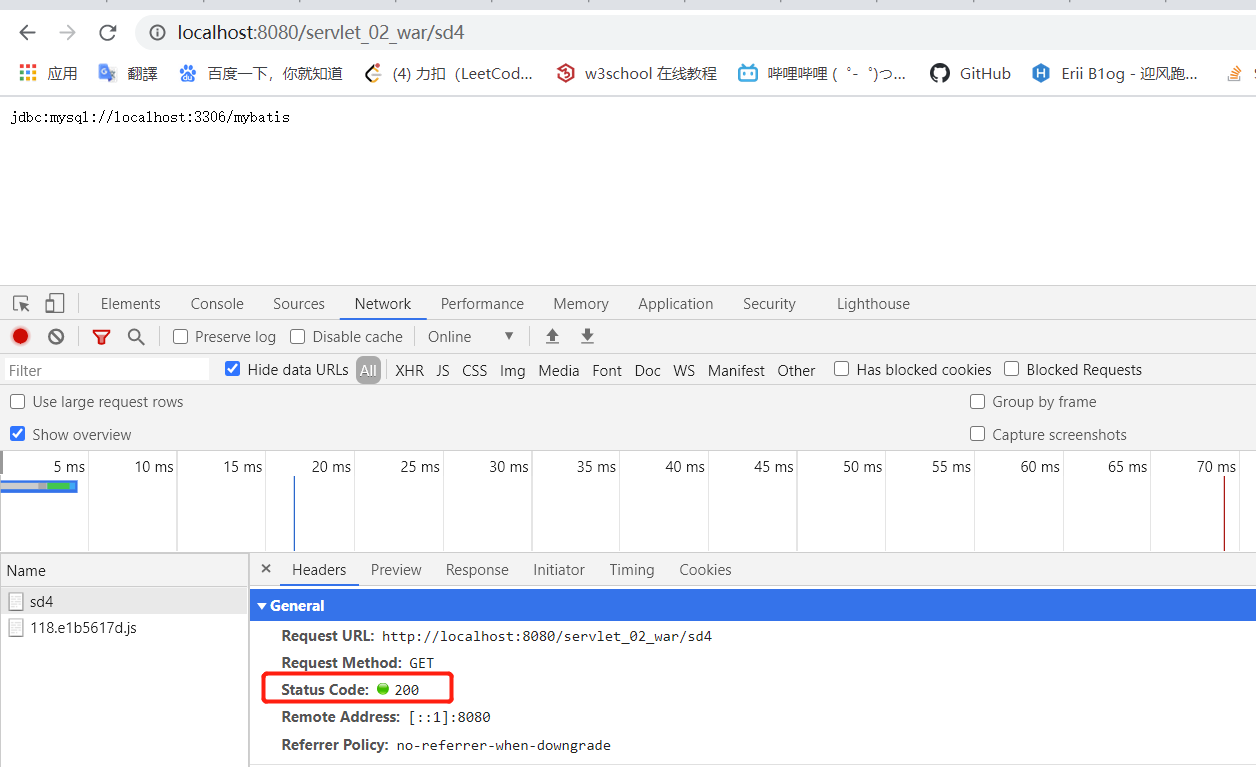
发的状态码 200 表示着转发成功
我们虽然请求的是 sd4,但实际上我们走的是 gp
请求转发和重定向的问题
首先让我们看一幅图:
A 想要获取 C 的信息,但是无法直接获取,只能通过 B 去获取 C 信息,再经由 B 传给 A
自始至终,A 都没有访问到 C,这就叫请求转发
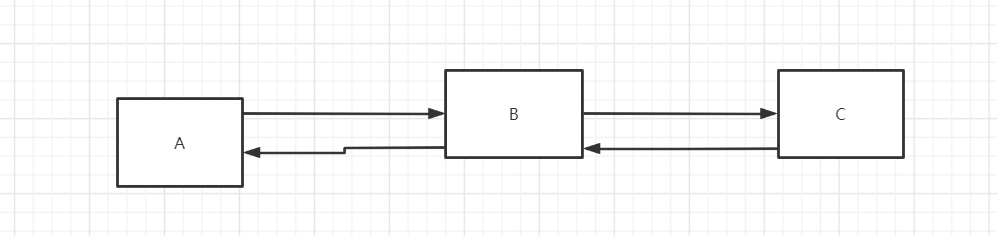
再让我们看一幅图:
A 想要一个资源,去找 B,B 说我没有,让 A 去找 C,于是 A 就去请求 C 了
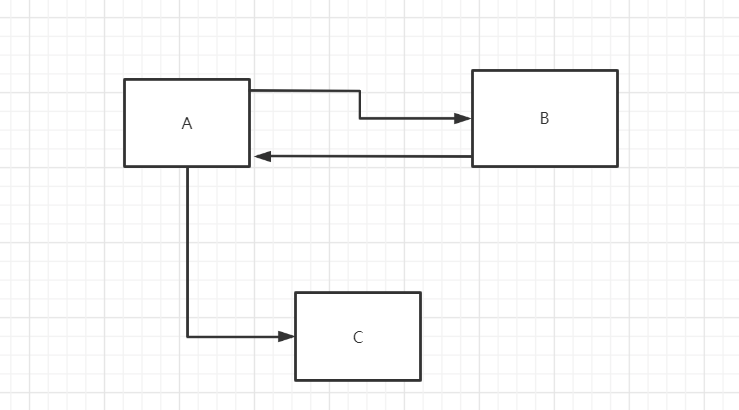
(日后再补充)
4、 访问资源文件
说到资源文件,就不得不提到一个类 “Properties”
在 java 目录或者是 resources 目录下 新建 xxxx.properties,都会被打包在同一个路径(classes)下,我们称该路径为 classpath;
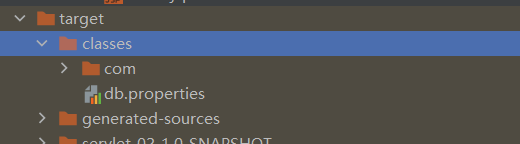
下面我们来演示一下如何访问资源目录
比如,我们在 resources 目录下创建好了一个 db.properties 后启动 tomcat,我们可以在 target/classes 目录中发现生成一个 db.properties——这是准备工作
db.properties 中的内容为: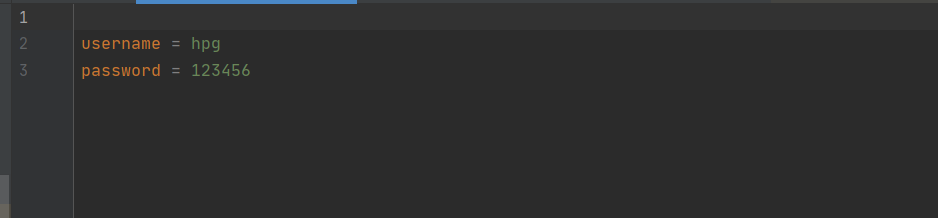
同样的,我们首先在 web.xml 中配置好映射: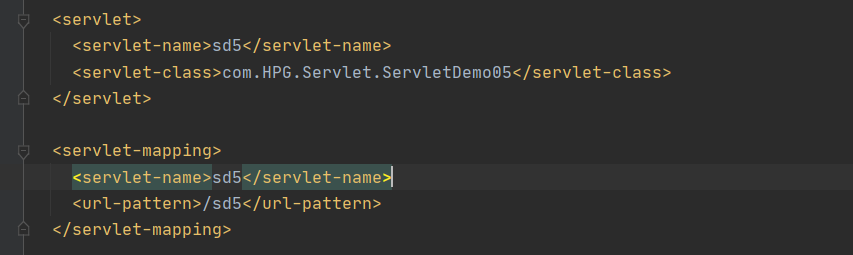
写好了一个关于访问资源文件的 Servlet
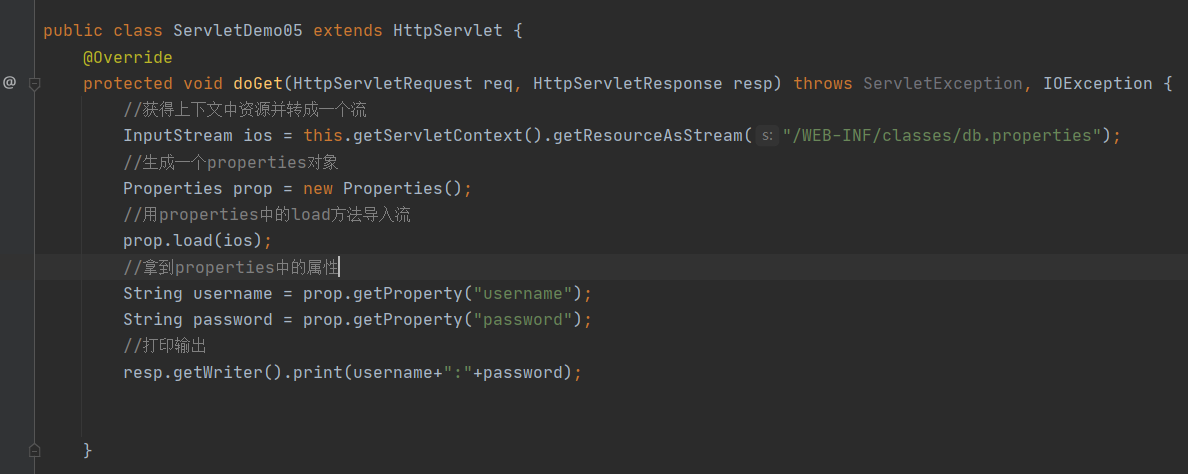
代码:
1 | public class ServletDemo05 extends HttpServlet { |
效果: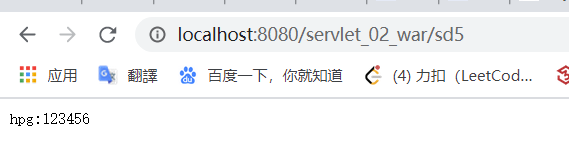
6、6 HttpServletResponse
web 服务器接收到客户端的 http 请求,会针对该请求,分别创建一个代表请求的 HttpServletRequest 对象和一个代表响应的 HttpServletResponse;
- 假如我们要获取客户端请求过来的参数:找 HttpServletRequest
- 假如我们需要给客户端响应一些信息:找 HttpServletResponse
分类
负责给浏览器发送数据的方法
1 | //在ServletResponse.class中 |
负责给浏览器发送响应头的方法
1 | //在ServletResponse.class中 |
响应的状态码
1 | int SC_CONTINUE = 100; |
功能
给浏览器输出各种信息
几秒刷一次啊 这种的,还有许多,之后再补充 8.
下载文件
- 要获取下载文件的路径
- 下载的文件名是什么
- 让浏览器能够支持下载我们需要的东西
- 获取下载文件的输入流
- 创建缓冲区
- 获取 OutputStream 对象
- 将 FileOutputStream 流写入到 buffer 缓冲区
- 使 OutputStream 将缓冲区的数据输出到客户端
创建一个 FileServlet 类去实现下载
1 | public class FileServlet extends HttpServlet { |
同理,在 web.xml 中配置好映射关系
1 | <servlet> |
别忘了重新配置 Tomcat 的 deployment,启动 Tomcat 在浏览器中搜索响应的映射得到:
表示下载成功!
验证码功能
验证功能分两部分,一个是前端校验,一个是后端校验
后端校验:Java 的图片类,生成一个图片
创建要给 ImageServlet 去实现:
1 | public class ImageServlet extends HttpServlet { |
同理:在 web.xml 中配置映射
1 | <servlet> |
启动 Tomcat ,每次刷新我们得到的图片都不同 就不再截第二张了
实现重定向
- 再复习一遍重定向:A 想访问一个资源,去找 B,B 说不在我这啊,让 A 去找 C,这过程就叫重定向
- 常用于用户登录啊等等场景
1 | void sendRedirect(String var1) throws IOException; |
在 web.xml 中再配置一个映射
1 | <servlet> |
1 | public class RedirectServlet extends HttpServlet { |
当我在浏览器输入/red 后 页面会跳转到: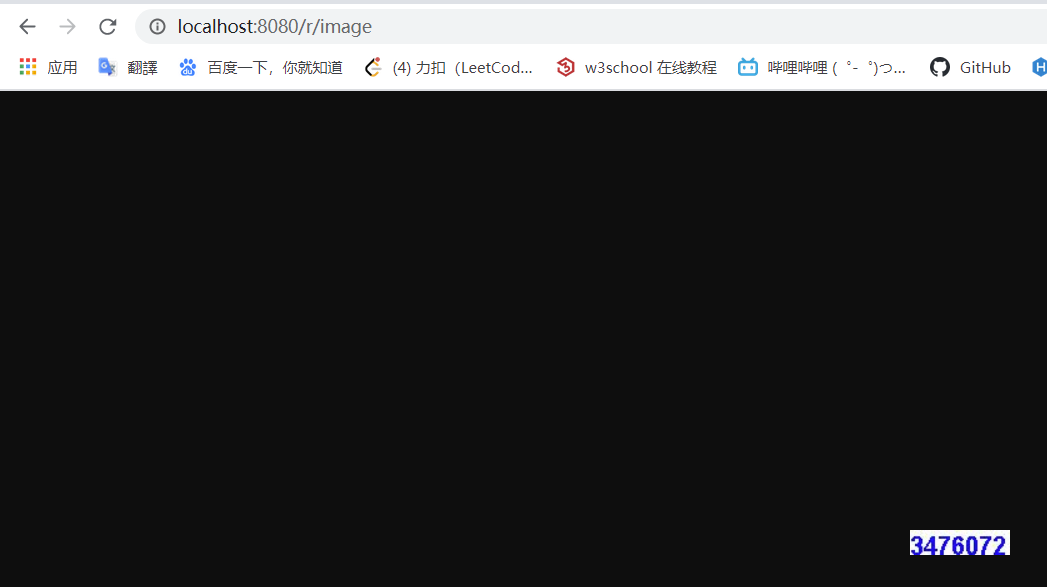
表示成功!
面试常问:请你聊聊转发和重定向之间的异同点
相同点:页面都会发生跳转
不同点:请求转发的时候,url 不会发生变化;307
而重定向的时候,url 会发生变化;302
重定向实现登录:
在 web.xml 中配置映射
1 |
|
在 index.jsp 中写好登录页面(一开始的时候没添加上面两行编码的代码,中文显示的全是乱码 - -)
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> |
写了一个假如成功就跳转到的页面 success.jsp
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
最后,创建一个 Test
1 | public class RequestTest extends HttpServlet { |
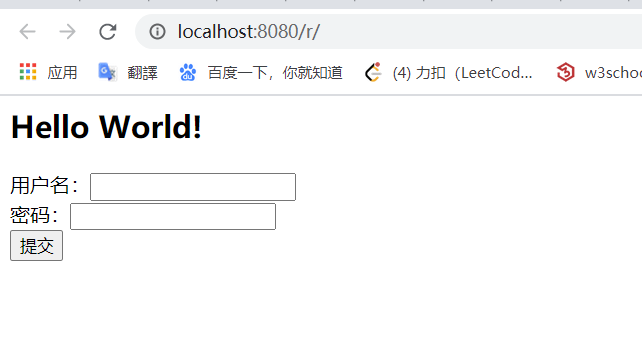
随便输了几个数字 点提交
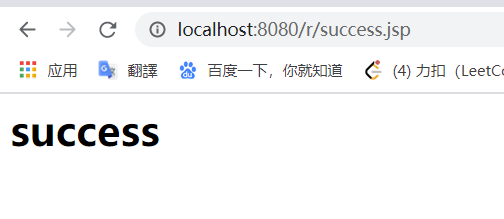
6、7 HttpServletRequest
HttpServletRequest 代表客户端的请求,用户通过 Http 协议访问服务器,Http 请求中的所有信息会被封装到 HttpServletRequest,通过这些 HttpServletRequest 的方法,获得客户端的所有信息;其中这些信息有
获取前端传递的参数,请求转发
老三样,在 web.xml 中配置好映射
1 | <web-app> |
简陋的写了一个登录页面:
1 | <%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> |
写个 LoginServlet
1 | public class LoginServlet extends HttpServlet { |
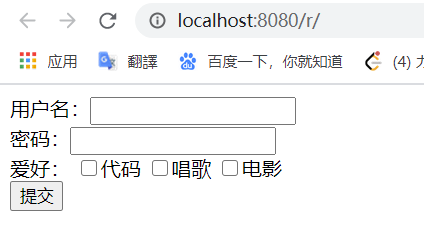
用户名填了 hpg 密码 123
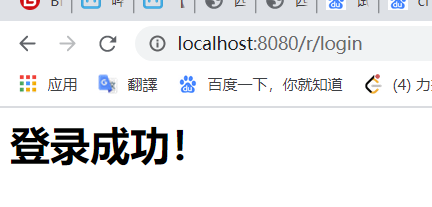
成功!
7、Cookie、Session
7、1 会话
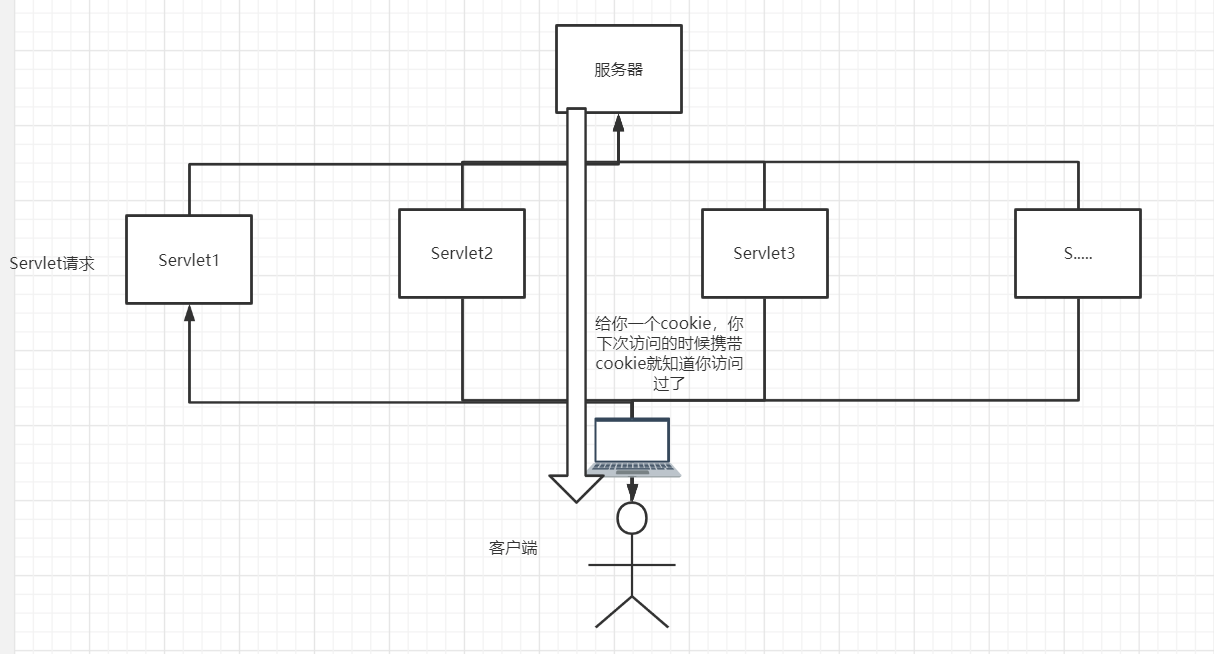
会话:用户打开一个浏览器,点击很多个超链接,访问多个 web 资源关闭浏览器,这个过程我们可以称之为会话。
有状态会话:一位同学曾去过一间教室,再进入这个教室的时候,就知道它曾经来过了,称为有状态会话
下面思考一下这个问题,你怎么证明你是一个学校的学生?
- 学校给你发了录取通知书 —— 学校给你发
- 学校的学生名单上有你的名字 ——学校标记你
那么 一个网站怎么证明你来过呢?客户端——服务器端
- 服务器端给客户端发一个信件,下次客户访问服务器端凭借信件即可,此处的信件 即为 Cookie 相当于录取通知书
- 服务器端登记你,下次客户端来访问的时候进行匹配查找;这项功能即为 Session
7、2 保存会话的两种技术
cookie
- 客户端技术(请求,响应)
session
- 服务器技术,保存用户的信息;通过 Session 保存信息或数据
常见用途:网站登录之后,下次就不用再登录了,可以直接访问
7、3 Cookie
- 从请求中拿到 cookie 信息
- 服务器相应给客户端 cookie
一般会保存在本地的用户目录下 appData 下。
由浏览器保存,不同的浏览器具有不兼容性。
由浏览器主动向服务器提供,服务端只需 getCookies 就行。
一个 cookie 只能保存一个信息
一个 web 站点最多存放 20 个 cookie
cookie 大小限制 4kb
浏览器上限是 300 个 cookie
不设置有效期,关闭浏览器自动失效。
控制台输入javascript:alert (document. cookie)可查看本网站下 cookie
cookie 中的方法:
1 | Cookie[] cookies = req.getCookies();//获得cookie |
编写一个 Servlet 去实现 访问上一次访问事件
1 | public class CookieDemo01 extends HttpServlet { |
配置好 web.xml
1 | <servlet> |
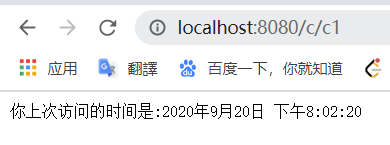
这个注意一下,假如是第一次登录的话,访问时间应该是不显示的,要刷新一次才行;
同时,假如我不设置那个 cookie 有效时间,我只要关闭了浏览器,他就会默认你是第一次访问,但我设置了就不一样了。
7、4 Session(重点)
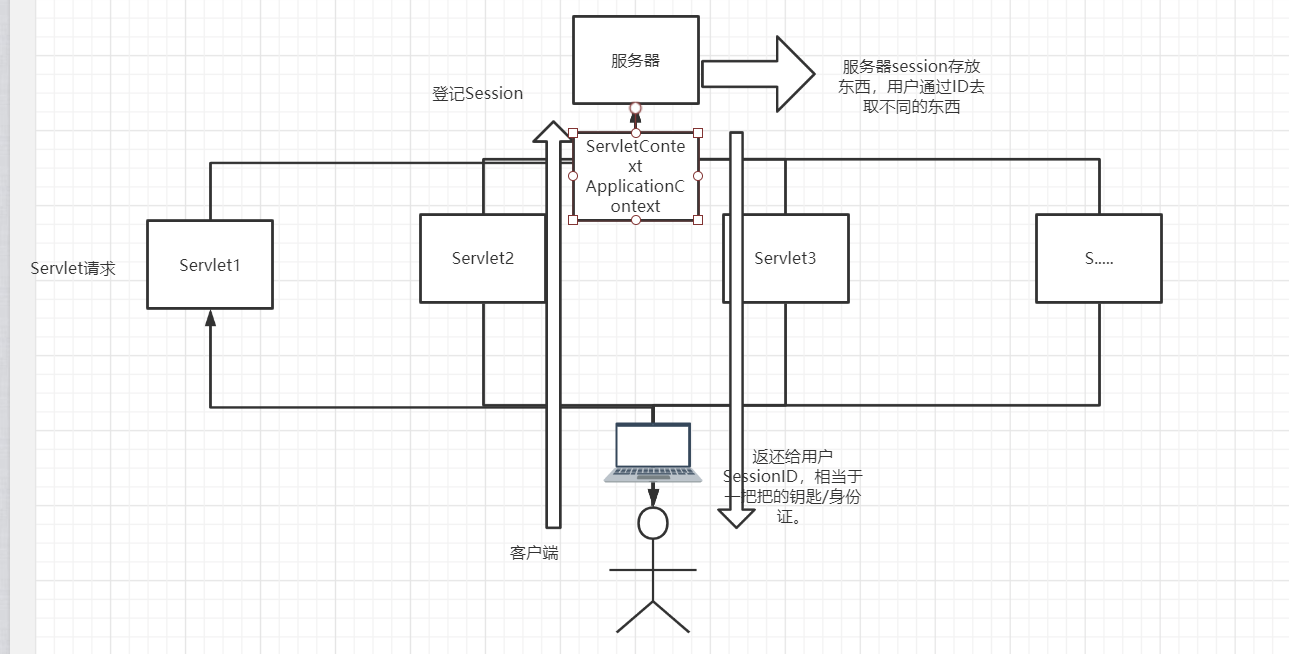
什么是 Session:
服务器给每个用户(浏览器)创建一个 Session 对象
一个 Session 独占一个浏览器,只要浏览器没关闭,这个 Session 就存在
用户登录之后,整个网站他都能访问;常用于保存购物车信息等
Session 与 cookie 的区别:
- Cookie 是把用户的数据写给用户的浏览器 浏览器保存
- Session 是把用户的数据写到用户独占的 Session 中,在服务器端保存(保存重要的信息,减少服务器资源的浪费)
- Session 是由服务器生成的。
web.xml 中配置
1 | <servlet> |
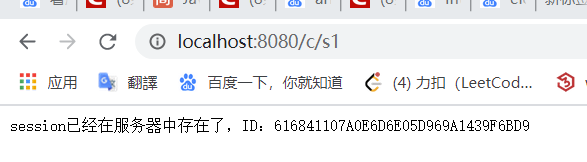
SessionDemo01,测试往 session 里面存东西
1 | public class SessionDemo01 extends HttpServlet { |
再来一个
1 | <servlet> |
再写一个 SessionDemo02,测试从 session 中取东西
1 | public class SessionDemo02 extends HttpServlet { |
第一次访问 s2 时候,打印出来的是 null;
访问完 s1,往 session 里存放数据后再访问一次 s2 得到结果:

- 注销 Session
1 | public class SessionDemo03 extends HttpServlet { |
我们测试一下:一开始用 s1 创建
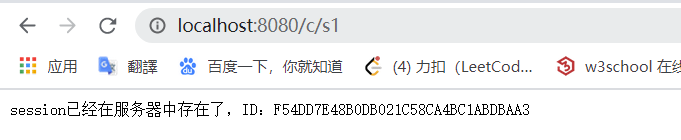
s2 进行打印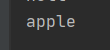
s3 注销
s2 再打印
完成了注销
当然了,我们可以用 web.xml 去配置 让它会话在一定时间后自动过期:
1 | <session-config> |
8、JSP
8、1 什么是 JSP
- JSP 即 java server pages:java 服务器端页面,也和 Servlet 一样用于开发动态 web 技术
- 特点:写 jsp 像在写 html,用标签语言进行,那么与 html 有什么区别呢?
- HTML 只给用户提供静态数据
- JSP 页面中可以嵌入 Java 代码,为用户提供动态数据
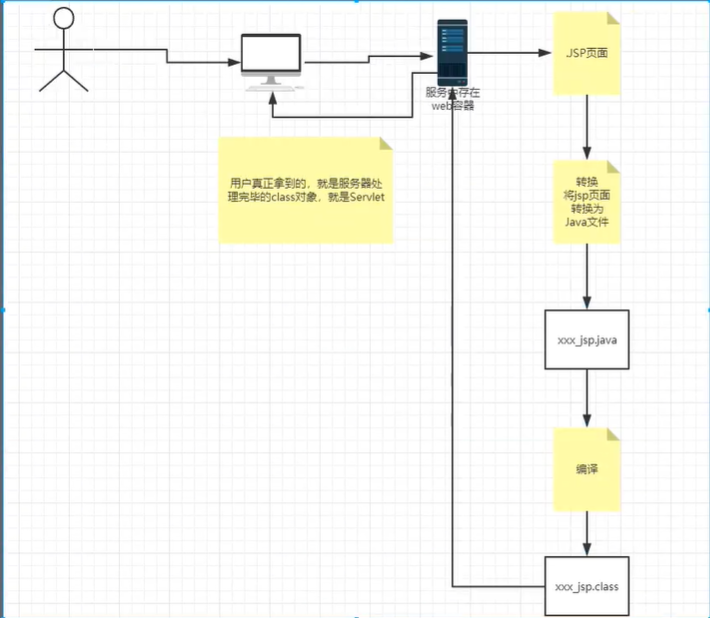
8、2 JSP 原理
思路:jsp 到底是怎么执行的呢?
我们点开此文件夹一直找,直到最后我们进入:
我们发现页面转换成了 java 程序
浏览器向服务器发送请求,不管访问什么资源,其实都在访问 Servlet
那么 JSP 最后也会转成一个 java 类,那么这又是为什么呢?我们点开源码分析下
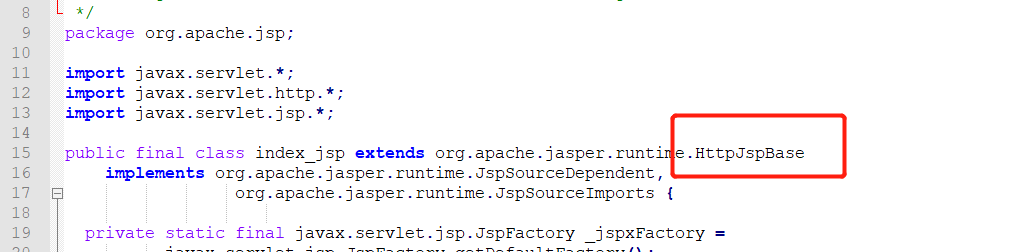
我们再分析这个类,发现它是由 HttpServlet 继承的,而我们前面学习过了,HttpServlet 其实是继承 Servlet 的,因此 JSP 本质上其实就是个 Servlet
我们比对一下源码和 index.jsp,发现我们 index.jsp 中的页面比源码中的要美观很多,它帮我们解决了很多繁琐的事情
1 | //初始化 |
接下来我们看看这个_jspService 都做了什么事情
它做了一些请求判断
1
2
3
4
5
6
7
8
9
10
11
12if (!javax.servlet.DispatcherType.ERROR.equals(request.getDispatcherType())) {
final java.lang.String _jspx_method = request.getMethod();
if ("OPTIONS".equals(_jspx_method)) {
response.setHeader("Allow","GET, HEAD, POST, OPTIONS");
return;
}
if (!"GET".equals(_jspx_method) && !"POST".equals(_jspx_method) && !"HEAD".equals(_jspx_method)) {
response.setHeader("Allow","GET, HEAD, POST, OPTIONS");
response.sendError(HttpServletResponse.SC_METHOD_NOT_ALLOWED, "JSP 只允许 GET、POST 或 HEAD。Jasper 还允许 OPTIONS");
return;
}
}它内置了一些对象
1
2
3
4
5
6
7
8
9
10final javax.servlet.jsp.PageContext pageContext;//页面上下文
javax.servlet.http.HttpSession session = null;//session
final javax.servlet.ServletContext application;//applicationContext
final javax.servlet.ServletConfig config; //config
javax.servlet.jsp.JspWriter out = null; //out
final java.lang.Object page = this; //page:当前页
javax.servlet.jsp.JspWriter _jspx_out = null;
javax.servlet.jsp.PageContext _jspx_page_context = null;
HttpServletRequest request //请求
HttpServletResponse //响应输出页面前增加的代码
1
2
3
4
5
6
7
8response.setContentType("text/html"); //设置响应的页面类型
pageContext = _jspxFactory.getPageContext(this, request, response,null, true, 8192, true);
_jspx_page_context = pageContext;
application = pageContext.getServletContext();
config = pageContext.getServletConfig();
session = pageContext.getSession();
out = pageContext.getOut();
_jspx_out = out;2 和 3 中的对象,代码都能在 jsp 页面中直接使用
- 大致的流程图:
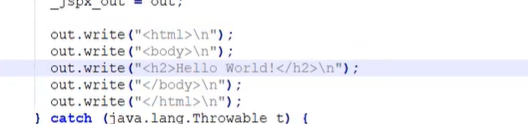
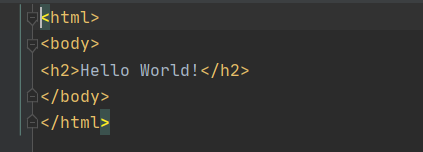
在 jsp 中,如果是 java 代码会原封不动输出,如果是 html 语言或是其他的,会被转换为形如这样的格式,输出到前端:
1 | out.write("<html>\n"); |
9、 JavaBean
实体类:
javabean 别想的太复杂,其实和普通的 java 类没什么区别,只是他必须要带有一些特定的东西。
为什么呢?因为我们后面学到了框架部分,我们就知道,项目是由一个个模块,螺丝,组装起的;
这个时候我们就需要有一种“javabean”的思想去解决问题。
JavaBean 有特定写法
是公有类的 —— public class xxx
必须要有一个无参构造——public class xxxx{}
属性必须私有化 —— private String name;
必须有对应的 getter/setter 方法
一般用来和数据库字段做映射:ORM
ORM:对象关系映射
- 表 → 类
- 字段 → 属性
- 行记录 → 对象
| id | name | age | address |
|---|---|---|---|
| 1 | apple | 14 | 深圳 |
| 2 | pear | 33 | 广州 |
| 3 | peach | 53 | 宜昌 |
1 | class Person { |
我们在数据库中创建了表,表中是由相应的成员属性组成,为什么说是相应的呢,因为我们的 javabean 中的对象应该具有我们数据库中表的属性,也就是形成了一一对应的关系。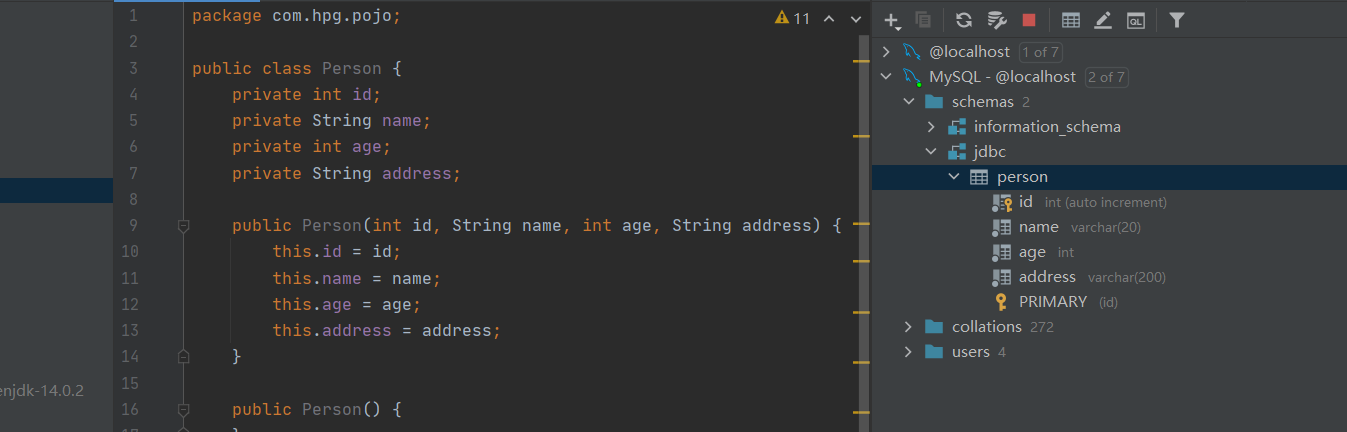
下面我们写一个 javabean 再写一个相应的 jsp 页面感受一下:
Person.java:
1 | public class Person { |
javabean.jsp:
1 | <html> |
输出页面: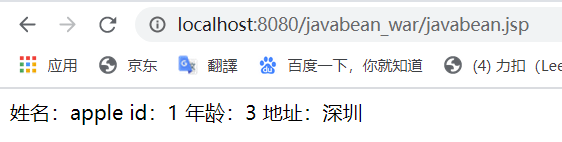
10、 MVC 三层架构
- 什么是 MVC:Model View Controller-模型视图控制器
10、1 早期架构
我们上面学到了其实 Jsp 就是 Servlet,那为什么还要区分这两个呢?
其实是为了方便维护;
Servlet 专注于处理请求以及控制视图跳转;
Jsp 专注于显示数据
早期架构图:
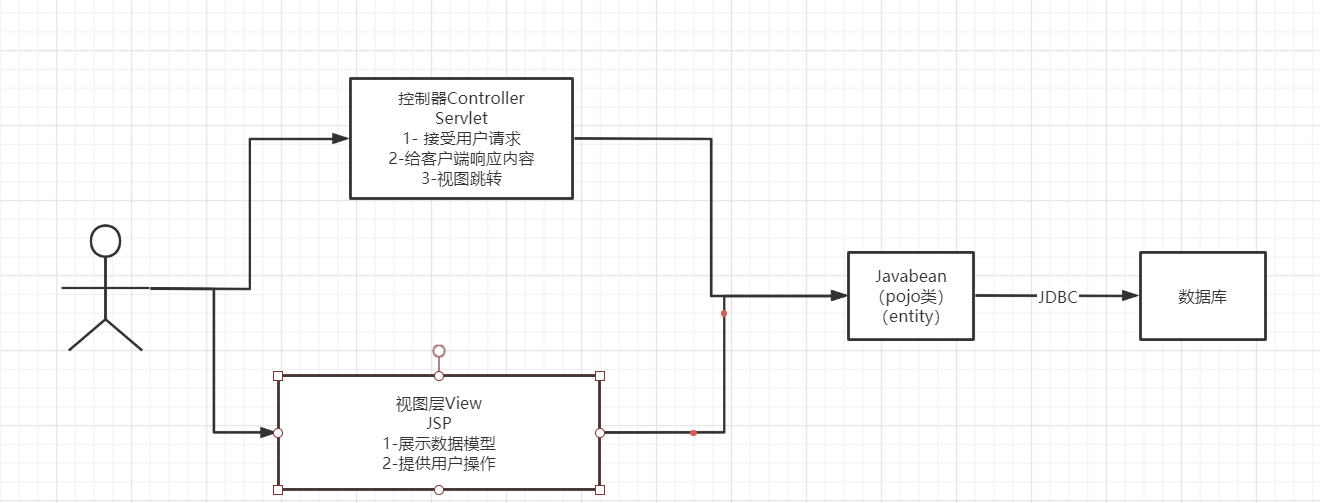
用户直接访问控制层,控制层就可以直接操作数据库
1 | Servlet--CRUD-->数据库 |
10、2 MVC 三层架构
现在的呢?mvc 架构图: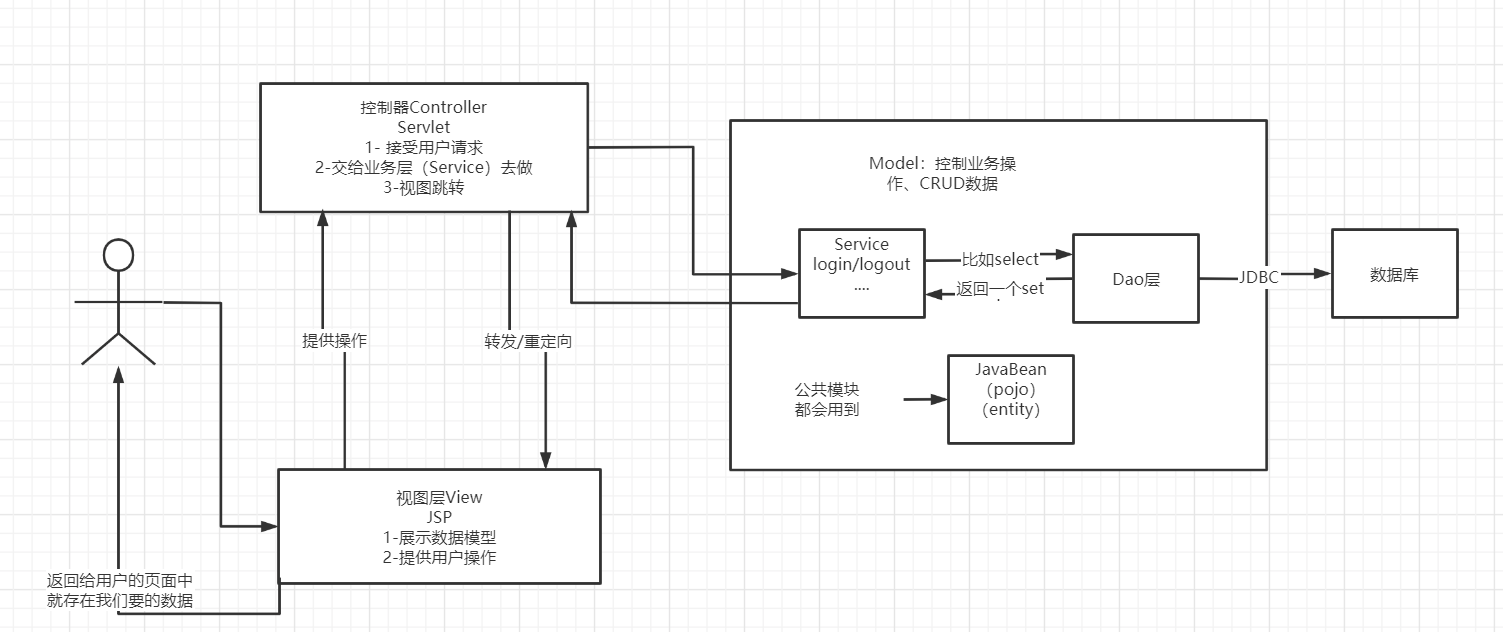
Model
- 业务处理层:业务逻辑(Service)
- 数据持久层:CRUD(Dao)
VIEW
- 展示数据
- 提供链接发起下一步 Servlet 请求/提供用户交互
Controller(Servlet)
接受用户的请求:req:请求参数,session 信息
交给业务层处理对应的代码
控制视图的跳转
1
登录--->接受用户的登录请求--->处理用户的请求(获取用户登录的参数,username,password)--->交给业务层处理登录业务(判断用户名密码的是否正确:事务)--->Dao层查询用户名和密码是否正确--->查询数据库
11、 (重点)Filter 过滤器
11、1 什么是过滤器
Filter:过滤器,用来过滤网站的数据;
- 处理中文乱码
- 登录验证
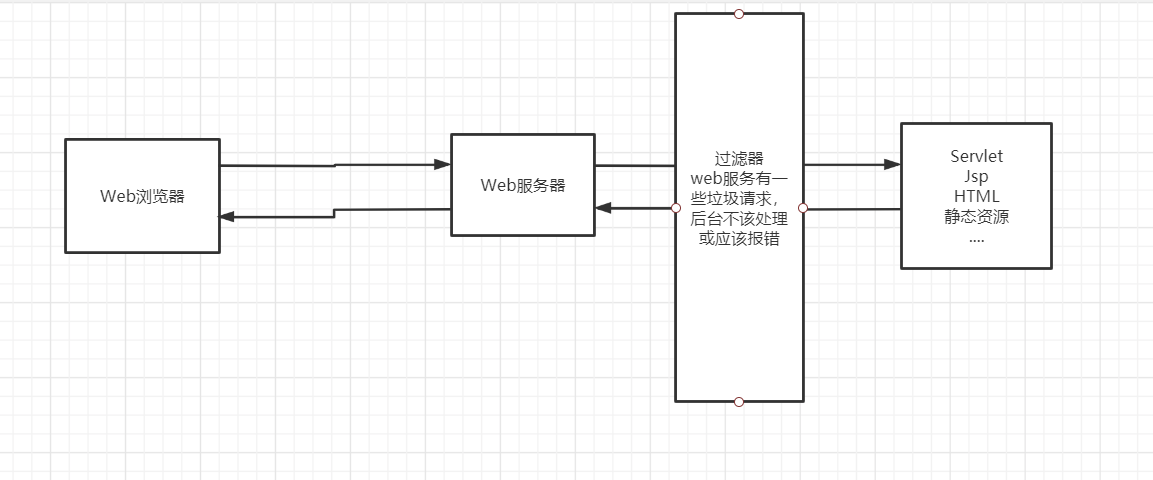
11、2 Filter 开发步骤
- 导包
- 编写过滤器
- 编写 java 类实现 Filter 接口,并实现其 doFilter 方法。
- 在 web.xml 文件中使用
和 元素对编写的 filter 类进行注册,并设置它所能拦截的资源。
注意:导包不能导错:
1 | import javax.servlet.*; |
应用的例子:
编写一个过滤编码的类
1 | package com.hpg.filter; |
测试类:
1 | public class ShowServlet extends HttpServlet { |
配置 web.xml
1 | <servlet> |
一开始走 ShowServlet 的时候
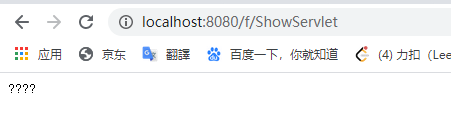
走通过过滤器筛过的路径的时候
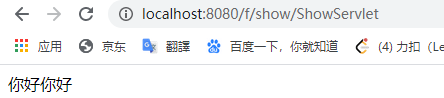
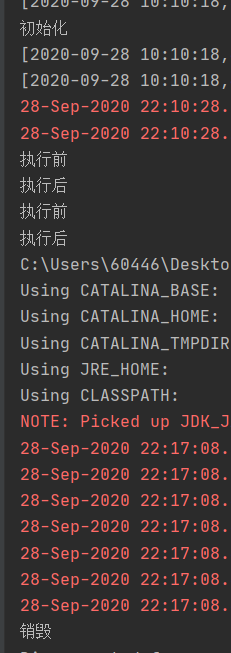
整个生命周期:
启动 Tomcat 就开始初始化了,进一次页面就会执行一次,最后关闭服务器就销毁;
12、监听器 Listener
12、1 什么是监听器
- 监听器就是一个实现特定接口的普通 java 程序,这个程序专门用于监听另一个 java 对象的方法调用或属性改变,当被监听对象发生上述事件后,监听器某个方法将立即被执行。
12、2 监听原理
- 存在事件源
- 提供监听器
- 为事件源注册监听器
- 操作事件源,产生事件对象,将事件对象传递给监听器,并且执行监听器相应监听方法
12、3 应用例子测试
编写一个监听器——实现监听器接口,重写里面的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40public class OnlineCountListener implements HttpSessionListener {
//创建session监听:看你的一举一动,一旦创建session,就会触发一次这事件;
public void sessionCreated(HttpSessionEvent httpSessionEvent) {
//得到上下文
ServletContext ctx = httpSessionEvent.getSession().getServletContext();
System.out.println(httpSessionEvent.getSession().getId());
//在线人数
Integer onlineCount = (Integer) ctx.getAttribute("OnlineCount");
if(onlineCount == null){
//假如没有用户 那么new一个新的用户
onlineCount = new Integer(1);
}else {
//否则加一
int count = onlineCount.intValue();
onlineCount = new Integer(count + 1);
}
ctx.setAttribute("OnlineCount",onlineCount);
}
//销毁session监听
public void sessionDestroyed(HttpSessionEvent httpSessionEvent) {
ServletContext ctx = httpSessionEvent.getSession().getServletContext();
Integer onlineCount = (Integer) ctx.getAttribute("OnlineCount");
if(onlineCount == null){
onlineCount = new Integer(0);
}else{
int count = onlineCount.intValue();
onlineCount = new Integer(count - 1);
}
ctx.setAttribute("OnlineCount", onlineCount);
}
}在 web.xml 中注册监听器
1
2
3
4<!--注册监听器-->
<listener>
<listener-class>com.hpg.listener.OnlineCountListener</listener-class>
</listener>看情况是否使用
chrome 打开
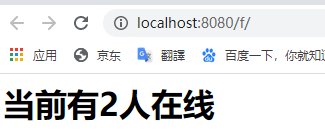
再添加一个 edge 打开:
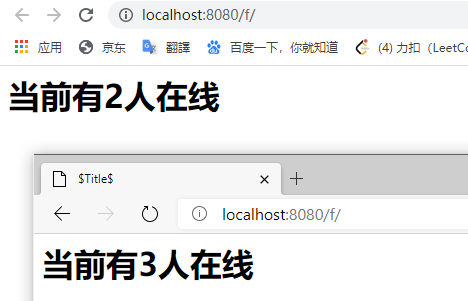
13、 过滤器 监听器 常见应用
13、1 监听器 GUI
- 我们可以创建一个图形化界面去实现监听的效果
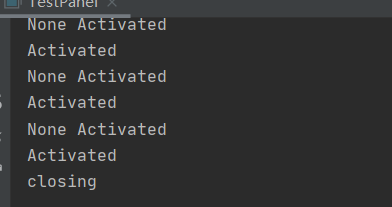
例子:

缩小窗口,打开窗口,关闭窗口 都有不同的表现:
代码:
1 | public class TestPanel { |
13、2 Filter 实现权限拦截
- 用户登录之后才能进入主页,用户注销后不能进入主页;就算你一开始进去过主页了,并且保存了你的成功的网页,但你注销了,如果在 url 中直接复制网址,也不能进去!
如何实现呢?
- 用户登录之后,向 Session 中存放用户的数据
- 进入主页时候判断用户是否已经登录了(可以在 jsp 中实现,但最好最好用过滤器实现!!)
代码:
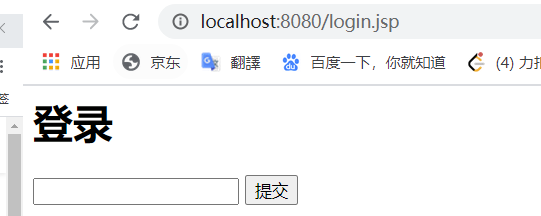
首先 一个登录界面(login.jsp):
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
登录成功后进入的主页面(success.jsp):
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
登录失败的页面(error.jsp):
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
ok,接下来是登录和登出的两个 Servlet
登录(LoginServlet):
1 | public class LoginServlet extends HttpServlet { |
登出(LogOut):
1 | public class LogOut extends HttpServlet { |
同时,为了能够成功实现权限拦截,需要用到 Filter
SysFilter.java(意思是,所有 Sys 下的页面都必须经由这个过滤器筛过才能进入)
1 | public class SysFilter implements Filter { |
最后一步:在 web.xml 好配置好路径映射以及过滤器
一定要注意好我们的 url-pattern 里的路径是要与各自的.jsp 中的相对应
1 | <servlet> |
过滤器:
1 | <!--sys下的页面都会被在这个过滤器筛一遍--> |
登录:
登录失败:
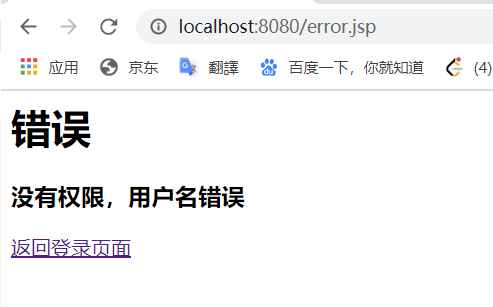
点击返回登录页面就可以重新回到登录主页
登录成功:
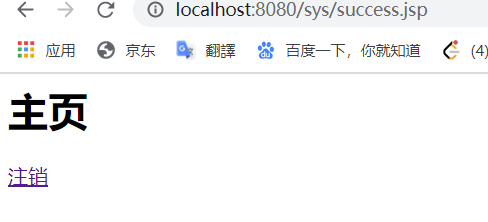
此时,假如我直接保存我们的成功网址,然后点注销,再直接复制网址进入的话:

大功告成!目录结构:
14、 JDBC
- 什么是 JDBC? Java 连接数据库
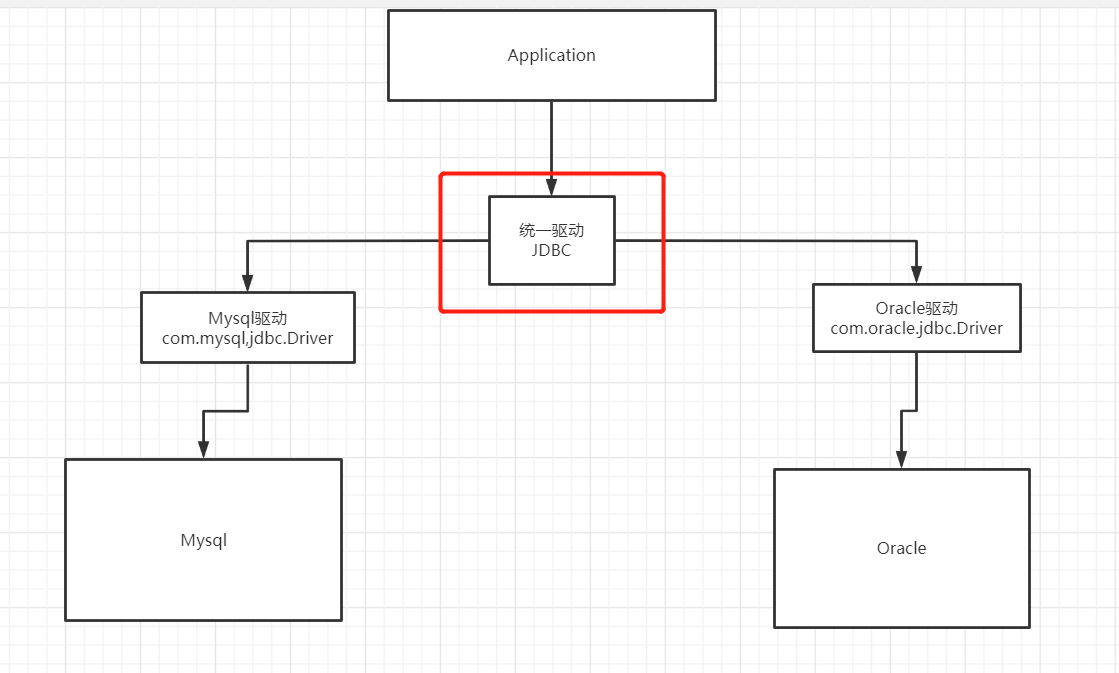
需要 jar 包的支持:
- java.sql
- javax.sql
- mysql-connector-java 连接驱动必须要导入的包
14、1 JDBC 固定步骤
- 加载驱动
- 连接数据库,代表数据库
- 向数据库发送 SQL 的对象 statement 用于 CRUD
- 编写 SQL → 不同业务,不同 SQL
- 执行 SQL
- 关闭连接
应用例子:
下载了 SQLyog 后 在其中创建一个表:JDBC
然后创建表,写数据:
1 | CREATE TABLE users( |
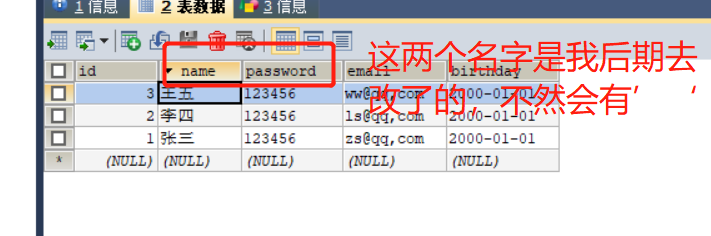
创建出的表:
在 IDEA 中连接好数据库
TestJDBC.java:
1 | public class TestJDBC { |
运行:
插入的 Test:
TestJDBC2.java:
1 | public class TestJDBC2 { |
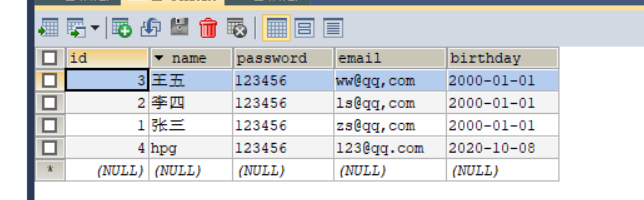
结果:
14、2 JDBC 事务
- 要么都成功,要么都失败
- ACID 原则——保证了数据的安全
- A(原子性):一个事务的所有系列操作步骤被看成一个动作,所有的步骤要么全部完成,要么一个也不会完成。如果在事务过程中发生错误,则会回滚到事务开始前的状态,将要被改变的数据库记录不会被改变。
- C(一致性):一致性是指在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏,即数据库事务不能破坏关系数据的完整性及业务逻辑上的一致性。
- I(隔离性):主要用于实现并发控制,隔离能够确保并发执行的事务按顺序一个接一个地执行。通过隔离,一个未完成事务不会影响另外一个未完成事务。
- D(持久性):一旦一个事务被提交,它应该持久保存,不会因为与其他操作冲突而取消这个事务。
Junit 单元测试
引入依赖 pom.xml:
1 | <!--单元测试--> |
简单测试:
@Test 注解只在方法上有效,只要加了这个注解的方法,就可以直接运行
JDBCTest.java:
1 | import org.junit.Test; |
成果:

JDBC 事务回滚
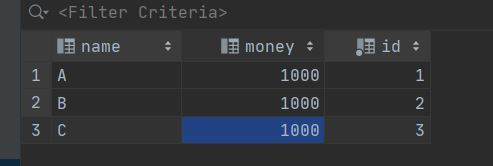
首先在数据库中创建好表:
编写测试类:
JDBCTest3.java:
1 | public class TestJDBC3 { |
假如我的编写错误那行代码不注释掉,执行后的结果是:

表的数据是没有变的
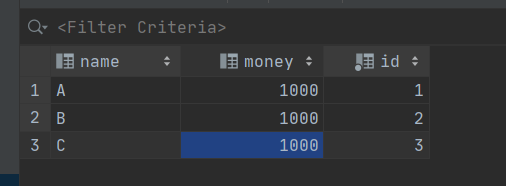
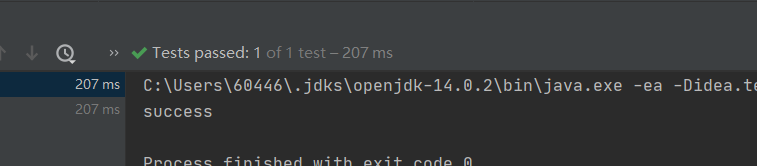
注释掉后:
表的数据改变: